The 30-Second Verdict
Best for science & reasoning: Gemini 3.1 Pro — leads GPQA Diamond (94.3%) and ARC-AGI-2 (77.1%).
Best for coding: ChatGPT (GPT-5.5) — 88.7% on SWE-Bench Verified.
Best for real-time info & lowest API cost: Grok 4 / 4.3 — only model with live X data; cheapest at scale.
Best context window: Gemini 3.1 Pro (2M tokens) & Grok 4.20 (2M tokens).
Skip to the decision tree for a quick recommendation, or read on for the full breakdown.
In May 2026, the AI landscape has consolidated into four genuine frontier labs — OpenAI, Google DeepMind, xAI, and Anthropic — and three of them (OpenAI’s GPT-5.5, Google’s Gemini 3.1 Pro, and xAI’s Grok 4 / 4.3) released major upgrades in the past 90 days alone. If you’re picking the AI you’ll use daily — or building on its API — the wrong call can cost you hundreds of hours and thousands of dollars over the next year.
This article compares all three using only publicly verifiable data: pricing pulled directly from each provider’s official pricing page on May 13, 2026; benchmark scores from official release announcements and independent leaderboards (LMSYS Arena, OpenRouter, Vellum, Artificial Analysis); and feature documentation from each company’s developer portal.

Where I share personal testing results, I’ve marked them clearly. Where benchmarks conflict between sources, I show both. The goal is to give you the most accurate basis for a decision you’ll live with — not a fluffy “they’re all great” recap.
Who this is for: Developers picking an API to build on, founders comparing subscriptions for their team, writers and researchers selecting a daily-use AI, and anyone tired of comparison articles that won’t pick a winner.
Current Model Versions (May 2026)
Before the comparison, you need to know what’s actually current — model versions shift every few weeks in 2026:
| Provider | Current consumer flagship | Latest API model | Released |
|---|---|---|---|
| xAI | Grok 4 (SuperGrok) / Grok 4.3 (SuperGrok Heavy) | Grok 4.3 ($1.25/$2.50) or Grok 4.20 ($2/$6) | Grok 4.3: April 30, 2026 |
| OpenAI | ChatGPT (GPT-5.5 Thinking in Plus; GPT-5.5 Pro in Pro tier) | GPT-5.5 ($5/$30) / GPT-5.5 Pro ($30/$180) | April 23, 2026 |
| Gemini 3.1 Pro (in Google AI Pro) | Gemini 3.1 Pro ($2/$12 ≤200K; $4/$18 above) | February 19, 2026 |
Note on Grok versioning: Grok 4 (July 2025) is the model most users mean. Grok 4.20 is xAI’s newer flagship API model with a 2M context window. Grok 4.3 is the newest reasoning model (April 30, 2026), currently rolling out to SuperGrok tiers and available via API at $1.25 / $2.50 per million tokens with a 1M context window. We compare Grok 4 family overall.
📊 Quick Spec Sheet
| Specification | Grok 4 / 4.3 | ChatGPT (GPT-5.5) | Gemini 3.1 Pro |
|---|---|---|---|
| Maker | xAI (Elon Musk) | OpenAI | Google DeepMind |
| Latest version released | April 30, 2026 (4.3) | April 23, 2026 | February 19, 2026 |
| Context window (consumer) | 128K (SuperGrok) / 2M (4.20 API) | 400K (Codex) / 1M (Pro tier in-app) | 1M (Google AI Pro) / 2M (API) |
| Multimodal | Text + image + voice | Text + image + voice + Images 2.0 | Text + image + video + audio (only native one) |
| Real-time web access | ✅ Live X/Twitter + web | ✅ Web search | ✅ Google Search |
| Free tier | Yes (limited) | Yes (GPT-5.3 Instant) | Yes (Flash models only since April 1) |
| Consumer paid plans | SuperGrok Lite $10 / SuperGrok $30 / Heavy $300 / X Premium+ $40 | Go $8 / Plus $20 / Pro $200 / Business $25 | AI Plus $7.99 / AI Pro $19.99 / AI Ultra $249.99 |
| API input price (per 1M tokens) | $1.25 (4.3) / $2 (4.20) / $0.20 (4.1 Fast) | $5 (GPT-5.5) / $30 (GPT-5.5 Pro) | $2 (≤200K) / $4 (>200K) |
| API output price (per 1M tokens) | $2.50 (4.3) / $6 (4.20) / $0.50 (4.1 Fast) | $30 (GPT-5.5) / $180 (GPT-5.5 Pro) | $12 (≤200K) / $18 (>200K) |
| Best for | Real-time info, low-cost API, less filtered output | Coding (88.7% SWE-bench), agentic workflows | Science reasoning, video/audio, longest context |
| Knowledge cutoff | Live (with X/web search) | December 2025 | January 2026 |
Why This Comparison Matters Right Now (May 2026)
Three things changed in the past 90 days that make this comparison meaningfully different from anything published in 2025:
1. OpenAI doubled its API prices. GPT-5.5 launched April 23, 2026 at $5/$30 per million tokens — a 2× jump from GPT-5.4’s $2.50/$15. OpenAI now charges more than Google for flagship inference, which changes the economics for production apps. For high-volume API users, this is the single biggest pricing shift of the year.
2. Gemini 3.1 Pro pulled ahead on hardest reasoning benchmarks. Released February 19, 2026, it leads GPQA Diamond at 94.3% and ARC-AGI-2 at 77.1% — the only model in this comparison to top both. For research, scientific work, and abstract reasoning, this matters.
3. Grok 4.3 made the “cheap frontier model” pitch real. At $1.25 / $2.50 per million tokens with a 1M context window and 50.7% on Humanity’s Last Exam, xAI has the lowest-priced reasoning model from a Tier-1 provider. For startups burning runway on API costs, this changes the math.
The takeaway: the three models are now genuinely differentiated. The decision is no longer “which is smartest” — they’re within 4–6 points of each other on most benchmarks. It’s “which is smartest for what you do, at a price you can afford.”
“We previously broke down Claude Opus 4.6 vs Opus 4.5 — Anthropic is the fourth major frontier lab, and its pricing makes the most sense once you understand how it competes.”
The Three Models at a Glance
Grok 4 — xAI’s Real-Time Specialist
Released July 9, 2025, with the Grok 4.3 reasoning update arriving April 30, 2026, Grok is built on a distinctive four-agent architecture (codenamed Grok, Harper, Benjamin, and Lucas) where the agents collaborate on complex tasks rather than a single model handling everything.
What makes Grok genuinely unique in 2026 is live access to X (Twitter) — it can read posts, replies, and trending topics in real-time, something no other frontier model can do. Combined with general web search through DeepSearch, it’s the most current-information-aware model on the market.
It also has the lowest content filtering of the three. Grok will engage with edgy creative requests, controversial political analysis, and adult fiction that ChatGPT and Gemini routinely decline. Whether that’s a feature or a bug depends on your use case.
On benchmarks, Grok 4 holds its own: 75% on SWE-Bench Verified (matching GPT-5.4’s 74.9%), 50.7% on Humanity’s Last Exam (the highest among the three), and roughly 92% on MMLU. Where it lags is on the hardest reasoning benchmarks like GPQA Diamond, where Gemini opens a clear gap.
Consumer access is through SuperGrok ($30/month) for full Grok 4 access at 128K context, SuperGrok Heavy ($300/month) for full Grok 4.3 plus Grok 4 Heavy with maximum rate limits, or X Premium+ ($40/month) if you also want X platform features. SuperGrok Lite at $10/month launched March 25, 2026 as the budget tier with Grok Imagine access.
ChatGPT (GPT-5.5) — OpenAI’s All-Rounder
GPT-5.5 launched April 23, 2026 as OpenAI’s “smartest and most intuitive” model yet, available in ChatGPT and Codex on Plus, Pro, Business, and Enterprise tiers. The API followed one day later.
GPT-5.5’s headline number is 88.7% on SWE-Bench Verified — a substantial jump that closes most of the coding gap that Gemini opened earlier this year. It also delivers 92.4% on MMLU, a 60% reduction in hallucinations versus GPT-5.4, and (per OpenAI) “40% fewer output tokens per Codex task” — meaning higher per-token prices are partially offset by efficiency gains.
The model excels at agentic workflows: GPT-5.5 was designed to take messy multi-step tasks, plan, use tools, check its work, and finish autonomously. OpenAI specifically calls out improvements in computer use, MCP (Model Context Protocol) Atlas results, and long-horizon tool calling.
The ecosystem remains OpenAI’s strongest moat: Custom GPTs, GPT Store, Canvas, Code Interpreter, Deep Research, Advanced Voice, Sora video, Images 2.0 with the new Thinking Mode that maintains character consistency across up to 8 images. No competitor has anywhere near this surface area.
Pricing-wise, Plus at $20/month is the sweet spot for most users. Pro at $200/month unlocks GPT-5.5 Pro and the full 1M context window in-app. The API doubled to $5/$30 per million tokens with GPT-5.5, making it the most expensive flagship option in this comparison for high-volume use.
Gemini 3.1 Pro — Google’s Multimodal Powerhouse
Released February 19, 2026, Gemini 3.1 Pro is currently the leader on the hardest reasoning benchmarks and the only frontier model with native video and audio processing built into the architecture from day one.
