Imagine a world where small businesses no longer feel dwarfed by the technological prowess of industry giants. Picture a landscape where small language models (SLMs) become the unsung heroes that level the playing field for small and medium enterprises (SMEs). It’s not just a distant fantasy; it’s a reality that’s closer than you might think. As we approach 2026, the paradigm shift from large, cumbersome models to nimble, efficient SLMs is set to transform how SMEs operate, innovate, and compete.
If you are a CTO or a founder in 2026, you likely have a line item on your P&L that didn’t exist three years ago. It’s probably labeled “AI API Usage” or “Cloud Compute,” but let’s call it what it really is: The Intelligence Tax.
For the last few years, the tech world has been obsessed with “bigger is better.” We measured progress in trillions of parameters. We treated massive large language models (LLMs) like GPT-4 or Claude 3 Opus as the solution to every single problem, from writing complex code to drafting a simple “Out of Office” email.
In my experience auditing AI stacks for SMEs, I’ve seen this pattern repeat ad nauseam. It is the equivalent of commuting to work in a Formula 1 car. Sure, it gets you there. It’s impressive. But the maintenance is a nightmare, the fuel costs are astronomical, and frankly, it’s overkill for a trip to the grocery store.
The era of blind experimentation is over. 2026 is the year of small language models (SLMs).
This isn’t just about saving a few pennies; it’s about a fundamental shift in architecture. We are moving from general-purpose giants to Agentic AI—autonomous, task-specific, and highly efficient systems. In this guide, I’m going to show you exactly how ditching the “bigger is better” mindset can cut your AI overhead by 90% while actually improving reliability.
I. Introduction — The Ferrari-for-Pizza Problem
Let’s be honest about how most Small and Medium Enterprises (SMEs) are currently using AI.
You might have a customer support chatbot, a document summarizer, or a tool that helps your sales team generate outreach emails. Under the hood, 95% of these applications are making API calls to a frontier model. Every time a user asks, “Where is my order?”, you are firing up a neural network trained on the sum total of human knowledge—Shakespeare, quantum physics, Python code, and French poetry—just to look up a tracking number.
This is the Ferrari-for-Pizza problem.
You are using a vehicle designed for peak performance to deliver a pepperoni pizza. It works, but the unit economics are broken.
The 2026 Shift: Agentic AI
The landscape has shifted. We are no longer just chatting with bots; we are deploying agents.
- 2023-2024: Human-in-the-loop (Chatbots assisting humans).
- 2026: Agentic AI (Autonomous agents performing actions).
For an agent to be viable, it needs to be fast, reliable, and cheap enough to run in loops. If an agent needs to “think” (inference) 50 times to solve a single coding bug, you cannot afford to pay GPT-4 prices for every single thought.
Small language models are the engine of this new agentic world. They are not trying to be general geniuses. They are designed to be specialists—focused on reliability, speed, and ROI. Explore our guide to Agentic AI for the latest automation updates..
II. The Economics of SLMs vs. LLMs (Facts & Figures)
When I speak with CFOs, the conversation inevitably turns to “Why is our Azure/AWS bill doubling every quarter?” The answer usually lies in the difference between the economics of large language models and their smaller counterparts.
Let’s break down the hard numbers.

Training & Fine-tuning Costs
For a long time, the barrier to entry for owning your own model was the training cost.
- Large Language Models (LLMs): To fine-tune a 70B+ parameter model, you are looking at significant infrastructure. You need clusters of H100 GPUs. The cost, including engineering ops and cloud provision, often sits between $50k and $200k per run. If you mess up the dataset? You pay that bill again.
- Small Language Models (SLMs): In contrast, fine-tuning a modern SLM (like a Phi-4 or Llama-3-8B equivalent) using techniques like LoRA (Low-Rank Adaptation) or QLoRA is radically cheaper.
I have helped teams fine-tune high-performing SLMs on commodity hardware (like a dual A6000 setup or even high-end consumer RTX 4090s) for less than $500.
Why does this matter? Experimentation velocity. When training costs $500, you can iterate weekly. When it costs $50k, you iterate quarterly. In AI, speed of iteration is the only competitive advantage that lasts.
Inference & Energy Costs
This is where the “Intelligence Tax” really hits. Training is a one-time cost (CapEx); inference is forever (OpEx).
Every time your user interacts with your AI, you pay for inference.
- Fact: Smaller models require fewer calculations per token generated. A 7B parameter model is roughly 10x cheaper to run than a 70B model, and up to 100x cheaper than a closed-source frontier model via API.
- Energy Efficiency: SLMs consume up to 50x less energy per token.
In 2026, where “Green AI” reporting is becoming mandatory for EU compliance and corporate ESG goals, energy efficiency isn’t just about the bill—it’s about brand reputation. Lowering your cloud bills helps your bottom line; lowering your carbon footprint helps your brand.
