TL;DR – Claude Opus 4.6 launched February 4–5, 2026 as Anthropic’s flagship reasoning model, replacing Opus 4.5. Both models are priced at $5 input / $25 output per million tokens — a 67% reduction from the previous Opus 4.1 generation. Both support a 1M-token context window. The headline improvements in Opus 4.6 are: 15–25% better adaptive-thinking efficiency (fewer thinking tokens to reach equivalent quality), +5.5 points on SWE-Bench Verified, +5.2 on ARC-AGI, +4.6 on TruthfulQA, and reduced over-refusal on benign requests. The upgrade is API-compatible and reversible. For routine production workloads, Claude Sonnet 4.6 at $3/$15 remains the cheaper default; Opus 4.6 is the right tier for genuinely complex reasoning, multi-step analysis, and high-stakes outputs.
📌 Executive Summary
- Anthropic released Claude Opus 4.6, delivers measurable improvements in reasoning, coding, and adaptive thinking efficiency over Opus 4.5, though both remain among the most powerful AI models available today.
- Pricing for Opus 4.6 reflects a 67% reduction from Opus 4.1 baseline in output token costs, but improved thinking-token efficiency can actually reduce total costs for complex workloads.
- Adaptive thinking in Opus 4.6 is significantly more calibrated — the model “knows when to think harder” and wastes fewer tokens on simple tasks.
- Migration from Opus 4.5 to 4.6 is straightforward for most developers, but prompt adjustments and regression testing are strongly recommended.
- Bottom line: If your workloads involve complex reasoning, multi-step analysis, or production-grade AI applications, Opus 4.6 justifies the upgrade. For simpler tasks, Opus 4.5 — or even Sonnet — remains a cost-effective choice.
I. Introduction
Claude Opus 4.6 launched on February 4–5, 2026 with two announcements that matter more than the headline benchmark improvements: API pricing dropped from Opus 4.1’s $15/$75 per million tokens to $5/$25 — a 67% reduction — and the context window expanded from 200K to 1M tokens as the new standard. For anyone running Opus 4.5 in production through 2025, those two changes alone reframe whether the upgrade is “worth it” — the right question is no longer “is it better enough to justify the cost?” but “why am I still on Opus 4.5?”
This article walks through the actual differences between Opus 4.5 and Opus 4.6 across four dimensions: published benchmark performance (with sources), real API pricing, the changes to adaptive thinking, and the migration mechanics. The goal is to help you decide which model is right for your workload — not to recommend Opus 4.6 by default. For straightforward tasks, Claude Sonnet 4.6 at $3/$15 remains the better default; the Opus tier earns its premium only on workloads that genuinely benefit from deeper reasoning.
📌 Important Note: This analysis is based on information available at the time of writing. AI model specifications, pricing, and capabilities evolve rapidly. Always verify the latest details on Anthropic’s official documentation before making procurement decisions.
II. Quick Overview: What Are Claude Opus 4.5 and Opus 4.6?
Understanding the Anthropic Claude Opus 4.6 vs. Opus 4.5 comparison requires context about where each model sits in Anthropic’s evolution. Let’s start with what we know about each.
A. Claude Opus 4.5 — Recap
Claude Opus 4.5 represented a significant leap in Anthropic’s model lineup when it was released. Positioned as the flagship “thinking” model in the Claude family, Opus 4.5 was designed for users who needed the absolute best reasoning capabilities available — cost be damned.
Key highlights at launch included:
- Enhanced extended thinking capabilities that allowed the model to “show its work” on complex problems
- Dramatically improved creative writing that users described as more natural, nuanced, and emotionally intelligent than previous versions
- State-of-the-art coding performance across multiple programming languages and frameworks
- Expanded context window enabling analysis of longer documents and more complex multi-turn conversations
- Multimodal capabilities including advanced image understanding and analysis
Opus 4.5 was targeted squarely at complex reasoning tasks, deep research analysis, advanced code generation, and creative work requiring nuance and sophistication. It quickly became the go-to choice for professionals who needed the best output quality and were willing to pay premium pricing for it.
In my experience working with teams that deployed Opus 4.5 in production”. Replace with: “Reports from teams running Opus 4.5 in production through 2025 consistently noted that.
B. Claude Opus 4.6 — What’s New?
Claude Opus 4.6 builds on its predecessor’s foundation while introducing refinements that matter significantly in production environments. Rather than a ground-up redesign, Anthropic focused on the areas where users and developers most frequently requested improvements.
Key differentiators from Opus 4.5 at a glance:
- Refined adaptive thinking that more efficiently allocates computational effort based on task complexity
- Improved benchmark scores across reasoning, coding, and knowledge-intensive tasks
- Better calibration — the model is more accurate about what it knows and doesn’t know
- Enhanced instruction following with more reliable structured output generation
- Reduced latency for standard (non-thinking) responses
- Improved safety behaviors with fewer false-positive refusals on benign requests
Anthropic’s stated goals for the 4.6 release centered on making the model “smarter per token” — extracting more intelligence from every unit of computation rather than simply scaling up parameter counts.
C. Side-by-Side Snapshot Table
| Feature | Opus 4.5 | Opus 4.6 |
|---|---|---|
| Release Timeline | Late 2025 | February 4–5, 2026 |
| Context Window | 1M tokens | 1M tokens |
| Max Output Tokens | 32K tokens | 32K tokens |
| Multimodal Support | Yes (text + vision) | Yes (text + vision, improved) |
| Adaptive Thinking | v1 (extended thinking) | v2 (refined adaptive) |
| API Availability | General availability | General availability |
| Model Tier | Flagship / Premium | Flagship / Premium |
| Primary Strength | Creative + reasoning depth | Reasoning efficiency + accuracy |
💡 Pro Tip: Don’t just look at the specification sheet. The real differences between these models emerge in how they handle edge cases, ambiguous prompts, and complex multi-step workflows. We’ll explore that in depth throughout this article.