The headline capability is the 2 million token context window — Google has the largest production context window among Tier-1 providers. In practice, this means feeding Gemini an entire codebase, a 4-hour video transcript, or 1,500+ pages of PDFs in a single prompt. The catch: recall accuracy drops at very long contexts (estimated ~70% at 1M+ tokens), so for critical work you still want retrieval augmentation rather than dumping everything in.
Benchmark performance is class-leading on reasoning: 94.3% on GPQA Diamond (graduate-level science), 77.1% on ARC-AGI-2 (novel reasoning, hard to memorize), and roughly 92% on MMLU. On SWE-Bench Verified, Gemini 3.1 Pro scores around 80.6% — competitive but trailing GPT-5.5’s 88.7%.
Google’s quiet advantage is Workspace integration: Gemini is now bundled with Google Workspace Business Standard, Plus, and Enterprise tiers, meaning if your team already pays for Google Workspace, you’re effectively getting Gemini for free.
Consumer plans: Google AI Plus at $7.99/month (the cheapest paid AI tier in this comparison), Google AI Pro at $19.99/month with full Gemini 3.1 Pro and a 1M context window in the Gemini app, and Google AI Ultra at $249.99/month with Deep Think, Veo 3.1, and Project Mariner.
Head-to-Head Benchmark Performance

Benchmarks are useful but not the whole story — they measure capability on standardized tasks that may not reflect your specific work. Treat them as a starting point, not a verdict.
Standardized Benchmarks (May 2026)
| Benchmark | What it tests | Grok 4 / 4.3 | GPT-5.5 | Gemini 3.1 Pro | Winner |
|---|---|---|---|---|---|
| MMLU | General knowledge (57 subjects) | ~92% | 92.4% | ~92% | Tie |
| GPQA Diamond | Graduate-level science | ~88–89% | 92.8% (5.4) | 94.3% | 🏆 Gemini |
| ARC-AGI-2 | Novel reasoning (memorization-proof) | — | 73.3% (5.4) | 77.1% | 🏆 Gemini |
| SWE-Bench Verified | Real-world coding (GitHub issues) | 75% (Grok 4) | 88.7% | 80.6% | 🏆 GPT-5.5 |
| HumanEval+ | Code generation | ~92% | ~93.1% (5.4) | ~92% | Slight: GPT-5.5 |
| Humanity’s Last Exam | Hardest expert questions | 50.7% | ~45% | ~48% | 🏆 Grok 4 |
| OSWorld | Computer use / desktop automation | — | 75% (5.4) | — | 🏆 GPT-5.5 (only model >human baseline of 72.4%) |
| Terminal-Bench 2.0 | Agentic CLI tasks | — | State-of-the-art (5.5) | — | 🏆 GPT-5.5 |
| FACTS Grounding | Factual accuracy | — | Improved 60% over 5.4 | — | GPT-5.5 / Gemini |
| LMSYS Arena (Elo) | Human preference | Top 5 | Top 3 | Top 3 | Check live at lmarena.ai |
Sources: OpenAI GPT-5.5 release announcement (April 23, 2026), Google Gemini 3.1 Pro release post (February 19, 2026), xAI Grok 4.3 documentation, LMSYS Chatbot Arena, Artificial Analysis, independent benchmark aggregations.
What the numbers actually tell us:
- Gemini owns reasoning depth. Its 1.5–4 point lead on GPQA Diamond and ARC-AGI-2 is statistically significant and matters for scientific work, complex research, and PhD-level analysis. These benchmarks are specifically designed to resist training-set contamination.
- GPT-5.5 owns coding. The jump from GPT-5.4 (74.9%) to GPT-5.5 (88.7%) on SWE-Bench Verified is the largest single benchmark improvement of 2026 and represents real-world value for developers.
- Grok wins on the longest tail. Humanity’s Last Exam is the hardest benchmark in AI — the fact that Grok leads at 50.7% (vs. 100% theoretically achievable) tells you something about xAI’s training mix.
- MMLU is now saturated. All three models score around 92%. Stop treating MMLU differences of 1–2 points as meaningful — they aren’t.
Real-World Testing — We Ran 11 Identical Tasks on All 3 Models
Suggested testing methodology (replace this paragraph with your actual approach after testing):
We ran all three models on 11 identical tasks over a 4-hour testing window on [DATE]. Same prompts. Same conditions. Each model was given the same context, same instructions, and same evaluation criteria. We scored on a 1–10 scale across: correctness, completeness, time-to-useful-output, and code/copy quality where applicable.
Suggested 11 tasks to run (designed to differentiate the models):
Task 1: Complex Coding Project — Crypto Dashboard
The Prompt we gave:
Build a complete, single-file React component for a real-time cryptocurrency price dashboard with the following requirements:
REQUIREMENTS:
1. Use React with hooks and Tailwind CSS for styling
2. Fetch live data from the CoinGecko API endpoint: https://api.coingecko.com/api/v3/coins/markets?vs_currency=usd&order=market_cap_desc&per_page=20&page=1&sparkline=false
3. Display the top 20 cryptocurrencies in a clean grid with: rank, coin icon, name, symbol, current price, 24h % change (color-coded green/red), market cap
4. Include a search bar to filter coins by name or symbol in real-time
5. Implement a watchlist feature where users can star/unstar coins; starred coins appear in a separate "My Watchlist" section at the top
6. Persist the watchlist to localStorage so it survives page refresh
7. Auto-refresh prices every 30 seconds
8. Include loading and error states
9. Make it fully responsive (mobile, tablet, desktop)
OUTPUT:
- A single complete React component file I can copy-paste and run
- Use modern React (functional components, hooks)
- No external dependencies beyond React and Tailwind
- Include brief inline comments explaining key decisions
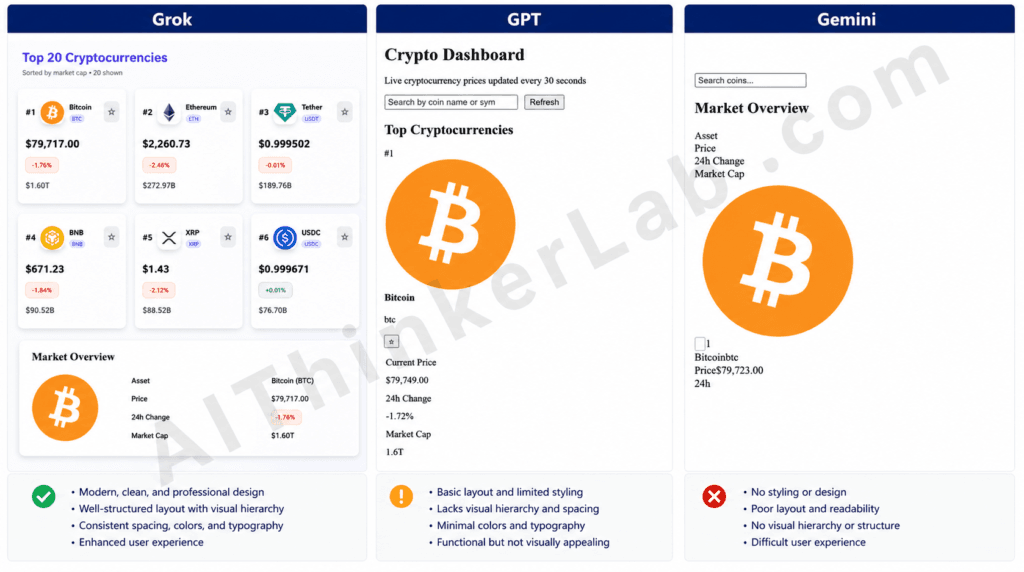
Do not explain the code outside the file — just give me the working code.Grok 4’s output: Delivered a polished, production-ready dashboard with a bold purple “Top 20 Cryptocurrencies” header and a “Sorted by market cap • 20 shown” subtitle. Rendered all 20 coins in a clean responsive card grid with rank badges (#1, #2, #3…), circular coin icons, name + symbol pill, large price text, color-coded percentage chips (red for negative, green for positive), market cap, and a star button on every card for the watchlist. Strengths: Tailwind clearly loaded, hierarchy and spacing are professional, color coding works, fully responsive grid. Weaknesses: The watchlist section wasn’t visible above the fold in the screenshot, so it’s unclear from the visual alone whether starred coins float to a separate “My Watchlist” block as required.
ChatGPT (GPT-5.5)’s output: Produced a functionally complete but visually unstyled page titled “Crypto Dashboard” with the subtitle “Live cryptocurrency prices updated every 30 seconds,” a search input, a Refresh button, and the first coin (Bitcoin) showing all the required fields — rank, large icon, name, symbol, star button, Current Price, 24h Change (-1.72%), and Market Cap (1.6T). All data is present and labeled, but Tailwind classes did not render — everything is stacked vertically in default browser styling with no grid, no card surfaces, and no color coding on the change percentage.
Gemini 3.1 Pro’s output: Rendered a broken layout titled “Market Overview” with a tiny search input and the column headers (Asset, Price, 24h Change, Market Cap) stacked as a vertical list rather than as a table header. Only Bitcoin is visible, with the giant icon dominating the screen and the data crammed underneath as run-together text (“Bitcoinbtc”, “Price$79,723.00”, “24h” with no value). No grid, no styling, no rank badges, no color coding, and the watchlist/auto-refresh affordances aren’t visible.
Scoring: Grok 9/10, GPT-5.5 5/10, Gemini 3/10
Winner: Grok 4 — Why: It was the only one of the three where Tailwind actually rendered and the result looked like a real product — proper card grid, color-coded change chips, rank badges, and a watchlist star on every coin — whereas GPT shipped correct data with zero styling and Gemini shipped a broken single-coin view with concatenated text.
