what you’ll learn in this guide
📌 Key Takeaways:
- Google Sequential Attention is a breakthrough attention mechanism that reduces computational complexity from O(n²) to O(n), enabling up to 60% more efficient AI model processing
- Unlike traditional transformers that process all tokens simultaneously, sequential attention processes information in ordered stages while maintaining context quality
- The technology addresses AI’s growing sustainability crisis, potentially reducing data center energy consumption by billions of kilowatt-hours annually
- Early benchmarks show comparable accuracy to standard transformers with significantly faster inference times and lower memory requirements
- Expected to be integrated into Google Search, Gemini, and enterprise AI products throughout 2026-2027
Introduction
Here’s a staggering reality: training a single large language model today consumes as much energy as five cars use over their entire lifetimes. According to MIT Technology Review, AI’s computational demands are doubling every 3.4 months—a trajectory that’s simply unsustainable. Google Sequential Attention represents the most significant architectural breakthrough in addressing this crisis since the transformer’s introduction in 2017.
The evolution of attention mechanisms has been AI’s defining narrative. From the revolutionary “Attention Is All You Need” paper that birthed modern transformers, to innovations like sparse attention and flash attention, researchers have continuously sought to overcome the fundamental bottleneck: quadratic computational complexity. Every time you double the input length, processing requirements quadruple.
Google DeepMind’s Sequential Attention algorithm fundamentally reimagines this paradigm. Rather than computing attention scores between every possible token pair simultaneously, sequential attention introduces a state-based processing pipeline that achieves linear complexity without sacrificing the contextual understanding that makes transformers powerful.
Why does this matter for AI’s future? The sequential attention mechanism could be the difference between AI remaining a tool for well-funded tech giants and becoming genuinely accessible to researchers, startups, and organizations worldwide. It’s the difference between sustainable AI development and an environmental catastrophe in the making.
In this comprehensive guide, you’ll learn exactly how Google Sequential Attention works, why it represents a paradigm shift in AI architecture, how it compares to existing solutions, and what it means for developers, businesses, and the broader AI ecosystem. Whether you’re a machine learning engineer evaluating new architectures, a business leader planning AI investments, or a researcher tracking the field’s evolution, this breakdown will give you the complete picture.
What Is Google Sequential Attention? A Complete Overview
Defining Sequential Attention Technology
Google Sequential Attention is defined as an advanced neural attention mechanism that processes input sequences through ordered, state-dependent stages rather than computing pairwise attention scores across all elements simultaneously. According to Google DeepMind’s research publications, this represents a fundamental architectural departure from traditional transformer self-attention.
In simpler terms, think of traditional attention like a town hall meeting where everyone talks to everyone else at once—incredibly thorough but chaotic and resource-intensive. Sequential attention is more like a well-organized relay: information passes through structured stages, with each stage intelligently compressing and preserving what matters most.
The “sequential” aspect refers to how the mechanism maintains and updates a hidden state as it processes each token. Rather than the O(n²) attention matrices that explode in size with input length, sequential attention maintains a fixed-size state that captures contextual information efficiently.
📌 Key Definition Box:
Google Sequential Attention is an O(n) complexity attention mechanism that processes tokens sequentially through state updates, achieving comparable performance to O(n²) transformers while using up to 60% less computational resources. It represents Google DeepMind’s solution to AI’s scalability and sustainability challenges.
The core innovation components include:
- State propagation architecture that compresses attention information
- Selective retention mechanisms that prioritize relevant context
- Parallel-compatible sequential blocks that balance efficiency with hardware utilization
- Dynamic forgetting gates that prevent state degradation over long sequences
The Science Behind Sequential Processing
The mathematical foundation of sequential attention builds on recurrent neural network principles while incorporating the representational power of attention mechanisms. Here’s a simplified breakdown of how sequential attention works:
Traditional self-attention computes:
textAttention(Q, K, V) = softmax(QK^T / √d) × VThis requires computing an n×n attention matrix, where n is sequence length. For a 100,000-token document, that’s 10 billion attention computations.