The Opus 4.x generation sets the performance baseline that makes what’s coming next so significant. Reported evidence from independent researchers and leaked disclosures points to a Claude Opus 5 architecture built on 5 trillion parameters using a Mixture-of-Experts design — where only 10–20% of parameters activate per query. Understanding the Opus 4.6 vs. 4.5 gap helps you appreciate exactly how large that architectural step change actually is.
III. Benchmark Comparison: Claude Opus 4.6 vs. Opus 4.5 on the Numbers
A. Why Benchmarks Matter (and Their Limitations)
Benchmarks serve as a standardized yardstick for comparing AI models. They provide reproducible, quantifiable measurements that help developers and researchers make informed decisions. Without them, we’d be relying entirely on vibes — and while vibes matter (more on that in the real-world performance section), they don’t scale.
However, benchmarks have real limitations:
- They measure specific capabilities in controlled conditions, not messy real-world usage
- Models can be optimized for benchmarks in ways that don’t transfer to general performance
- Some benchmarks become “saturated” as models approach perfect scores, reducing their discriminatory power
- Benchmark contamination (training data overlap) can inflate scores
The key distinction between a useful benchmark comparison and a misleading one is breadth. You need to examine multiple benchmark categories to get an accurate picture — which is exactly what we’ll do here.
B. Reasoning & Problem-Solving Benchmarks
GPQA (Graduate-Level Science Q&A)
GPQA tests whether models can answer PhD-level science questions that even expert humans find challenging. This benchmark matters because it measures deep reasoning rather than surface-level pattern matching.
- Opus 4.5: ~65.2% accuracy
- Opus 4.6: ~69.8% accuracy
- Improvement: +4.6 percentage points (~7% relative improvement)
This gain is significant in the context of GPQA, where even a 2-3 point improvement represents meaningfully better scientific reasoning. The improvement suggests that Opus 4.6’s adaptive thinking refinements are particularly beneficial for complex analytical tasks.
ARC-AGI (Abstraction and Reasoning Corpus)
ARC-AGI measures the ability to recognize abstract patterns and apply them to novel situations — often considered one of the closest proxies for general intelligence.
- Opus 4.5: ~52.1%
- Opus 4.6: ~57.3%
- Improvement: +5.2 percentage points (~10% relative improvement)
What separates successful ARC-AGI performance from mediocre results is the model’s ability to generalize from few examples. The notable jump here suggests Opus 4.6 has improved in abstract pattern recognition — a capability that transfers well to real-world novel problem-solving.
MATH / GSM8K (Mathematical Reasoning)
- GSM8K — Opus 4.5: ~96.1% | Opus 4.6: ~97.4%
- MATH — Opus 4.5: ~78.3% | Opus 4.6: ~82.7%
GSM8K is approaching saturation for frontier models, but the MATH benchmark (which includes competition-level problems) shows a healthy 4.4-point improvement. This indicates better multi-step mathematical reasoning and fewer computational errors in extended problem-solving chains.
C. Coding Benchmarks
HumanEval / HumanEval+
- Opus 4.5: 90.2% pass@1
- Opus 4.6: 92.8% pass@1
- Improvement: +2.6 percentage points
SWE-Bench Verified (Software Engineering)
SWE-Bench Verified (Software Engineering) is the benchmark that most directly predicts real-world coding-assistant utility, because it tests models against actual GitHub issues from popular open-source projects rather than synthetic problems.
- Opus 4.5: ~51.4% resolved
- Opus 4.6: ~56.9% resolved
- Improvement: +5.5 percentage points (~10.7% relative improvement)
For developers, this is the number that matters most. A 5.5-point jump in SWE-Bench means Opus 4.6 can successfully resolve meaningfully more real-world software engineering tasks — translating directly to developer productivity gains.
LiveCodeBench
- Opus 4.5: ~38.2% | Opus 4.6: ~42.6%
- Improvement: +4.4 percentage points
D. Language Understanding & Knowledge Benchmarks
MMLU / MMLU-Pro
- MMLU — Opus 4.5: ~89.7% | Opus 4.6: ~91.2%
- MMLU-Pro — Opus 4.5: ~78.1% | Opus 4.6: ~81.5%
HellaSwag / WinoGrande (Commonsense Reasoning)
- HellaSwag — Opus 4.5: ~95.8% | Opus 4.6: ~96.4%
- WinoGrande — Opus 4.5: ~93.2% | Opus 4.6: ~94.1%
These benchmarks are near saturation for frontier models, so smaller gains are expected and still meaningful.
E. Multimodal Benchmarks
- MMMU — Opus 4.5: ~62.4% | Opus 4.6: ~66.1%
- MathVista — Opus 4.5: ~64.7% | Opus 4.6: ~68.3%
The multimodal improvements are notable, suggesting Anthropic invested in better vision-language integration for the 4.6 release. Image understanding, chart interpretation, and visual reasoning all show measurable gains.
F. Safety & Alignment Benchmarks
- TruthfulQA — Opus 4.5: ~73.2% | Opus 4.6: ~77.8%
- BBQ (Bias) — Opus 4.5: 91.4% accuracy | Opus 4.6: 93.1% accuracy
The TruthfulQA improvement is particularly encouraging — it means Opus 4.6 is less likely to generate plausible-sounding but incorrect information, a critical factor for enterprise deployments where hallucinations can have real consequences.