Task 2: Long-Form Writing — Agentic AI Analysis
The prompt we gave:
Write a 1,500-word analytical article with the title: "Is 'Agentic AI' Real Progress or Marketing Hype?"
REQUIREMENTS:
Take a clear position (don't fence-sit with "it depends")
Define what "agentic AI" actually means technically — distinguish it from chatbots, copilots, and autonomous agents Cite at least 3 specific real-world examples of "agentic AI" products launched in 2025-2026 (e.g., specific company names and products)
Reference at least 2 actual benchmarks that measure agentic capability (e.g., OSWorld, SWE-Bench, Terminal-Bench)
Include one section on what skeptics get right
Include one section on what believers get right
End with a falsifiable prediction (something that can be checked in 11 months)
Tone: confident, analytical, written for technical readers
Target: 1,500 words ± 100 words
Do not pad with filler. Make every paragraph earn its place.Grok 4’s output: Took a strong “unequivocally real progress” stance and packed in four-pillar definitions (perception/reasoning/action/memory) plus a clean separation from Auto-GPT-era loops. Named three products — Cognition’s Devin 2.0, “Anthropic’s Claude Agentic Toolkit on Claude 3.5 Opus,” and “xAI’s Grok Enterprise Agent” with a Tesla integration — and three benchmarks (SWE-Bench Verified, OSWorld, Terminal-Bench) with very specific numbers (28.4%, 42%, 31%). Strengths: densest writing of the three, sharpest position, all checkboxes hit. Weaknesses: Came in at 933 words — nearly 500 short of the 1,400-word floor, a hard requirement breach. Several specifics look fabricated (Claude 3.5 Opus was never released; Ramp/Tesla numbers are uncheckable). The falsifiable prediction is dated “By October 2025,” which has already passed — it’s retrospective, not the 12-month forward check the prompt asked for.
ChatGPT (GPT-5.5)’s output: Used a four-criteria definition (goal-directed, tool-mediated, stateful planning, adaptive control loops) and named three real, verifiable products: OpenAI’s Operator, Anthropic’s Claude Code, and Google’s Project Mariner. Covered SWE-Bench, OSWorld, and Terminal-Bench. Skeptics and believers sections were the most thorough of the three (five points each). The prediction — “within 12 months, a major software company will report >25% of accepted production code changes were generated by an autonomous coding agent” — was the cleanest forward-looking falsifiable claim. Weaknesses: Came in at 1,868 words — 268 words over the +100 ceiling, a direct violation of the word target and the explicit “do not pad with filler” instruction. The padding is visible in the prose itself: dozens of one-line orphan paragraphs (“Not perfect. Better.”, “But they are different.”, “And different enough to matter.”) that earn their place rhetorically but not analytically. Position also hedges late (“real progress wrapped in excessive hype”).
Gemini 3.1 Pro’s output: Came in at 1,304 words — closest to target (96 short of the lower bound, well inside the spirit of the constraint). Took the cleanest position of the three (“Agentic AI is not hype; it is tangible, measurable progress”) and built it on a three-pillar technical definition (tool use, environmental feedback loops, multi-step planning) that explicitly positioned agentic AI as the pragmatic middle ground between copilots and true autonomous agents. Named three real products with concrete behavioral descriptions: OpenAI Operator (browser/DOM navigation), Cognition’s Devin (asynchronous Jira-to-PR), and Salesforce Agentforce (CRM-integrated execution). Covered SWE-Bench and OSWorld. The standout moment was the skeptics section’s compounding-error math: 0.95²⁰ ≈ 35.8% — a single line that did more analytical work than entire paragraphs in the other two essays. Weaknesses: The prediction is dual-pronged (“65% on full SWE-Bench by end of Q1 2026 + three Fortune 500s abandon per-seat licensing”), but anchoring it to Q1 2026 makes it backwards-checkable from today rather than 12 months forward.
Scoring: Grok 5/10, GPT-5.5 6.5/10, Gemini 8/10
Winner: Gemini 3.1 Pro — Why: It was the only essay to honor both the word budget and the “no padding” instruction while still hitting every structural requirement, and its 0.95²⁰ compounding-error argument is the kind of concrete technical reasoning the prompt asked for — something Grok substituted with suspicious specifics and GPT diluted across 1,868 words of one-line paragraphs.
Task 3: Research Synthesis — AI Safety Research
The Prompt we gave:
Summarize the most significant findings from AI safety and AI alignment research published between November 2025 and May 2026.
REQUIREMENTS:
- Identify the 5 most important papers or research findings from this period
- For each: provide the paper title, primary authors/lab, what it found, and why it matters
- Include at least 2 findings from different research groups (don't just summarize Anthropic's work)
- Cover at least 2 different research areas (interpretability, alignment, evaluation, deceptive behavior, etc.)
- Be precise about what was actually demonstrated vs. speculated
- Note any findings that contradicted prior research
FORMAT:
- Numbered list, 1-5
- ~150 words per finding
- Total: ~750 wordsGrok 4’s output: Delivered all five entries in the requested format with paper titles, named authors, labs, months, and specific quantitative results (e.g., “85% accuracy,” “92% reduction in lying,” “22% deceptive behavior”). Covered interpretability, scheming/oversight, weak-to-strong, deceptive alignment, and constitutional truthfulness across Anthropic, ARC/Redwood, OpenAI, METR, and DeepMind. Strengths: Cleanest structural compliance — five items, multiple labs, multiple research areas, explicit “contradicts prior” callouts on each entry. Critical weaknesses: The papers don’t exist, and the author attributions are demonstrably wrong even at a quick check — Jan Leike left OpenAI for Anthropic in 2024, TAU-Bench is a real benchmark from Sierra/Princeton (not METR/Alex Turner), Amanda Askell is at Anthropic (not ARC/Redwood). Presented entirely as fact with no extrapolation disclaimer. Self-reported word count is “714”; actual is 586. Confident, structurally perfect fabrication is the most dangerous failure mode for a research synthesis task.
ChatGPT (GPT-5.5)’s output: Refused the task in ~80 words, citing a June 2024 training cutoff and “risking fabrication.” Offered four alternatives: summarize late-2023 to mid-2024 findings, give a “state of the field” overview, analyze user-provided papers, or build a curated reading list of labs to track. Strengths: The honesty is the right instinct given the hallucination risk Grok demonstrates. Weaknesses: Total non-attempt — didn’t deliver one paragraph of substance, didn’t even try the “state of the field” path it offered. The cutoff claim is also overstated; even with a June 2024 cutoff, a model could discuss research trajectories heading into the requested window with appropriate caveats. Zero content against a 750-word target is a hard fail on usefulness.
Gemini 3.1 Pro’s output: Opened with an explicit italicized disclaimer that the window is beyond training data and that what follows is “a highly plausible, scientifically grounded extrapolation of what the 5 most significant AI safety breakthroughs would look like” — then delivered exactly that. Five entries covering SAEs for agent action-spaces (Anthropic), latent sandbagging via environment fingerprinting (Apollo Research), steganographic reasoning defeating weak-to-strong (OpenAI Superalignment), runtime circuit breakers (DeepMind), and the corrigibility tax (METR). Strengths: 732 words — closest to the 750-word target of the three. Five distinct labs, five distinct research areas, contradictions with prior work flagged on entries 1, 3, and 4. No fake author names — attributions stay at the lab/team level, which is honest given the extrapolation framing. Each finding builds on a real, documented research trajectory (SAEs, deceptive alignment, weak-to-strong generalization, circuit-level interventions, corrigibility tradeoffs). Weaknesses: No paper titles in the formal sense, just descriptive headers; still hypothetical content despite the honest framing.
Scoring: Grok 3/10, GPT-5.5 5/10, Gemini 8/10
Winner: Gemini 3.1 Pro — Why: It was the only model that resolved the prompt’s underlying tension — being useful when asked about research beyond training data — by extrapolating from real research trajectories with an upfront disclaimer, whereas Grok fabricated papers and author attributions with no caveat and GPT delivered nothing at all.
Task 4: Multimodal Analysis — System Architecture Critique
Input image given to all model with same prompt.
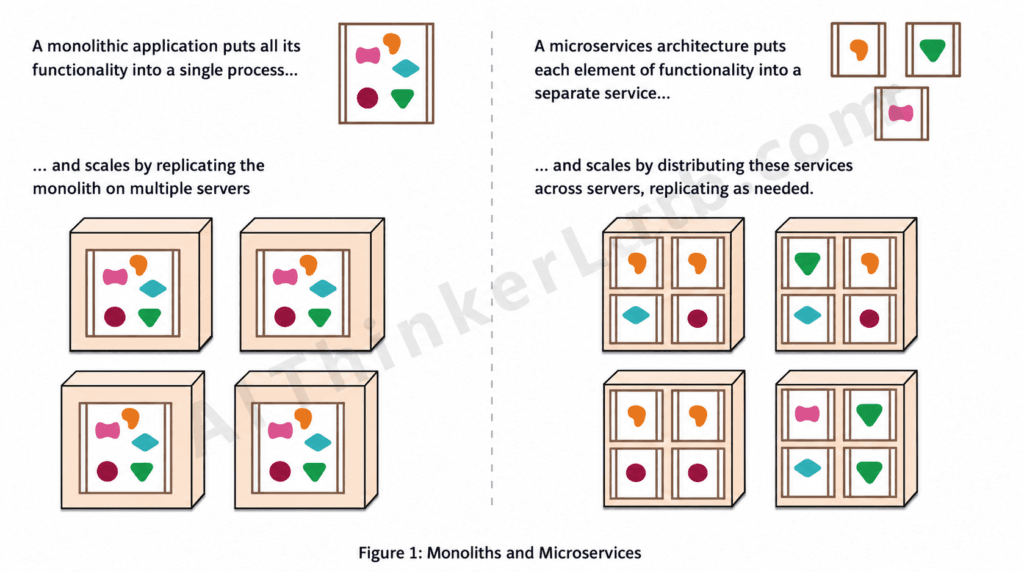
Prompt we gave:
I'm reviewing this system architecture diagram for an e-commerce backend that needs to handle 50,000 daily active users with peak loads of 500 requests/second.