III. Privacy & Compliance — The Sovereign AI Advantage
Beyond the money, there is the issue of data sovereignty.
The Risk with Public APIs
When you rely exclusively on OpenAI, Anthropic, or Google APIs, you are sending your data out of your building. For a marketing agency, this might be fine. For a law firm, a healthcare provider, or a fintech startup, this is a massive liability.
- Audit Risks: You cannot fully audit how a black-box model processes your data.
- Vendor Lock-in: If your entire product is a wrapper around a specific API version, and that vendor changes their pricing or deprecates the model, your business breaks overnight.
Why SLMs Win
Small models offer the ability to run “Sovereign AI.” Because these models are compact, they fit onto manageable hardware.
- Hardware Reality: A high-quality 7B parameter model, quantified to 4-bit, takes up less than 8GB of VRAM. You can run this on a modern MacBook Pro or a single gaming GPU.
- Deployment Flexibility: You can deploy these models On-Premise (in your own office server), in a Virtual Private Cloud (VPC), or fully offline on edge devices.
Scenario: I worked with a legal tech firm that needed to summarize sensitive court documents. They couldn’t use ChatGPT due to client confidentiality clauses. We deployed a fine-tuned Mistral-based model inside their own firewall. Result: Zero data leakage. Full GDPR/EU AI Act compliance. And, because it ran on their existing on-prem servers, their marginal cost per summary was effectively electricity.
IV. Practical Implementation — The Teacher–Student Method
You might be thinking: “But small models are stupid. They hallucinate. They can’t reason like GPT-4.”
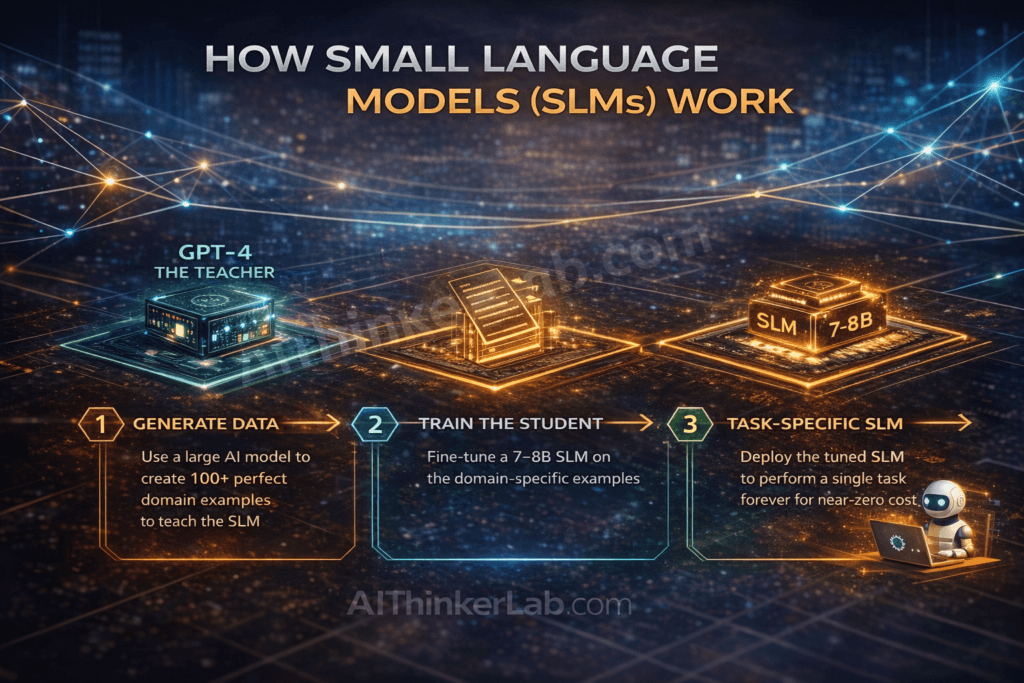
In 2024, that was largely true. In 2026, it’s a misconception. You don’t make a small model smart by training it on the whole internet; you make it smart by using a Teacher-Student architecture (also known as Knowledge Distillation).
Concept Overview
The strategy is simple:
- The Teacher: Use a massive, expensive LLM (like GPT-5 or Claude Opus) to generate high-quality, perfect examples of what you want.
- The Student: Train your small language model on those perfect examples.
The small model doesn’t need to know the capital of Mongolia or how to write a haiku (unless that’s your business). It just needs to learn the specific patterns of your domain.
Real-World Example: The Email Optimizer
Let’s look at a practical case study from a CRM SaaS company I consulted for.
The Problem: They wanted an AI feature to rewrite cold sales emails to be more empathetic. The “Tax” Way: They prompted GPT-4 for every single user request. Cost: ~$0.03 per email. With 100,000 emails a day, that’s $3,000/day.