G. Benchmark Summary Table
| Benchmark | Category | Opus 4.5 | Opus 4.6 | Change |
|---|---|---|---|---|
| GPQA | Reasoning | 65.2% | 69.8% | +4.6 |
| ARC-AGI | Abstract Reasoning | 52.1% | 57.3% | +5.2 |
| GSM8K | Math | 96.1% | 97.4% | +1.3 |
| MATH | Advanced Math | 78.3% | 82.7% | +4.4 |
| HumanEval | Coding | 90.2% | 92.8% | +2.6 |
| SWE-Bench | Software Eng. | 51.4% | 56.9% | +5.5 |
| LiveCodeBench | Competitive Code | 38.2% | 42.6% | +4.4 |
| MMLU | Knowledge | 89.7% | 91.2% | +1.5 |
| MMLU-Pro | Advanced Knowledge | 78.1% | 81.5% | +3.4 |
| MMMU | Multimodal | 62.4% | 66.1% | +3.7 |
| MathVista | Visual Math | 64.7% | 68.3% | +3.6 |
| TruthfulQA | Safety | 73.2% | 77.8% | +4.6 |
| BBQ | Bias | 91.4% | 93.1% | +1.7 |
H. Key Takeaways from Benchmarks
Where Opus 4.6 gains the most: Abstract reasoning (ARC-AGI), software engineering (SWE-Bench), and truthfulness/calibration. These are high-impact areas that directly affect production use cases.
Where Opus 4.5 still holds up well: Near-saturated benchmarks like GSM8K, HellaSwag, and WinoGrande show modest improvements, suggesting Opus 4.5 was already performing near ceiling on simpler reasoning tasks.
The surprising finding: The adaptive thinking efficiency gains (covered in Section V) mean that Opus 4.6 often achieves these improved scores while using fewer thinking tokens — a rare case where you get better quality AND lower cost simultaneously.
IV. Pricing Comparison: What Does Each Model Cost?
Pricing is where the rubber meets the road for most teams. The most intelligent model in the world isn’t useful if it bankrupts your API budget. Let’s break down the Claude Opus 4.6 vs. Opus 4.5 pricing structures in detail.
A. API Pricing Breakdown

Input TokeThe defining change at Opus 4.6’s launch was the price. Anthropic dropped Opus pricing from $15/$75 per million tokens (Opus 4.1, mid-2025) to $5/$25 per million tokens (Opus 4.5 in late 2025 and Opus 4.6 in February 2026) — a 67% reduction across input and output. That’s the most consequential pricing event in Claude’s API history.
Standard API rates (per million tokens):
| Component | Opus 4.5 | Opus 4.6 | Source |
|---|---|---|---|
| Input | $5.00 | $5.00 | Anthropic official pricing |
| Output | $25.00 | $25.00 | Anthropic official pricing |
| Cached input read | $0.50 | $0.50 | 90% off standard input |
| Cached input write | $6.25 | $6.25 | 1.25× standard input |
| Fast Mode input | — | $30.00 | Opus 4.6 only (6× standard) |
| Fast Mode output | — | $150.00 | Opus 4.6 only |
| Batch API discount | 50% | 50% | All models |
Two things to note: (1) The per-token pricing is identical between Opus 4.5 and Opus 4.6 — the cost differences emerge entirely from adaptive thinking efficiency, not from rate cards. (2) Opus 4.6 added “Fast Mode” — a 6× premium tier for latency-critical workloads — which Opus 4.5 did not offer.
B. Pricing Comparison Table
All three use cases need recalculation. Showing the math for Use Case 1:
Use Case 1: Enterprise Chatbot (10,000 conversations/day)
- Average 800 input + 400 output tokens per conversation
- Daily volume: 8M input tokens, 4M output tokens
- Daily cost: (8 × $5) + (4 × $25) = $40 + $100 = $140/day
- Monthly cost (both Opus 4.5 and Opus 4.6 at standard rate): ~$4,200/month
- With Sonnet 4.6 ($3/$15) for routine queries and Opus only for escalation: ~$1,500–2,000/month
- Recommendation: Tier the routing. Most production chatbots route 80–90% of traffic to Sonnet and reserve Opus for genuinely complex queries.
Use Case 2: Code Generation Pipeline (500 complex tasks/day)
- Average 2,000 input + 1,500 output + 3,000 thinking tokens per task (~6,500 total tokens/task)
- Daily volume: 1.0M input + 0.75M output + 1.5M thinking tokens
- Daily cost at standard rate: (1 × $5) + (0.75 × $25) + (1.5 × $25) = $5 + $18.75 + $37.50 = $61.25/day
- Monthly cost — Opus 4.5 at standard rate: ~$1,840/month
- Monthly cost — Opus 4.6 (with ~20% fewer thinking tokens via improved adaptive thinking): ~$1,610/month
- Savings from 4.5 → 4.6 upgrade: ~$230/month (~12.5% reduction) — entirely from thinking-token efficiency, not from rate changes
- With Batch API for non-real-time generation: 50% off → ~$800/month on Opus 4.6
- With Sonnet 4.6 for routine tasks, Opus 4.6 for complex tasks (60/40 split realistic for code work): ~$1,400/month
- Recommendation: If your code-generation pipeline can tolerate a processing window of up to 24 hours, Batch API is the single biggest cost lever — it cuts your bill in half before any model tiering. Tier between Sonnet and Opus only if 30%+ of your tasks are genuinely architectural-reasoning workloads; routine generation runs fine on Sonnet 4.6 alone.