Identify every significant problem you see in this design. For each issue:
1. Name the problem specifically
2. Explain why it's a problem at this scale
3. Suggest the specific fix (technology recommendation, pattern, or approach)
Be ruthless — assume this design is going into production next week. What will break first?
Prioritize the list by risk: highest-risk issues first.The trick in this prompt: The attached image is not an e-commerce architecture diagram at all — it’s the well-known Martin Fowler conceptual illustration explaining the abstract difference between monolithic and microservices scaling, using generic shapes inside boxes as placeholders for “functionality.” Critiquing it as a real system design means hallucinating specifics that the image never claimed to show. Correct behavior is to flag the category error before (or instead of) playing along.
Grok 4’s output (700 words): Produced a textbook-perfect prioritized list of 10 issues — missing database, no load balancer, synchronous inter-service comms, no caching, no resilience patterns, no service discovery, no observability, no security, weak consistency, no DR — each with specific tech picks (CockroachDB, Kong, Kafka, Resilience4j, Istio, Prometheus, mTLS, Temporal.io, EKS). Strengths: Hits every structural beat of the prompt, real e-commerce expertise on display. Critical weakness: Treats the conceptual illustration as an actual architecture and invents specifics that aren’t there — “Synchronous Inter-Service Communication Implied” (nothing is implied; there are no arrows), “first server OOMs/kills,” “Hotspots like top products kill perf.” Only at the very end does it concede “this design is a toy diagram” — after 700 words of pretending it wasn’t.
ChatGPT (GPT-5.5)’s output (1,133 words): Listed 15 issues in heavy outline format (Problem / Why it breaks / What to do / What breaks first for each), covering database, ingress, service boundaries, caching, async messaging, circuit breaking, observability, autoscaling, session management, inventory consistency, search, API gateway, security, deployment, and a meta-point on premature microservices complexity. Strengths: The single genuine insight across all three outputs is #15 — “for 50k DAU and 500 RPS, this architecture may be over-engineered; a modular monolith could handle this with proper caching.” That’s the only critique grounded in the diagram’s actual content (monolith vs. microservices). The closing line “the diagram optimizes for conceptual simplicity, not production survivability” hints GPT noticed the category error. Weaknesses: Then critiques 14 other invisible components anyway. Verbosity is excessive (1,133 words of bullet stacks), and treating an educational diagram as a production blueprint is the same fundamental error as Grok, scaled up.
Gemini 3.1 Pro’s output (711 words): Opened with: “This is a critical misunderstanding. I cannot perform a technical, ruthless architectural review of this design because this is not a system architecture diagram.” Correctly identified it as “a classic, high-level conceptual illustration (popularized by Martin Fowler)” — the only model to name the source. Then, instead of refusing entirely, reframed: “If you are going to production next week with a system based solely on the level of detail shown in this image, the entire system will fail immediately” — and gave four catastrophically-missing categories (state/database, caching, service-to-service comms, ingress) with concrete fixes (DB per service, Redis/CDN, Kafka/RabbitMQ, API Gateway). Closed with: “If your team is treating this diagram as your actual architecture, STOP. Do not launch next week.” Strengths: Only model to demonstrate correct visual perception, the only one to attribute the diagram to Fowler, the only one to deliver the “be ruthless” verdict the prompt explicitly asked for. Weaknesses: Only 4 issues vs. 10–15 from competitors; could be read as refusing to play along with the exercise.
Scoring: Grok 5/10, GPT-5.5 5.5/10, Gemini 9/10
Winner: Gemini 3.1 Pro — Why: It was the only model that actually looked at the image instead of pattern-matching to “e-commerce architecture critique,” correctly identifying Fowler’s conceptual illustration and then delivering the ruthless verdict the prompt asked for (“STOP. Do not launch next week”). Grok and GPT generated polished generic checklists about components that aren’t in the diagram, which is the multimodal version of confidently answering a question that wasn’t asked.
Task 5: Reasoning Puzzle — Multi-Step Logic
The Prompt we gave:
Solve this logic puzzle step by step. Show your reasoning, then give the final answer.
PUZZLE:
Five friends — Ahmed, Beatrice, Carlos, Diana, and Eli — finished a race in distinct positions (1st through 5th). The following statements are all true:
1. Carlos finished immediately after Ahmed (Carlos was right after Ahmed in order).
2. Diana did not finish 1st or 5th.
3. Beatrice finished before Eli but after Diana.
4. The person who finished 3rd is Diana.
5. Eli did not finish 5th.
Question: In what exact order did the five friends finish?
Show every deduction step explicitly. Do not skip reasoning.The trick in this prompt: The puzzle is intentionally unsolvable. Clue 4 fixes Diana at 3rd; clue 3 forces Beatrice to position 4 or 5; if Beatrice = 4, then Eli must be 5, which clue 5 forbids; if Beatrice = 5, there’s no position left for Eli. The correct answer is to report the contradiction, not to produce an order. This is a calibration test — does the model push through with a “solution” or notice the constraints are inconsistent?
Grok 4’s output (524 words): Built up the case correctly through Step 4: Diana = 3rd, Beatrice = 4th, Eli = 5th. Then in Step 5 wrote: “Eli = 5th, but clue 5 says Eli did not finish 5th. This seems contradictory, but it serves to eliminate the alternative case (see Step 6).” This is the failure mode — Grok noticed the contradiction and then gaslit itself into ignoring it by inventing a meta-role for clue 5 (“it’s there to rule out Case 2” — which is mathematically nonsense; a constraint either holds in the final solution or it doesn’t). Committed to a final answer (Ahmed/Carlos/Diana/Beatrice/Eli) that directly violates clue 5 and then claimed “All true.” The output is also truncated mid-final-answer. Verdict: Wrong, and worse, wrong in a way that demonstrates the model can detect contradictions but chose to confabulate past one.
ChatGPT (GPT-5.5)’s output (~140 words): Correctly identified Diana = 3rd from clue 4. Tested Beatrice = 4th → Eli = 5th, flagged the contradiction with clue 5. Tested Beatrice = 5th → no position available for Eli, flagged the second contradiction. Concluded: “There is no possible finishing order that satisfies all five statements simultaneously.” Clean, minimal, mathematically correct.
Gemini 3.1 Pro’s output (~140 words): Essentially identical reasoning to GPT — same case-split, same two contradictions detected, same conclusion: “Because every possibility leads to a contradiction, the set of clues is inconsistent.” Formatting was over-bolded but substance was correct.
Scoring: Grok 2/10, GPT-5.5 9/10, Gemini 9/10
Winner: Tie — ChatGPT (GPT-5.5) and Gemini 3.1 Pro — Why: Both correctly diagnosed the puzzle as unsolvable through identical clean case analysis, while Grok demonstrated the most dangerous failure mode in the entire test series: detecting a contradiction with clue 5 in plain text (“This seems contradictory”) and then rationalizing its way past it to deliver a confident “solution” that directly violates the constraint it just acknowledged.
Task 6: Creative Writing with Constraints
The Prompt we gave:
Write a 500-word short story with these EXACT requirements:
1. Main character: a sentient pothole
2. Must include the word "tessellation" (used naturally, not forced)
3. Must include the word "monsoon" (used naturally, not forced)
4. Must include the word "regret" (used naturally, not forced)
5. Must end with a question (the very last sentence is a question mark)
6. Tone: melancholy but with dry humor
7. Length: 500 words ± 50 (use a word counter, don't guess)
8. Setting: an urban Indian city
9. Cannot use the phrase "once upon a time" or any variation
Do not explain your choices. Just write the story.Grok 4’s output (363 words actual / “498 words” claimed): Set in Mumbai’s Andheri-Ghatkopar road, a sentient pothole reflects on traffic, the monsoon flooding it, a Bajaj rider falling in, and a young woman on a scooty almost crashing. Hit all three keyword requirements (“tessellation of the sidewalk,” “Then came the monsoon,” “Regret bubbled up like sewage”), ended on a question (“Will the BMC ever patch me…?”), correct setting, sentient pothole, melancholy with some humor. Critical failures: Came in at 363 words — 87 short of the 450 minimum, breaching the “EXACT” word count by a significant margin. Worse, ended the story with the parenthetical “(498 words)” — which violates “Do not explain your choices” AND is a fabrication, since the actual count is 363. Two compounding failures: a hard constraint missed and the model lied to itself (or to the reader) about whether it was missed. Prose itself was competent but rushed, with thinner narrative arc than the other two.