The “SLM” Way:
- Generate Data: We took 5,000 raw emails and paid GPT-4 to rewrite them perfectly. (One-time cost: ~$150).
- Train: We fine-tuned a small open-source model (Phi series) on those 5,000 pairs of “Bad Email” -> “Good Email.”
- Deploy: We hosted the SLM on a dedicated instance.
The Result: The small model learned the specific “empathy pattern” the company wanted. It performed indistinguishably from GPT-4 for this specific task. New Cost: ~$30/day in server costs. Savings: 99%.
V. Top SLMs to Watch in 2026
The market for smaller models is crowded. If you are looking to adopt, ignore the hype and focus on these three families of models that have defined the 2026 landscape.
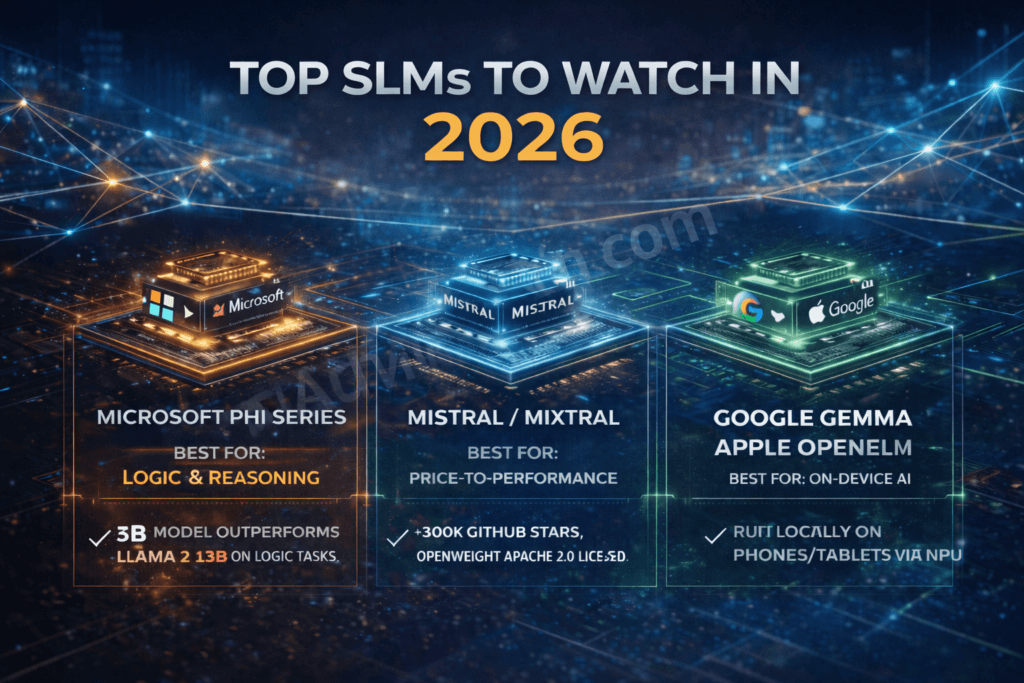
1. Microsoft Phi Series
Microsoft realized early that reasoning doesn’t require massive size if the training data is “textbook quality.”
- Best For: Logic, math, and step-by-step reasoning tasks.
- Use Case: Financial analysis, automated QA testing, complex data extraction.
- Why it wins: It punches way above its weight class. A 3B parameter Phi model often outperforms 13B models from competitors on logic benchmarks.
2. Mistral / Mixtral
The French champion of open-source. Their “Mixture of Experts” (MoE) approach changed the game.
- Best For: General purpose text generation, summarization, and RAG (Retrieval Augmented Generation).
- Use Case: Internal knowledge base chat, customer support ticketing.
- Why it wins: Best price-to-performance ratio. It is highly “steerable” and fine-tunes exceptionally well.
3. Google Gemma / Apple OpenELM
These are models designed with the device in mind.
- Best For: On-device AI, extreme privacy, mobile apps.
- Use Case: Offline translation, personal assistants on tablets/phones.
- Why it wins: If your users are mobile or have poor internet connectivity, these models run locally on the NPU (Neural Processing Unit) of the device. Zero latency. Zero server cost.
VI. Why 2026 Is the Inflection Point
Why is this happening now? Why didn’t we just do this in 2024?
Three forces have collided to make 2026 the year of the SLM.
1. The CFO Mandate
In the early AI boom, boards were happy to approve “Innovation Budgets.” Now, they want “Unit Economics.” CFOs are looking at the cloud bill and asking, “Does this feature actually make money?” SMEs can no longer hide behind “experimentation.” If a feature costs more to run than the subscription revenue it brings in, it gets cut. SLMs are the only way to make the math work for high-volume features.