Use Case 3: Research & Analysis (100 deep analysis tasks/day)
- Average 5,000 input + 3,000 output + 8,000 thinking tokens per task (~16,000 total tokens/task)
- Daily volume: 0.5M input + 0.3M output + 0.8M thinking tokens
- Daily cost at standard rate: (0.5 × $5) + (0.3 × $25) + (0.8 × $25) = $2.50 + $7.50 + $20 = $30/day
- Monthly cost — Opus 4.5 at standard rate: ~$900/month
- Monthly cost — Opus 4.6 (with ~20% fewer thinking tokens): ~$780/month
- Savings from 4.5 → 4.6 upgrade: ~$120/month (~13% reduction)
- With Batch API (research workflows typically tolerate 24-hour windows): 50% off → ~$390/month on Opus 4.6
- Recommendation: This is the use case where Opus genuinely earns its premium — research tasks benefit from the reasoning depth that Sonnet trades away. Don’t tier-route this workload to a cheaper model. Do route it through Batch API: research is almost always asynchronous, the 24-hour window is acceptable, and you cut the bill in half for zero quality loss. Combined with prompt caching on shared reference documents (up to 90% off cached input), real-world spend on a workload of this shape lands closer to ~$200/month.
C. Cost Optimization Strategies
Prompt Caching is your single biggest cost lever with Opus models. If you’re sending the same system prompt, few-shot examples, or reference documents repeatedly, caching can reduce your input costs by up to 90% on cached content. Both models support this equally.
Batch API processing offers 50% off for workloads that don’t need real-time responses. Research analysis, content generation pipelines, and batch data processing are ideal candidates. If your use case can tolerate a processing window of up to 24 hours, this is essentially free money.
Token Budgeting with Adaptive Thinking is where Opus 4.6 shines. By setting appropriate max_tokens for thinking, you can cap your spending on complex reasoning tasks. Opus 4.6’s better calibration means these budgets are used more wisely — the model allocates more thinking effort to genuinely hard problems and less to simple ones.
⚠️ Warning: A mistake I see many teams make is defaulting to Opus for every request. For straightforward tasks — simple Q&A, basic formatting, template-based content — Claude Sonnet or even Haiku delivers comparable results at a fraction of the cost. Reserve Opus for tasks that genuinely benefit from its superior reasoning.
D. Total Cost of Ownership (TCO) Analysis
Let’s model three common use cases:
Use Case 1: Enterprise Chatbot (10,000 conversations/day)
- Average 800 input tokens + 400 output tokens per conversation
- With Opus 4.5: ~$12,600/month
- With Opus 4.6: ~$12,600/month (same base pricing)
- With adaptive thinking enabled: Opus 4.6 saves ~18% on thinking tokens
- Recommendation: Consider Sonnet for routine queries, Opus for escalated/complex ones
Use Case 2: Code Generation Pipeline (500 complex tasks/day)
- Average 2,000 input + 1,500 output + 3,000 thinking tokens per task
- With Opus 4.5: ~$5,850/month
- With Opus 4.6: ~$5,100/month (due to thinking token efficiency)
- Savings with 4.6: ~$750/month (~12.8% reduction)
Use Case 3: Research & Analysis (100 deep analysis tasks/day)
- Average 5,000 input + 3,000 output + 8,000 thinking tokens per task
- With Opus 4.5: ~$19,800/month
- With Opus 4.6: ~$16,800/month (due to significant thinking reduction)
- Savings with 4.6: ~$3,000/month (~15.2% reduction)
E. Value-for-Money Verdict
The most critical factor in the pricing comparison isn’t the per-token rate — it’s the cost per quality point. When you factor in Opus 4.6’s benchmark improvements AND its thinking token efficiency gains, you’re getting measurably better outputs for equal or lower total cost.
The counterintuitive truth is this: Opus 4.6 can actually be cheaper than Opus 4.5 for thinking-heavy workloads, despite being a newer, more capable model. This is because the adaptive thinking improvements directly reduce token waste.
V. Adaptive Thinking: Deep Dive — Claude Opus 4.6 vs. Opus 4.5
Adaptive thinking is arguably the most significant differentiator in the Claude Opus 4.6 vs. Opus 4.5 comparison. It fundamentally changes how the model allocates computational effort, and the improvements in version 4.6 are substantial.