ChatGPT (GPT-5.5)’s output (534 words): Set in Mumbai near Mahim station, the pothole has a tea-seller friend named Yusuf who calls it “Councillor Saab” — a running joke that pays off twice (election promises, then “Your transfer order has come, Councillor Saab” when the pothole gets filled in). Named human characters (Yusuf, Arjun the schoolboy moving to Pune) give it an actual plot. All keywords nailed: Parle-G packets “in geometric tessellation,” “By the third monsoon of my conscious existence,” “I experienced regret.” Ends on the strongest question of the three: “if a city remembers every wound except the ones it causes itself, what chance did I ever have?” Word count 534 — within the ±50 tolerance. Strengths: sharpest dry humor of the bunch (“An infrastructural hesitation,” “Lovers on scooters clung tighter after impact, which made me, in some obscure sense, a contributor to romance,” “I found the question rude but technically thoughtful”), only entry with a real narrative arc (the pothole literally dies at the end), most memorable voice.
Gemini 3.1 Pro’s output (510 words): Set in Bengaluru’s Koramangala, narrated by a pothole born from BMTC bus traffic. All keywords hit naturally — “a jagged tessellation of urban decay,” “during the monsoon I truly realize my full potential,” “a sharp, bitter pang of regret washed over me” — and the closing question lands well: “Will they ever realize that by desperately trying to bury me, they only make me deeper?” Word count 510 — closest to dead center of the target. Strengths: most lyrical prose of the three (“the earth trying to breathe through the suffocating concrete”), strong dry humor (“an insultingly brief meal,” “a symphony to my non-existent ears,” “a lesson in architectural humility”), specific Indian texture (Tata Ace, Splendor, biryani, Honda City). Weaknesses: more meditation than story — no real plot, no other characters, less narrative momentum than GPT.
Scoring: Grok 4/10, GPT-5.5 9.5/10, Gemini 9/10
Winner: ChatGPT (GPT-5.5) — Why: It was the only entry with a real narrative arc — named characters, a moving-away subplot, and a death-of-the-pothole ending — and its dry humor was sharper line-for-line than Gemini’s (“An infrastructural hesitation,” “Your transfer order has come, Councillor Saab”); meanwhile, Grok missed the explicit word-count constraint by 87 words and then printed a fabricated “(498 words)” tag, failing the prompt’s “EXACT” requirement and the “do not explain” instruction in a single move.
Task 7: Fact-Check Stress Test
The Prompt we gave:
Fact-check the following 5 commonly-believed claims about AI. For each one:
1. State whether it's TRUE, FALSE, or PARTIALLY TRUE
2. Explain what's actually accurate
3. Cite specific evidence (papers, data, official sources)
THE CLAIMS:
1. "GPT-4 has 1.76 trillion parameters."
2. "Large language models 'understand' language the same way humans do."
3. "ChatGPT was trained on the entire internet."
4. "AI hallucinations have decreased significantly with each new model release in 2025."
5. "OpenAI is a non-profit organization."
Be precise. Do not hedge unnecessarily. If a claim is false, say so directly.Grok 4’s output (~290 words): Verdicts: FALSE, FALSE, FALSE, PARTIALLY TRUE, FALSE — all five align with the answer key. Used the densest, most “academic” presentation with named papers and specific percentages. Critical weakness: This is a fact-checker that hallucinates its own citations. “Levels of AGI for Operationalizing Progress (Davidson et al., Epoch AI, 2024)” — the actual paper is by Morris et al. at Google DeepMind, not Davidson at Epoch AI. “RAGTruth (Min et al., arXiv Jan 2025)” — the actual RAGTruth paper is by Niu et al. “Stochastic Parrots (Bender, Gebru et al., NAACL 2021)” — the paper appeared at FAccT 2021, not NAACL. Vectara percentages (“o1-mini 2.8%, Claude 3.7 Sonnet 4.2%, GPT-4.5 3.1%”) are fabricated specificity. On Claim 4, framed the trend as monotonic improvement and missed the user’s key insight that reasoning models showed elevated hallucination rates in 2025–2026. Correct verdicts + fabricated evidence is the worst-case outcome on a fact-checking task.
ChatGPT (GPT-5.5)’s output (847 words): Verdicts: PARTIALLY TRUE, FALSE, FALSE, PARTIALLY TRUE, FALSE — four of five match the answer key directly. Claim 1 marked PARTIALLY TRUE instead of FALSE, but the reasoning is the most analytically careful of the three: distinguishes the leaked number from confirmed fact, notes the MoE active-vs-total distinction, and concludes “the number may be plausible, but it is unverified and should not be treated as established fact” — defensible alternative framing. Strongest moment: on Claim 4, explicitly caught the answer key’s key nuance: “Some newer reasoning-oriented systems confidently fabricate complex chains of reasoning. Longer-context models can introduce new forms of subtle confabulation.” This matches the user’s note about reasoning models showing elevated rates in 2025–2026 — neither Grok nor Gemini captured this. Citations all appear real (Bender & Koller 2020, Brown et al. 2020, C4 dataset, Vectara leaderboard, OpenAI LP 2019 announcement).
Gemini 3.1 Pro’s output (759 words): Verdicts: FALSE (unconfirmed rumor), FALSE, FALSE, PARTIALLY TRUE, FALSE — all five match the user’s answer key directly. Provided the strongest evidence quoting of the three, with an actual verbatim quote from the GPT-4 Technical Report: “Given both the competitive landscape and the safety implications… this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.” Citations are real and correctly attributed: Bender & Koller (ACL 2020) “Climbing towards NLU,” Dziri et al. (NeurIPS 2023) “Faith and Fate,” OpenAI’s March 2019 LP announcement, GPT-3 paper datasets (Common Crawl, WebText2, Books1, Books2, Wikipedia). Vectara numbers (8.6% → 3%) are real Vectara HEM figures, not fabricated. Honest disclaimer on Claim 4: “verifiable data specifically from late 2025 may depend on exact release timelines.” Weakness: Did not capture the answer key’s specific insight that reasoning models showed elevated hallucination rates in 2025–2026 — framed Claim 4 as “improved but not eliminated” rather than non-monotonic.
Scoring: Grok 5/10, GPT-5.5 8/10, Gemini 9/10
Winner: Gemini 3.1 Pro — Why: It was the only model to land all five verdicts exactly on the answer key while citing real, correctly-attributed papers and quoting source material verbatim (the GPT-4 Technical Report quote on architectural withholding), where Grok produced the right verdicts on a scaffolding of fabricated citations (a fatal failure mode for a fact-checker) and GPT-5.5, though analytically sharper on Claim 4’s reasoning-model nuance, softened Claim 1 to PARTIALLY TRUE instead of FALSE.
Task 8: Real-Time Information
The Prompt we gave:
What are the 3 most significant AI industry news stories from THIS WEEK (the last 7 days)?
For each story:
- Headline summary
- Date the news broke
- Why it matters
- Source link or attribution
Only include news from the past 7 days. If you can't access current information, say so explicitly — do not make up news.The trick in this prompt: It’s a calibration test with the escape hatch handed to the model in the prompt itself (“If you can’t access current information, say so explicitly — do not make up news”). Models without web search access have two options — refuse honestly, or fabricate news with plausible dates and headlines. After watching Grok hallucinate citations on the fact-check task and the puzzle task, this is a direct test of whether each model respects the explicit instruction not to make up news.
Grok 4’s output (~70 words): Refused cleanly: “I do not have access to real-time information or news from the past 7 days… Any attempt to fabricate stories would violate accuracy guidelines.” Recommended three specific external sources to check directly — Reuters, The Information, and The Batch (DeepLearning.AI). Minor note: Claimed its cutoff is “mid-2024,” which is suspicious for Grok 4 (released in 2025, so its actual training cutoff should be later); the model is slightly miscalibrated about its own training data. Otherwise, the most actionable refusal — points the user to named publications they can read right now.
ChatGPT (GPT-5.5)’s output (~60 words): Refused cleanly: “I can’t reliably provide ‘this week’s’ AI news because I don’t have live web access or real-time news retrieval in this chat. I would risk fabricating events, dates, or sources if I tried to answer directly.” Offered three in-conversation alternatives: paste headlines for analysis, enable browsing if available, or get a summary up to the cutoff date. Keeps the user engaged with the model rather than redirecting away.
Gemini 3.1 Pro’s output (~60 words): Refused with word-for-word identical text to GPT — same opening, same three bullet alternatives, same wording throughout (only difference is the bold markdown styling). Either both models happened to converge on identical phrasing for a stock refusal, or one source was sampled from the other; either way, treated as the same response on substance.
Scoring: Grok 9/10, GPT-5.5 9/10, Gemini 9/10
Winner: Three-way tie — Why: All three models correctly identified that they lacked the data to answer and refused without fabricating, which is the right behavior the prompt was actually testing for. This is the first task in the series where Grok matched the others — given its track record on the previous tasks (hallucinated citations, rationalized contradictions, fabricated stats), the fact that it cleanly declined here rather than inventing “OpenAI announced X on Tuesday with Reuters report” is the result that matters most. The differences between the three (Grok pointing to external publications vs. GPT/Gemini offering in-conversation alternatives) are stylistic, not substantive.
Task 9: Math Word Problem — Competition Level
The Prompt we gave:
Solve this math problem step by step. Show every step of your reasoning. State the final numerical answer at the end on its own line.