2. The Latency Ceiling
We have hit the limit of how fast massive models can generate text. Light can only travel so fast; GPUs can only switch memory so quickly. For voice AI and real-time agents, the latency of a massive model (often 500ms – 2s) feels sluggish. SLMs offer “instant” feels (sub-50ms token generation), which is critical for the user experience.+1
3. The Winning Architecture: ” The Router”
The smartest engineering teams aren’t choosing between Large and Small models. They are using both. We call this Semantic Routing.
- User asks a question.
- A tiny, cheap classifier asks: “Is this hard or easy?”
- Easy (80% of queries): Route to the cheap SLM.
- Hard (20% of queries): Route to the expensive LLM.
This architecture ensures you only pay the “Intelligence Tax” when you actually need the genius.
VII. 30-Day SLM Adoption Playbook for SMEs

You are convinced. You want to stop burning cash. How do you actually make the switch? Do not try to boil the ocean. Follow this 30-day sprint.
Week 1: Discovery & Data
- Identify ONE Workflow: Do not try to replace your whole AI stack. Pick one high-volume, repetitive task (e.g., classifying support tickets, extracting data from invoices, writing SEO meta descriptions).
- The “Golden Dataset”: Collect 100-500 examples of perfect inputs and outputs for this task. If you don’t have them, use a large LLM to generate them.
Week 2: Baseline Testing
- Select a Base Model: Download a lightweight model like Phi-4 or Mistral-7B (quantized).
- Zero-Shot Test: Run your Golden Dataset through the base model without any training.
- Measure: Check accuracy, speed, and cost. This is your baseline. You might be surprised—sometimes the base model is already good enough!
Week 3: Optimization (RAG & Fine-Tuning)
- Inject Context: If the model lacks knowledge (e.g., doesn’t know your product list), set up a RAG (Retrieval Augmented Generation) pipeline. This is cheaper than training.
- Fine-Tune (Optional): If the style or format is wrong, perform a LoRA fine-tune using the dataset from Week 1. This should take less than a day of engineering time.
Week 4: Deployment & Routing
- Shadow Mode: Deploy the SLM alongside your current solution. Let it process live traffic, but don’t show the answers to users yet. Compare the SLM answers to your legacy system.
- Rollout: Once accuracy is within 2-3% of the large model, route 10% of traffic to the SLM. Monitor.
- Scale: Ramp up to 100%.
VIII. Conclusion — Efficiency Is the New Moat
The narrative that “the company with the biggest brain wins” is dead. In 2026, the company with the most efficient brain wins.
Giant models are becoming the professors of the AI world—respected, knowledgeable, and used occasionally for deep consultation. But small language models are the workers. They are the interns, the analysts, and the agents that will power the day-to-day operations of the global economy.
For SMEs, this is good news. It means you don’t need a Google-sized budget to compete. You need smart engineering, a focus on data privacy, and the discipline to optimize.
By owning your intelligence and controlling your costs, you build a moat that API-dependent competitors cannot cross.
Are you ready to stop paying the Intelligence Tax?
Next Step: Here is our SLM Cost-Savings Calculator to see exactly how much your business could save by switching to specialized models
AI Token Cost Calculator
Frequently Asked Questions (FAQ)
What qualifies as a “Small Language Model” (SLM)?
While definitions vary, in 2026, an SLM is generally considered a model with fewer than 10 billion parameters (often under 7B). These models are small enough to run on consumer-grade hardware or single GPUs, distinguishing them from Large Language Models which require massive server clusters.
Are SLMs accurate enough for business use?
Yes, but with a caveat: they are accurate for specific tasks. While they may struggle with general trivia compared to GPT-5, an SLM fine-tuned on your specific business data (e.g., legal contracts, medical coding) can actually outperform larger generalist models in that specific domain.
How much can I really save by switching to SLMs?
Most SMEs see inference cost reductions between 80% and 95%. For example, moving a high-volume summarization task from GPT-4 API to a self-hosted Mistral 7B model can drop costs from thousands of dollars a month to a fixed server cost of under $100.
Do I need a team of AI Ph.D.s to use SLMs?
No. The ecosystem has matured significantly. Tools like Hugging Face AutoTrain, Ollama, and various “Model-as-a-Service” platforms allow standard software engineers to deploy and fine-tune smaller models without deep machine learning expertise.
What is the difference between RAG and Fine-Tuning for SLMs?
RAG (Retrieval Augmented Generation) is like giving the model an open textbook to look up answers during the test. Fine-tuning is like sending the model to a semester-long class to learn a skill. For most SMEs, a combination of RAG (for facts) and Fine-tuning (for style/behavior) yields the best results. Learn more in our GraphRAG vs RAG ultimate guide.