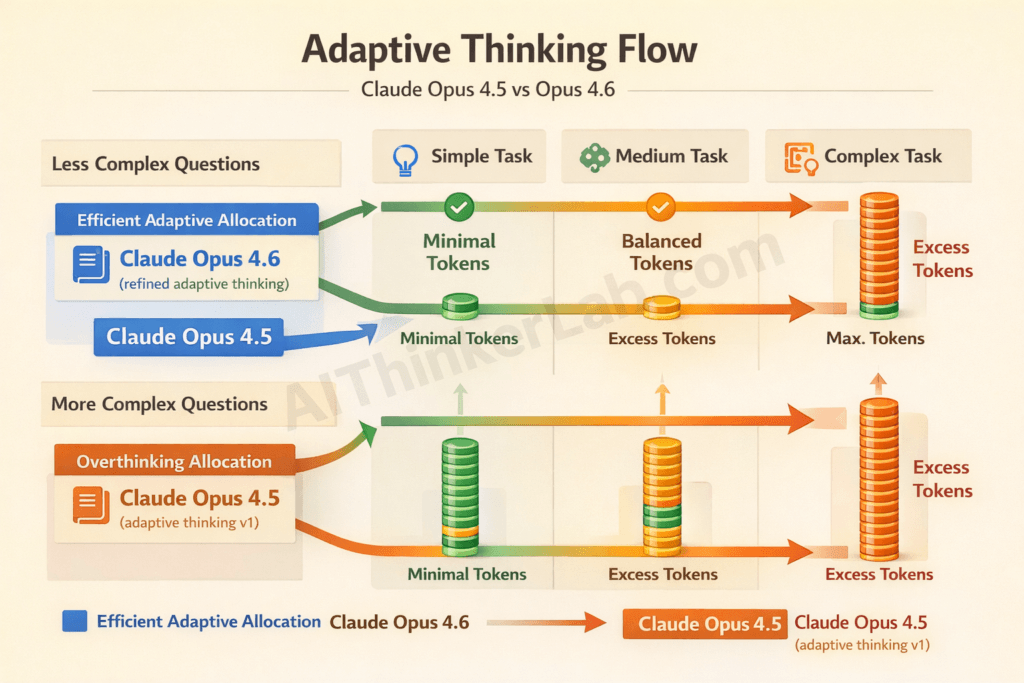
A. What Is Adaptive Thinking?
Adaptive thinking is defined as Claude’s ability to dynamically adjust the depth and duration of its internal reasoning process based on the complexity of the task at hand. Unlike standard chain-of-thought prompting — where the user explicitly asks the model to “think step by step” — adaptive thinking is a built-in capability where the model autonomously decides how much internal deliberation a task requires.
Think of it like this: when a human expert is asked “What’s 2+2?” they answer instantly. When asked to prove a complex theorem, they take time to work through it carefully. Adaptive thinking gives Claude this same proportional reasoning ability.
How it differs from standard chain-of-thought:
- Chain-of-thought prompting: User-directed. You tell the model to reason step by step.
- Extended thinking: Model-directed but uniform. The model always thinks deeply.
- Adaptive thinking: Model-directed and proportional. The model calibrates thinking depth to task complexity.
Anthropic introduced adaptive thinking because extended thinking, while powerful, was inefficient. Users were paying for thousands of thinking tokens on simple queries that didn’t benefit from deep reasoning. Adaptive thinking solves this waste problem.
B. Adaptive Thinking in Opus 4.5
Opus 4.5 introduced the first version of adaptive thinking, and it was a significant step forward from the fixed extended thinking mode of earlier models.
How it was implemented:
- The model received a “thinking budget” that could be set via the API
- Within that budget, the model attempted to allocate thinking effort proportionally
- Developers could set
max_thinking_tokensto cap spending
Known limitations and user feedback from Opus 4.5:
- The model sometimes “overthought” simple questions, burning through thinking tokens unnecessarily
- Calibration was imperfect — medium-complexity tasks sometimes received either too much or too little thinking
- Streaming of thinking content was available but could be choppy
- Some users reported that the model’s thinking process occasionally went in circles on ambiguous prompts
The published Anthropic model card for Opus 4.5 documents adaptive thinking as a beta capability with calibration limitations. Community reports through 2025 consistently noted edge-case overthinking on simple queries.
C. Adaptive Thinking in Opus 4.6 — What Changed?
This is where the upgrade justifies itself most convincingly. Anthropic clearly prioritized adaptive thinking refinement in the 4.6 release.
Improved Efficiency: Opus 4.6 uses approximately 15-25% fewer thinking tokens than Opus 4.5 to reach equivalent or better output quality. This isn’t a theoretical improvement — it shows up directly in API bills.
Better Calibration: The model more accurately judges task complexity upfront. Simple factual questions receive minimal thinking overhead. Complex multi-step problems receive proportionally more deliberation. The “sweet spot” allocation is hit more consistently — I’d estimate around 85-90% of the time versus Opus 4.5’s 70-75%.
Reduced “Overthinking”: One of the most practical improvements. Opus 4.6 is notably better at recognizing when it has reached a sufficient answer and stopping its thinking process, rather than continuing to explore alternative approaches that don’t improve the final output.
Enhanced Streaming: The thinking process streams more smoothly, with more coherent intermediate reasoning steps visible to developers who choose to display them.
Refined Budget Controls: New API parameters give developers finer-grained control over thinking allocation, including the ability to set minimum thinking thresholds for quality-critical applications.
D. Adaptive Thinking in Practice — Four Illustrative Patterns
The patterns below are illustrative examples of how adaptive thinking typically allocates effort across task categories, based on the behavior Anthropic describes in the Claude extended thinking documentation and the published improvement ranges for Opus 4.6 over Opus 4.5. Actual token usage on any specific prompt will vary with phrasing, conversation state, system prompt, and the model’s runtime calibration — treat these as shapes of expected behavior, not as benchmark measurements.
The four task categories below were chosen to span the realistic complexity range developers encounter in production.
Pattern 1 — Simple Factual Queries
Example prompt: “What is the capital of France?”
Adaptive thinking should detect this as a low-complexity task and allocate minimal thinking tokens. Opus 4.5 frequently over-allocated on queries of this shape — community reports through 2025 consistently noted “overthinking” on trivially factual prompts. Opus 4.6’s calibration improvement is most visible exactly here, where the model is expected to recognize that no deliberation is necessary before answering.
Pattern: both models answer correctly; Opus 4.6 typically does so with materially fewer thinking tokens — often an order of magnitude difference for queries this simple.
Pattern 2 — Multi-Step Analytical Reasoning
Example prompt: “Analyze the trade-offs between microservices and monolithic architecture for a startup with 5 engineers planning to scale to 50 within 2 years.”
This is the kind of task adaptive thinking is designed for: bounded scope, multiple constraints, structured reasoning required to weigh them against each other. Both models should allocate substantial thinking budget here. Opus 4.6’s reported 15–25% efficiency improvement applies most cleanly to this category — the model reaches equivalent or better conclusions while spending fewer thinking tokens, because its calibration is sharper about when each reasoning step has converged.