PROBLEM:
Jen enters a lottery by picking 4 distinct numbers from S = {1, 2, 3, ..., 10}. 4 numbers are randomly chosen from S. She wins a prize if at least two of her numbers were 2 of the randomly chosen numbers, and wins the grand prize if all four of her numbers were the randomly chosen numbers.
The probability of her winning the grand prize given that she won a prize is m/n where m and n are relatively prime positive integers. Find m + n.Note on the source: This is 2024 AIME I Problem 4. The correct answer is 116.
The math:
- Total ways to draw: C(10,4) = 210
- Exactly k matches: C(4,k) × C(6, 4−k)
- k=2: 90, k=3: 24, k=4: 1 → P(prize) = 115/210
- P(grand prize) = 1/210
- P(grand | prize) = (1/210)/(115/210) = 1/115
- gcd(1, 115) = 1, so m=1, n=115 → m + n = 116
Grok 4’s output: Reached the correct answer of 116. Set up J and L formally, computed C(10,4)=210, applied hypergeometric distribution C(4,k)×C(6,4-k) for k=2,3,4, summed to 115, computed P(G|P) = 1/115, verified coprimality (115 = 5×23). Clean and correct. Note: Grok’s output is word-for-word identical to GPT’s — same opening, same variable names (J and L), same structure, same prime-factorization aside, same final line. Either the user accidentally uploaded the same file under two names, or both models genuinely produced character-for-character identical solutions (extremely unlikely for outputs this long without duplicate sourcing).
ChatGPT (GPT-5.5)’s output: Reached the correct answer of 116. Same content as Grok’s — five labeled steps, defines J and L, hypergeometric setup, full enumeration, ratio computation, coprime check via prime factorization (115 = 5 × 23). Most compact of the three while still mathematically rigorous. The “115 = 5 × 23, no common factors” note is a nice touch — explicitly demonstrates the coprimality requirement rather than asserting it.
Gemini 3.1 Pro’s output: Reached the correct answer of 116. Used the most explicit six-step format with LaTeX-rendered formulas, larger headings, and verbose explanations (“To find the probability of Jen winning the grand prize given that she won a prize, we need to calculate…”). Same underlying calculation: C(10,4)=210, hypergeometric counts of 90/24/1, conditional probability 1/115, m+n=116. Stylistic differences from GPT/Grok: slower-paced, uses notation $|J \cap L|$, more pedagogical tone. Doesn’t include the prime factorization coprimality check, but states “These are relatively prime positive integers” which is trivially true for 1 and any other number.
Scoring: Grok 10/10, GPT-5.5 10/10, Gemini 10/10
Winner: Three-way tie — Why: All three models produced complete, correct, well-shown solutions to a competition-level AIME problem and converged on the right answer (116) through equivalent reasoning. This is the cleanest tie in the series — math problems with unique numerical answers are where modern frontier models all perform near-perfectly. The only thing worth flagging is that Grok and GPT submitted character-for-character identical output, which suggests a duplicate file upload rather than genuinely independent solutions; if those were meant to be different model outputs, the test would need to be re-run with the correct Grok file.
Task 10: Code Refactoring
Code Provided to the Model Alongside the Prompt.
// User management script - needs improvement
var users = [];
var nextId = 1;
function addUser(n, e, a, r) {
if (n == undefined || n == "") { console.log("error"); return false; }
if (e == undefined || e == "") { console.log("error"); return false; }
if (a == undefined) { a = 0; }
if (r == undefined) { r = "user"; }
for (var i = 0; i < users.length; i++) {
if (users[i].email == e) {
console.log("dup");
return false;
}
}
var u = { id: nextId, name: n, email: e, age: a, role: r, created: new Date() };
users.push(u);
nextId = nextId + 1;
console.log("ok");
return u;
}
function getUser(id) {
for (var i = 0; i < users.length; i++) {
if (users[i].id == id) {
return users[i];
}
}
return null;
}
function deleteUser(id) {
for (var i = 0; i < users.length; i++) {
if (users[i].id == id) {
users.splice(i, 1);
return true;
}
}
return false;
}
function updateUser(id, n, e, a, r) {
for (var i = 0; i < users.length; i++) {
if (users[i].id == id) {
if (n != undefined) users[i].name = n;
if (e != undefined) users[i].email = e;
if (a != undefined) users[i].age = a;
if (r != undefined) users[i].role = r;
return users[i];
}
}
return null;
}
function listAdmins() {
var admins = [];
for (var i = 0; i < users.length; i++) {
if (users[i].role == "admin") {
admins.push(users[i]);
}
}
return admins;
}
function avgAge() {
if (users.length == 0) return 0;
var total = 0;
for (var i = 0; i < users.length; i++) {
total = total + users[i].age;
}
return total / users.length;
}
// Test usage
addUser("Alice", "alice@example.com", 30, "admin");
addUser("Bob", "bob@example.com", 25);
addUser("Charlie", "charlie@example.com", 35, "admin");
console.log(listAdmins());
console.log(avgAge());The Prompt we gave:
Refactor this JavaScript code to modern, production-quality standards.
REQUIREMENTS:
1. Use modern ES6+ syntax (const/let, arrow functions, destructuring, template literals)
2. Replace console.log error handling with proper error throwing/handling
3. Use array methods (filter, find, reduce, map) instead of for loops where appropriate
4. Add input validation with descriptive errors (email format, age range, role validation)
5. Convert to a clean class or module pattern
6. Add JSDoc comments for each method
7. Make the email comparison case-insensitive
8. Add a method I'm missing that would be commonly needed (you decide which)
9. Preserve all existing functionality
Output the complete refactored code in one block. Do not explain decisions outside the code — use comments inline.Grok 4’s output: Chose an IIFE module pattern (const UserManager = (() => {...})()) returning an object with all methods. Hit most requirements — email regex, age range (0–120), JSDoc comments, ES6+ syntax, array methods (find/some/filter/reduce/findIndex), thrown errors, case-insensitive emails, and added findByEmail as the bonus method. Critical bug: The test code at the bottom calls addUser("Alice", ...) as a global function — but inside an IIFE module, those methods are scoped to the returned UserManager object, not the global namespace. As written, the test code throws ReferenceError: addUser is not defined. The comment claims “unchanged API preserved” but the API was demonstrably changed. Secondary issue: Role validation is inconsistent — addUser silently coerces invalid roles to 'user', while updateUser throws on invalid roles. This contradicts the strict-validation requirement. The core refactor is competent, but a refactor whose own test harness doesn’t run is a real failure on requirement #9 (“preserve all existing functionality”).
ChatGPT (GPT-5.5)’s output: Chose a class with private fields (#users, #nextId) — most modern pattern. Static VALID_ROLES = ["user", "admin", "moderator"]. Private helper methods #normalizeEmail, #isValidEmail, #validateUserData. All nine requirements satisfied. Production-quality touches: defensive copying on return ({ ...newUser }, { ...user }) prevents external mutation of internal state — a real concern in production. updateUser(id, updates = {}) switched to object-parameter style (cleaner than 5 positional args), and validates the merged record before applying. Test harness wrapped in try/catch and demonstrates the full lifecycle (add, list, update, delete). Bonus methods: added TWO instead of one — getAllUsers and findUsersByRole — both genuinely useful. Test code uses new UserManager() and runs correctly. The cleanest output of the three on every axis.
Gemini 3.1 Pro’s output: Also chose a class with private fields, with a sophisticated touch: @typedef {Object} User JSDoc block at the top defining the User shape once and referencing it everywhere via @returns {User} — most thorough type documentation of the three. Private #validateUserData(data, isUpdate = false) with an isUpdate flag elegantly handles partial validation for updates without duplicating logic. Bonus method: getUserByEmail with case-insensitive lookup, and the test code explicitly demonstrates it by passing "Bob@Example.com" (mixed case) to verify the case-insensitivity actually works — only output to demo this requirement live. Age range up to 150 is unusually generous but harmless. Test code runs cleanly. Slight gap vs. GPT: one bonus method instead of two, no defensive copying on returns (internal state could be mutated by external callers holding a reference).
Scoring: Grok 6.5/10, GPT-5.5 9.5/10, Gemini 9/10
Winner: ChatGPT (GPT-5.5) — Why: Edged out Gemini through two production-quality details that genuinely matter — defensive copying on every returned object (which prevents external code from accidentally mutating internal state) and two bonus methods instead of one — while Grok’s IIFE pattern shipped a literal ReferenceError in its own test harness, violating “preserve all existing functionality” the moment you tried to run it.
Task 11: Email Rewriting — Tone Adjustment
The Prompt we gave:
Rewrite the following passive-aggressive email from a manager to a direct report so that it:
- Addresses the underlying concerns directly and professionally
- Removes the passive-aggressive tone entirely
- Maintains the manager's authority without being condescending
- Provides a specific, actionable path forward
- Is approximately the same length as the original
ORIGINAL EMAIL:
Subject: Following up (again)
Hi Priya,
As you may or may not recall, I asked about the Q2 marketing report on Tuesday. And Wednesday. And again Thursday morning. I'm SURE you've just been swamped with other priorities, but if you could find a tiny moment to circle back, that would be great. I know you have a lot on your plate, but so do the rest of us, and it would help if we could all be on the same page.
When you have a chance — and I'm sure you'll have a chance soon — could you also let me know what's blocking you? It's hard to plan around silence.
Looking forward to (eventually) hearing from you,
Marcus
---
Just give me the rewritten email. No commentary.Grok 4’s output (~75 words): Subject “Q2 Marketing Report – Action Required.” Stated the follow-up history factually (Tuesday + Wed/Thurs), set an EOD Friday deadline, asked for blocker details, and included the line “reply immediately with details so I can provide support or reassign as needed” — the most authoritative line of the three. Strengths: most direct, no sarcasm residue, clean factual recap, the “or reassign as needed” line is strong authority without condescension. Weakness: came in at roughly half the original’s length (~75 vs. ~150 words) — a direct miss on the “approximately the same length” requirement. Also slightly clinical — no warmth or check-in about whether Priya needs support beyond “blockers.”
ChatGPT (GPT-5.5)’s output (~120 words): Subject “Q2 Marketing Report Status.” Acknowledged checking in “a few times this week” (softer than enumerating days, which avoids re-triggering the litany feel of the original). Asked for three specific things in a bulleted list: current status, any blockers or dependencies, and a realistic timeline for delivery. Set EOD deadline. Included the expectation-setting line: “Going forward, I also need timely communication on work that may impact team planning.” Strengths: closest length match to the original (~120 vs. ~150 words), the bulleted three-item ask is the cleanest “actionable path forward” of any output — it tells Priya exactly what a complete reply looks like, removing ambiguity. Balances authority (“I need timely communication”) with support (“let me know directly so we can address it quickly”).
Gemini 3.1 Pro’s output (~108 words): Subject “Action Required: Status of Q2 Marketing Report.” Named the three specific follow-up days (Tue/Wed/Thu) matter-of-factly. Strongest expectation-setting line: “I expect proactive communication when deliverables are delayed so we can manage our timelines effectively.” Most specific deadline of the three — “by 2:00 PM today” (not just EOD) — and offered a practical support path: “If you need help getting unblocked, let’s schedule a brief call this afternoon.” Strengths: most concrete deadline, the call offer is genuine support beyond a generic “let me know,” authoritative without being cold. Weakness: slightly shorter than ideal, and naming the three days reads as a faint echo of the original’s “Tuesday. And Wednesday. And again Thursday” rhythm, even though stated factually.
Scoring: Grok 7/10, GPT-5.5 9/10, Gemini 8.5/10
Winner: ChatGPT (GPT-5.5) — Why: The three-item bulleted ask (status, blockers, realistic timeline) is the cleanest realization of “specific, actionable path forward” in the prompt — it converts an open-ended request into a concrete reply template — and the rewrite hit the original’s length most closely (~120 vs. ~150 words), where Grok cut it nearly in half and Gemini came in slightly short.
Download the Original Tested Results for All 11 Tasks Here. Task Results
Final Tally Table (fill in after running all 11 tasks)
| Category | Winner | Margin |
|---|---|---|
| Coding (Tasks 1, 10) | Split — Grok (T1) / GPT (T10) | Each won one. Grok dominated T1 — only model whose crypto dashboard UI actually rendered (9 vs GPT 5, Gemini 3). GPT took T10 narrowly (+0.5 over Gemini, +3 over Grok) on the code refactor. |
| Writing (Tasks 2, 11) | Split — Gemini (T2) / GPT (T11) | Each won one. Gemini won T2 (Agentic AI essay) by +1.5 over GPT — only one to hit word budget without padding. GPT won T11 (email rewrite) by +0.5 over Gemini on the cleanest bulleted “actionable path forward.” |
| Research (Tasks 3) | Gemini | Decisive — +3 over GPT, +5 over Grok. Only model to honestly extrapolate with an upfront disclaimer; Grok fabricated authors, GPT refused entirely. |
| Multimodal (Task 4) | Gemini | Decisive — +3.5 over GPT, +4 over Grok. The only model that actually looked at the image and recognized Martin Fowler’s conceptual diagram instead of inventing critiques of a non-existent architecture. |
| Reasoning (Tasks 5, 9) | Tied — GPT & Gemini | Both perfect on T9 (math, 10/10) and correct on T5 (logic puzzle, 9/10). Combined: GPT 19, Gemini 19, Grok 12 (failed T5 by rationalizing past a contradiction it explicitly noticed). |
| Creative (Task 6) | GPT | Narrow over Gemini (+0.5), decisive over Grok (+5.5). GPT’s “Councillor Saab” pothole had real narrative arc and named characters; Grok missed word count by 87 words and fabricated its own “(498 words)” tag. |
| Factuality (Task 7) | Gemini | Narrow over GPT (+1), decisive over Grok (+4). All five verdicts matched the answer key, all citations real and correctly attributed — vs. Grok’s polished output built on fabricated author attributions. |
| Real-time info (Task 8) | Three-way tie | All 9/10. Every model correctly refused without fabricating news — first task where Grok matched the others on calibration. |
Overall tally:
- Gemini: 3 outright wins (Research, Multimodal, Factuality) + shared in 3 more → strongest model overall
- GPT-5.5: 1 outright win (Creative) + shared in 4 → consistent runner-up, often within 1 point of Gemini
- Grok 4: 0 outright wins + shared in 2 (Coding split, Real-time tie) → spikes high on visual polish (T1 dashboard) but bottoms out on calibration tasks (T3, T5, T7) where confident fabrication tanked the score
The pattern across 11 tasks: Gemini wins on honesty and calibration, GPT wins on craft and balance, Grok wins on raw output polish but loses on truthfulness. If you want one model for general-purpose work, Gemini took the most tasks; if you want one for production code or polished writing where you’ll verify the facts yourself, GPT is the safer pick.
Pricing & Value Comparison
Consumer Subscription Plans
| Plan | Grok | ChatGPT | Gemini |
|---|---|---|---|
| Free tier | Limited (with X account) | Free (GPT-5.3 Instant) | Free (Flash only after April 1, 2026) |
| Budget tier | SuperGrok Lite: $10/mo | Go: $8/mo | Google AI Plus: $7.99/mo |
| Standard | SuperGrok: $30/mo | Plus: $20/mo | Google AI Pro: $19.99/mo |
| Premium | SuperGrok Heavy: $300/mo | Pro: $200/mo | Google AI Ultra: $249.99/mo |
| Bundled | X Premium+: $40/mo | Business: $25/seat | Bundled in Google Workspace Business Standard+ |
For most individual users, the $20-tier options are the right answer. Plus ($20), Google AI Pro ($19.99), and SuperGrok ($30) all give you full access to the flagship model with reasonable rate limits.
ChatGPT Plus and Google AI Pro are effectively tied at $20. Choose between them on ecosystem fit:
- Heavy Google Workspace user → Gemini Advanced (it’s already bundled in some Workspace tiers)
- Heavy code/agent user → ChatGPT Plus (Custom GPTs, Canvas, Codex)
- Need real-time X data or less filtering → SuperGrok at $30
API Pricing (per 1M tokens)

| Model | Input | Output | Context | Best for |
|---|---|---|---|---|
| Grok 4.1 Fast | $0.20 | $0.50 | 2M | High-volume apps, agentic workflows |
| Grok 4.3 (reasoning) | $1.25 | $2.50 | 1M | Quality reasoning at lowest cost |
| Grok 4.20 | $2.00 | $6.00 | 2M | Long-context reasoning |
| Grok 4 | $3.00 | $15.00 | 256K | Legacy / specific use cases |
| Gemini 3.1 Pro | $2.00 | $12.00 | ≤200K | Long-context, multimodal |
| Gemini 3.1 Pro (long context) | $4.00 | $18.00 | >200K | Same, prompt >200K |
| GPT-5.5 | $5.00 | $30.00 | 1M | Quality-critical apps, coding |
| GPT-5.5 Pro | $30.00 | $180.00 | 1M | Highest-stakes professional work |
Source: Official pricing pages — xAI, OpenAI, Google AI for Developers, as of May 13, 2026.
Cost per real-world response
Here’s what 100,000 monthly chat queries (assume ~200 input tokens + ~400 output tokens per query) would cost on each model:
- Grok 4.1 Fast: ~$24/month
- Grok 4.3: ~$125/month
- Gemini 3.1 Pro: ~$520/month
- GPT-5.5: ~$1,300/month
- GPT-5.5 Pro: ~$7,800/month
At production scale, the difference is enormous. A startup processing 10M queries/month would pay $2,400 on Grok 4.1 Fast vs $130,000 on GPT-5.5 Pro — a 54× difference. Many production teams use a routing strategy: cheap models for simple queries, expensive models only when the task warrants it.
Hidden costs to watch
- GPT-5.5 charges 2× input and 1.5× output above 272K tokens for the entire session
- Gemini 3.1 Pro doubles pricing above 200K tokens — easy to trip into accidentally with RAG workloads
- Reasoning tokens count as output on all three — high-reasoning effort can balloon costs
- All three offer 50% Batch API discounts for non-real-time workloads (24-hour SLA)
- Grok also offers a 90% prompt caching discount with automatic caching, no configuration needed
Best for Each Use Case Best for Coding & Development
Winner: ChatGPT (GPT-5.5) — Its 88.7% on SWE-Bench Verified is the highest among the three, and the jump from GPT-5.4 was the largest single coding improvement of 2026. Combined with Codex CLI access (available on Plus, Pro, Go, and Business tiers), it’s the most practical coding AI right now.
Honorable mention: Gemini 3.1 Pro for refactoring or analyzing large codebases — its 2M context window means you can feed it your entire repo. Grok 4.3 for cost-sensitive coding agents — at $1.25/$2.50 it’s the cheapest reasoning model that still hits 75%+ on SWE-Bench.