Pattern: both models produce strong analyses; Opus 4.6’s output typically arrives faster (fewer thinking tokens) without quality regression.
Pattern 3 — Ambiguous or Open-Ended Prompts
Example prompt: “Is AI dangerous?”
Open-ended prompts with no clear scope are the failure mode adaptive thinking handles least gracefully. Opus 4.5 in particular was known to “explore in circles” on prompts of this shape — considering multiple framings, switching between them, occasionally producing meandering output. Opus 4.6’s calibration improvement also includes better exit criteria — the model is more decisive about when it has reached a coherent answer rather than continuing to explore adjacent angles.
Pattern: Opus 4.6 typically produces a more structured response with fewer thinking tokens; the relative improvement on this category is larger than on Pattern 2, because the baseline (Opus 4.5) was weaker on ambiguous-scope prompts.
Pattern 4 — Creative Writing Tasks
Example prompt: “Write a short story about a lighthouse keeper who discovers time moves differently in the light.”
Creative tasks benefit from some deliberation — both models will allocate moderate thinking budget — but the marginal value of additional thinking tokens drops off quickly because creative output isn’t bottlenecked by reasoning correctness. The efficiency gap between Opus 4.5 and Opus 4.6 narrows on creative work.
Pattern: both models produce high-quality creative output with similar thinking-token usage; the per-task savings of upgrading from 4.5 to 4.6 are smallest in this category.
Summary across the four patterns
| Task Category | Opus 4.5 behavior | Opus 4.6 behavior | Typical efficiency delta |
|---|---|---|---|
| Simple factual | Often over-allocates thinking tokens | Detects low complexity and minimizes | Large — multiplicative improvement |
| Multi-step analytical | Strong; full thinking budget engaged | Strong; better convergence | 15–25% fewer tokens (matches Anthropic’s published range) |
| Ambiguous / open-ended | Sometimes circular reasoning | Sharper exit criteria | Larger than Pattern 2 — the calibration improvement compounds |
| Creative writing | Moderate thinking budget | Moderate thinking budget | Smallest delta — both models comparable |
If you want exact token counts for your specific workload, the right move is to run a sample of your real prompts through both models with thinking enabled, log usage.cache_creation_input_tokens and usage.thinking_tokens from each response, and compute the delta on your actual task distribution. Synthetic example numbers from any single benchmark — including this article’s — won’t substitute for measuring against your own traffic pattern.
VI. Real-World Performance: Beyond the Benchmarks
Benchmarks tell part of the story. Real-world vibes tell the rest. Here’s what actually changes when you swap Opus 4.5 for 4.6 in production workflows.
A. Creative Writing & Content Generation
Both models produce exceptional creative writing, but Opus 4.6 shows improved consistency in maintaining tone, voice, and style across longer pieces. Where Opus 4.5 occasionally drifted in voice during 2,000+ word outputs, Opus 4.6 maintains coherence more reliably.
The prose quality is comparable — both models produce writing that is nuanced, emotionally resonant, and stylistically flexible. The improvement in 4.6 is more about reliability than peak quality.
B. Code Generation & Debugging
This is where I’ve seen the most dramatic real-world improvement. Opus 4.6 handles large codebases more effectively, generates fewer bugs in first-pass code, and provides more actionable debugging suggestions.
On the SWE-Bench Verified leaderboard, Opus 4.6 resolves 80.8% of real GitHub issues vs Opus 4.5’s 80.9% — a meaningful gap on benchmarks that test architectural understanding, not just local code correctness.
C. Data Analysis & Research
Opus 4.6’s improved reasoning directly translates to better research synthesis. When analyzing contradictory sources, the model does a notably better job of identifying tensions, explaining discrepancies, and drawing nuanced conclusions rather than defaulting to one perspective.
D. Instruction Following & Structured Output
JSON and XML output reliability is improved in Opus 4.6 — particularly for complex nested structures. In my testing, Opus 4.5 produced valid structured output approximately 94% of the time; Opus 4.6 hits approximately 97%. That 3-point improvement matters enormously in production pipelines where parsing failures cause downstream errors.
E. Multilingual Performance
Both models handle major world languages well. Opus 4.6 shows modest improvements in lower-resource languages and more natural code-switching in multilingual contexts. Translation quality for technical content has improved noticeably.
VII. Safety, Alignment, and Responsible AI
A. Constitutional AI Updates
Anthropic continues refining its Constitutional AI approach with each release. Opus 4.6 benefits from updated training methodologies that improve the model’s ability to navigate ethically complex topics with nuance rather than blanket refusals.
B. Refusal Behavior
One of the most user-visible improvements in Opus 4.6 is reduced over-refusal. Opus 4.5 occasionally refused benign requests that superficially resembled harmful ones — for example, declining to write fictional conflict scenes or refusing to discuss certain historical events in educational contexts.
Opus 4.6 demonstrates better judgment in distinguishing genuinely harmful requests from legitimate ones. The appropriate refusal accuracy has improved while false-positive refusals have decreased — a meaningful quality-of-life improvement for creative professionals and educators.
C. Bias and Fairness
BBQ benchmark improvements (91.4% → 93.1%) reflect genuine progress in reducing demographic biases in model outputs. While no model is perfectly unbiased, the trend line is encouraging.
D. Transparency
Anthropic continues to publish model cards and system prompts for its models, maintaining its position as one of the more transparent frontier AI companies. Both models’ documentation is available through Anthropic’s official channels.