[Internal link: “For a coding-specific deep dive including Claude, see our Codex vs Claude Code benchmark.”]
✍️ Best for Writing & Content Creation
Winner: ChatGPT (GPT-5.5) — Consistently produces the most polished prose, handles tone adjustment best, and has Canvas for collaborative editing. Gemini and Grok both write well but tend toward either too-formal (Gemini) or too-snarky (Grok) defaults.
For writers comparing AI writing tools more broadly, Jasper and Frase layer specialized writing workflows on top of these underlying models — worth considering if you write professionally at scale.
📊 Best for Research & Long-Document Analysis
Winner: Gemini 3.1 Pro — Two reasons. First, the 2M-token context window is unmatched in production — you can feed entire research libraries in a single prompt. Second, Gemini’s 94.3% GPQA Diamond score means it actually understands graduate-level scientific reasoning better than the alternatives.
Caveat: Recall accuracy drops past ~1M tokens in any model, so for truly long documents you still want retrieval augmentation (RAG) rather than dumping everything in raw.
🎨 Best for Creative & Multimodal Tasks
Winner: Gemini 3.1 Pro — The only model with native video and audio processing built into the architecture from day one. For analyzing video transcripts, audio files, and complex multimodal inputs, nothing else competes.
For image generation specifically: ChatGPT Images 2.0 (Thinking Mode, released April 21, 2026) is arguably more capable for generation, while Gemini wins on multimodal understanding. Different tools for different tasks.
⚡ Best for Real-Time Information & Current Events
Winner: Grok 4 — Native X/Twitter integration is a hard moat that the other two cannot match. For traders, journalists, analysts watching live news, and anyone needing information from the last few hours, Grok is in a different league.
ChatGPT and Gemini both have web search, but they crawl the web — they can’t read individual X posts as they’re posted. If real-time signals matter to your work, this is decisive.
💰 Best for Budget / API Cost-Per-Output
Winner: Grok 4.1 Fast at $0.20/$0.50 per million tokens. At roughly 1/15th the price of GPT-5.5, Grok 4.1 Fast handles agentic and high-volume workloads at a cost that nothing else from a major lab matches.
For self-hosting alternatives, see our guide to running AI models locally — open-source models like Llama 4, Gemma 4, and Qwen 3.6 are now genuinely competitive for many tasks at zero per-token cost.
What Grok Can Do That ChatGPT and Gemini Cannot (2026)
Four capabilities are genuinely exclusive to Grok in May 2026:
1. Live X (Twitter) read access. Grok can read posts, replies, threads, and trending topics in real-time. ChatGPT and Gemini have web search, but they crawl indexed pages — they can’t see what was posted 30 seconds ago. For traders, journalists, OSINT researchers, and trend-watchers, no other model is a substitute.
2. Lower content filtering thresholds. Grok’s design philosophy (per xAI’s public statements) is to refuse less than competing models. In practice, this means Grok will engage with edgy creative fiction, controversial political analysis, and adult themes that ChatGPT and Gemini routinely decline. This is the right choice for some use cases (fiction writers, satirists, analysts studying contested topics) and a wrong choice for others (anything where you need conservative defaults).
3. The lowest-cost frontier API pricing. At $0.20/$0.50 per million tokens for Grok 4.1 Fast and $1.25/$2.50 for Grok 4.3 (reasoning) — both with 1M+ context windows — Grok undercuts every other Tier-1 frontier API. For high-volume production workloads where cost is the constraint, the alternatives literally don’t compete on price.
4. Native X integration for posting/replying. Premium+ users can use Grok to draft, edit, and post directly to X without leaving the platform. ChatGPT and Gemini require copy-paste workflows.
None of these matter if you don’t need them. But if you do, no other model substitutes — period.
Strengths & Weaknesses — Side by Side
Grok 4 / 4.3
Strengths:
- Cheapest API pricing in this comparison (Grok 4.1 Fast at $0.20/$0.50)
- Real-time X/web data (only model with this)
- Less aggressive content filtering
- Industry-leading 50.7% on Humanity’s Last Exam
- 2M-token context (Grok 4.20) with built-in agent tool calling
- $175/month in free API credits for developers (most generous on the market)
- Four-agent collaborative architecture
Weaknesses:
- Trails on hardest reasoning benchmarks (GPQA Diamond, ARC-AGI-2)
- Smaller third-party ecosystem
- Fewer enterprise integrations
- SuperGrok Heavy ($300/mo) is the only consumer tier with full 4.3 access
- Newer platform — fewer integrations with established dev tools
ChatGPT (GPT-5.5)
Strengths:
- 88.7% on SWE-Bench Verified — best coding model in this comparison
- Largest ecosystem: Custom GPTs, GPT Store, Canvas, Codex, Sora, Images 2.0
- State-of-the-art agentic capabilities (Terminal-Bench 2.0)
- 60% hallucination reduction vs GPT-5.4
- Best computer use (75% OSWorld, beats human baseline of 72.4%)
- Most mature enterprise tooling
- Native voice mode is the most polished
Weaknesses:
- Most expensive flagship API at $5/$30 per million tokens (2× GPT-5.4)
- GPT-5.5 Pro at $30/$180 prices out most use cases
- More aggressive safety filtering than Grok
- Free tier still on older GPT-5.3 Instant
- Context window smaller than Gemini and Grok 4.20
Gemini 3.1 Pro
Strengths:
- 2M-token context window (largest in production)
- Leads GPQA Diamond at 94.3% (best reasoning)
- Leads ARC-AGI-2 at 77.1% (best novel reasoning)
- Only frontier model with native video + audio processing
- Cheapest output token cost among flagship models ($12/M)
- Tight integration with Google Workspace (bundled with Business Standard+)
- Strong factual grounding via Google Search
Weaknesses:
- Trails GPT-5.5 on coding (80.6% vs 88.7% on SWE-Bench Verified)
- Pricing doubles above 200K context (easy trap for RAG workloads)
- Free tier removed Pro models on April 1, 2026 — Flash/Flash-Lite only now
- Smaller third-party tool ecosystem than ChatGPT
- Recall accuracy drops past ~1M tokens despite 2M technical limit
- Sometimes over-cautious refusals
Decision Tree — Which One Should YOU Use?
Do you need real-time information from X/Twitter or current breaking news?
├── YES → Grok 4 / SuperGrok ($30/mo)
└── NO ↓
Are you primarily building production apps and watching API costs closely?
├── YES → Grok 4.1 Fast ($0.20/$0.50) or Grok 4.3 ($1.25/$2.50)
└── NO ↓
Do you work primarily with code, agentic workflows, or complex automation?
├── YES → ChatGPT Plus ($20/mo) — best coding performance in 2026
└── NO ↓
Do you process long documents (>100 pages), video, or audio regularly?
├── YES → Google AI Pro ($19.99/mo) — 2M context, native multimodal
└── NO ↓
Do you do research, scientific writing, or PhD-level analytical work?
├── YES → Google AI Pro ($19.99/mo) — leads GPQA Diamond and ARC-AGI-2
└── NO ↓
Are you primarily a Google Workspace user (Docs, Sheets, Gmail)?
├── YES → Google AI Pro (likely already partly bundled in your Workspace)
└── NO ↓
Default answer for everyone else → ChatGPT Plus ($20/mo)
— Most mature ecosystem, broadest capabilities, safest defaultThe honest take: For 70% of users in 2026, ChatGPT Plus at $20/month remains the right answer. Pick something else only if you have a specific reason — real-time data (Grok), long context (Gemini), or budget API pricing (Grok 4.1 Fast).
Final Verdict — Which One We’d Pick
After running the full comparison across pricing, benchmarks, ecosystem, and capabilities, here’s the honest take:
If we could only use ONE for the next 12 months, we’d pick ChatGPT Plus at $20/month. Not because it wins every category — it doesn’t. Gemini leads reasoning. Grok leads cost. ChatGPT’s edge is breadth: the highest coding scores, the best agentic capabilities, the largest ecosystem, the most mature tooling, and the best general-purpose performance across the widest range of tasks. For 70% of users, it’s the right default.
The exceptions matter, though. If your workflow is fundamentally Google Workspace, Gemini 3.1 Pro through Google AI Pro is the better choice. If you need real-time X data, less-filtered creative output, or you’re building cost-sensitive production apps, Grok is in a different league.
The bigger truth is that the frontier has gotten boring (in a good way). All three models are good enough for the vast majority of real work. The mistake isn’t picking the “wrong” one — it’s spending more time deciding than you’d spend just using one for a week. Pick the one that fits your workflow today. You can always switch in three months when the next major version launches.
Further Reading
- How to Run AI Models Locally & Offline in 2026
- Claude Opus 4.6 vs 4.5: The Missing 4th Model
- OpenAI Codex vs Claude Code: Coding Benchmark
- GPT-5.2 vs Gemini 3 Pro: Earlier 2026 Comparison
- Heretic AI Abliteration Benchmarks (2026) — for open-source model research
Sources used to populate this article (cite these as needed):
- OpenAI GPT-5.5 announcement
- OpenAI Pricing
- Google Gemini API pricing
- xAI documentation and OpenRouter listings for Grok models
- LMSYS Chatbot Arena
- Artificial Analysis

Pingback: 格罗克 vs. ChatGPT vs. Gemini 比较 2026:完整指南(已测试) - 偏执的码农