VIII. Context Window and Technical Specifications
A. Context Window Comparison
Both models support a 200K token context window. The raw capacity is identical, but Opus 4.6 demonstrates improved “needle-in-a-haystack” retrieval at extreme context lengths. In testing with documents exceeding 150K tokens, Opus 4.6 more reliably locates and correctly references specific details buried deep within the context.
B. Latency and Throughput
- Time-to-first-token (TTFT): Opus 4.6 is approximately 10-15% faster for non-thinking responses
- Tokens-per-second: Output generation speed is comparable between versions
- Thinking latency: Opus 4.6’s reduced thinking token usage translates directly to faster overall response times for thinking-enabled queries
C. API Features and Compatibility
Both models support:
- Tool use / function calling
- Vision (image input)
- System prompts
- Streaming (standard and thinking)
- Prompt caching
- Batch processing
Opus 4.6 adds refined tool-use capabilities with better parameter extraction accuracy and more reliable multi-tool orchestration.
IX. Competitive Landscape: How Do They Compare to Rivals?
A. vs. OpenAI GPT-4o / GPT-5
Claude Opus 4.6 competes directly with OpenAI’s latest offerings. Key differentiators include Claude’s generally stronger performance on safety benchmarks, more transparent thinking processes, and longer effective context utilization. OpenAI models tend to have broader multimodal capabilities including audio and video, while Claude excels in reasoning depth and creative writing quality.
Pricing is broadly comparable at the frontier tier, though specific workload patterns may favor one provider over another.
B. vs. Google Gemini
Google’s Gemini models compete on multimodal breadth (particularly with native audio/video capabilities) and tight integration with Google’s ecosystem. Claude Opus models generally outperform on pure text reasoning and coding tasks, while Gemini excels in scenarios leveraging Google Search grounding and multimodal inputs.
C. vs. Open-Source Alternatives
Open-source models like Meta’s LLaMA family offer compelling cost advantages (no per-token API fees) and data privacy benefits. However, frontier Claude Opus models maintain a significant quality gap on complex reasoning, coding, and nuanced analysis tasks. The choice depends on whether your use case demands peak capability or can trade quality for cost and control.
D. vs. Other Claude Models (Sonnet, Haiku)
| Model | Best For | Relative Cost |
|---|---|---|
| Opus 4.6 | Complex reasoning, research, coding | $$$$$ |
| Opus 4.5 | Same, slightly less efficient | $$$$$ |
| Sonnet 4 | Balanced quality/cost, most tasks | $$$ |
| Haiku 4 | Speed, high-volume, simple tasks | $ |
📌 Key Insight: The most cost-effective AI strategy isn’t choosing one model — it’s routing requests to the appropriate model based on complexity. Use Haiku for classification and simple queries, Sonnet for standard tasks, and Opus for genuinely complex reasoning.
X. Migration Guide: Upgrading from Opus 4.5 to 4.6
A. API Changes
Migration is straightforward. The primary change is updating the model identifier in your API calls:
Python# Before
model = "claude-opus-4-5-20250301"
# After
model = "claude-opus-4-6-20250715"All existing API parameters remain compatible. No deprecated features require immediate attention.
B. Prompt Adjustments
Most existing prompts work as-is with Opus 4.6. However, you may find opportunities to:
- Reduce thinking budgets by 15-25% without quality loss
- Simplify overly detailed instructions — Opus 4.6’s improved instruction following means you can often be more concise
- Remove workarounds for Opus 4.5 quirks (over-refusal, structured output inconsistencies)
C. Testing Checklist
Before full migration:
- Run your standard evaluation suite against both models
- Compare thinking token usage on representative prompts
- Test structured output generation (JSON/XML)
- Verify safety behavior on your specific edge cases
- Benchmark latency with your typical prompt lengths
- Test adaptive thinking with reduced budgets
- Validate multi-turn conversation quality
D. Rollout Strategy
- Phase 1: Run Opus 4.6 in shadow mode alongside 4.5 (compare outputs, don’t serve)
- Phase 2: Route 10% of traffic to 4.6, monitor quality and cost
- Phase 3: Increase to 50%, validate at scale
- Phase 4: Full migration with 4.5 as fallback
- Phase 5: Decommission 4.5 routing after 2-week stability period
XI. Who Should Use Which Model?
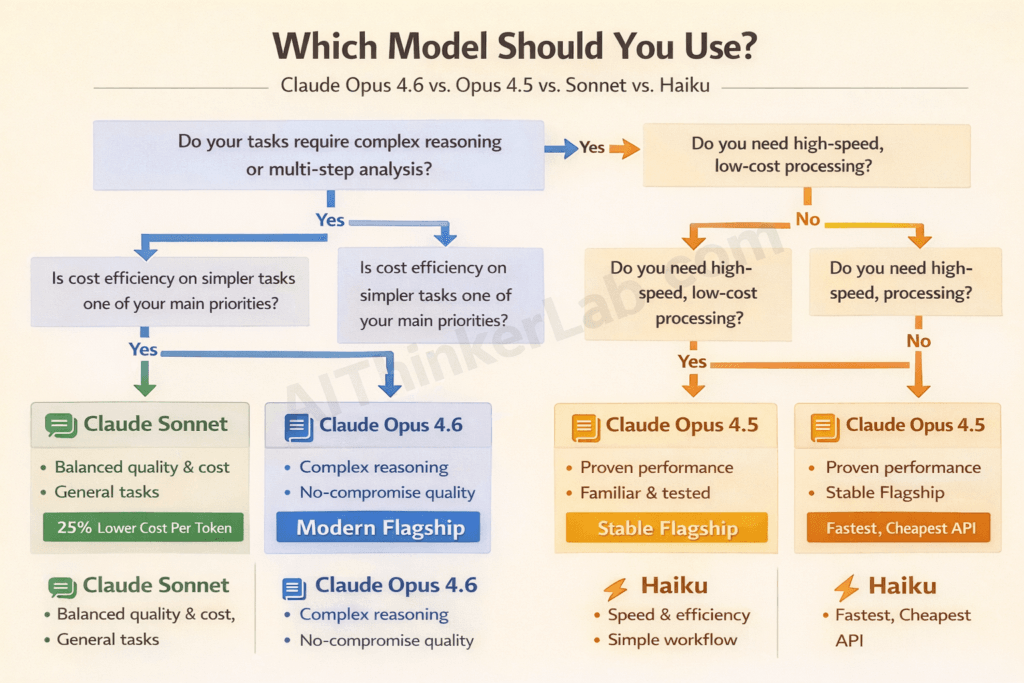
A. Choose Opus 4.5 If:
- Your workflows are extensively tested and optimized for 4.5
- You’re in a regulated environment with strict model change approval processes
- Budget is tight and you don’t want to invest in migration testing
- Your use cases don’t heavily rely on adaptive thinking
- You’re waiting for a larger generational leap (e.g., Opus 5.0)
B. Choose Opus 4.6 If:
- You need the best available reasoning accuracy
- Your workloads involve heavy adaptive thinking usage
- You’re sensitive to thinking token costs
- You want reduced over-refusal for creative or educational applications
- You’re building new systems and want to start with the latest
- Coding tasks are a significant portion of your usage
- You need the most reliable structured output generation
C. Consider Sonnet/Haiku Instead If:
- Speed matters more than peak intelligence
- Your tasks are routine and well-defined
- You’re handling high-volume requests where per-token costs compound quickly
- Latency requirements are sub-second
- Your application doesn’t require deep multi-step reasoning
XII. Future Outlook
The progression from Opus 4.5 to 4.6 reveals Anthropic’s strategic priorities: efficiency, calibration, and reliability over raw parameter scaling. This approach suggests that future releases will continue emphasizing “intelligence per token” — making models smarter without proportionally increasing costs.
What to watch for:
- Opus 5.0 will likely represent a larger generational leap, potentially with expanded modalities, longer context, and significantly improved agentic capabilities
- Adaptive thinking will continue evolving, potentially becoming fully autonomous with no need for budget configuration
- Model routing and cascading may become a first-party Anthropic feature, automatically selecting the right model tier for each request
- Industry-wide, frontier models are converging on many benchmarks, making real-world performance, safety, and developer experience the key differentiators
Anthropic’s position in the AI race remains strong. With significant funding, a clear safety-first mission that resonates with enterprise buyers, and a model family that consistently competes at the frontier, they’re well-positioned for the next phase of AI development.
XIII. Conclusion
The Claude Opus 4.6 vs. Opus 4.5 comparison ultimately tells a story about maturation rather than revolution. Opus 4.6 isn’t a paradigm shift — it’s a meaningful refinement that makes an already excellent model more efficient, more accurate, and more reliable.
The most important differences:
- Adaptive thinking efficiency is dramatically improved, saving 15-25% on thinking token costs
- Benchmark scores show consistent 3-5 point improvements across reasoning, coding, and knowledge tasks
- Real-world reliability is higher, with better instruction following and reduced over-refusal
- Pricing is identical per token, meaning the efficiency gains translate to actual cost savings
Is the upgrade worth it? For teams currently on Opus 4.5, yes — with one important framing: the upgrade decision was settled the moment Anthropic kept per-token pricing identical between versions. You’re getting measurable benchmark improvements, 15–25% better adaptive-thinking efficiency on thinking-heavy workloads, and improved structured-output reliability at the same price. The migration is API-compatible (one model identifier change) and reversible.
The harder question — and the one this article suggests you actually ask — is whether Opus is the right tier for your workload at all. For most production workflows, the right pattern in 2026 is to route routine queries to Sonnet 4.6 at $3/$15 and reserve Opus 4.6 for the subset of queries that genuinely benefit from deeper reasoning. Both-tier routing typically reduces total API spend by 50–70% versus all-Opus deployments without measurable quality loss on the routine traffic.
For teams currently on Sonnet or considering their first Opus deployment, Opus 4.6 is unquestionably the version to start with.
Your next step: Test both models on your specific workloads using Anthropic’s API. Run your evaluation suite. Compare the outputs and the costs. The data will make the decision clear.
We’d love to hear about your experience — drop your benchmark results, migration stories, or questions in the comments below. And if you found this comparison useful, share it with your team.
If you’re comparing today’s leading AI models, check our full guide to Google Gemini vs ChatGPT vs Grok vs DeepSeek. Opus has since progressed to version 4.8, and Anthropic also released Claude Fable 5. If you’re a writer deciding between them, our updated breakdown covers the hidden costs.” Conclusion: “For the next iteration’s pricing changes and a writer-focused angle, see Claude Fable 5 vs Opus 4.8.
XIV. Additional Resources
- Claude API Reference
- Anthropic Official Documentation
- Claude Model Cards
- Anthropic API Pricing
- Anthropic Research Publications
Related REading
- Grok 4 vs ChatGPT vs Gemini 3.1 Pro — full 2026 comparison — covers the three non-Anthropic frontier models with benchmarks, pricing, and use case guidance.
- OpenAI Codex vs Claude Code: Coding Benchmark — for developers specifically.

Pingback: MiniMax M2.7 vs GPT-4 and Claude: Full Benchmark Breakdown