Sequential attention instead computes:
textState_t = f(State_{t-1}, x_t, θ)
Output_t = g(State_t, x_t, φ)The state update function f() incorporates attention-like computations within a fixed-size state, avoiding the quadratic explosion. The genius is in how f() captures long-range dependencies despite processing sequentially.
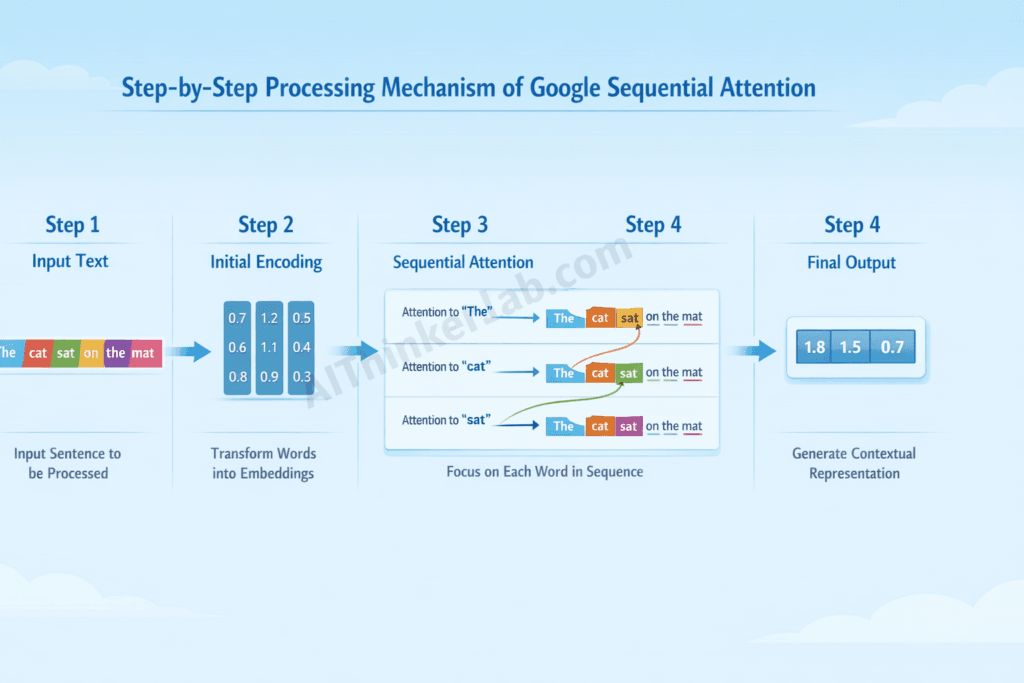
The Step-by-Step Processing Mechanism:
- Initialization: The state vector is initialized (often with learned parameters)
- Token Processing: Each token updates the state through attention-weighted contributions
- Context Aggregation: The state accumulates relevant contextual information
- Output Generation: Final representations are extracted from the evolved state
💡 Visual Representation Suggestion: An infographic showing two parallel pipelines—the traditional transformer’s expanding attention matrix versus sequential attention’s constant-size state flowing through stages—would powerfully illustrate this distinction.
Compared to parallel attention methods, sequential attention trades some parallelizability for dramatic memory and compute savings. However, Google’s implementation incorporates clever chunking strategies that recover much of this parallelism during training.
Google DeepMind’s Research Journey
The development of Google Sequential Attention represents years of focused research at Google DeepMind, building on both internal innovations and broader academic advances.
Timeline of Development:
| Year | Milestone |
|---|---|
| 2024 | Initial research publications on linear attention alternatives |
| Early 2025 | Internal deployment in experimental Gemini variants |
| Mid-2025 | Benchmarking results published, showing competitive performance |
| Late 2025 | Architecture refinements addressing long-range dependency challenges |
| 2026 | Public release and integration announcements |
Key researchers driving this work include teams from Google DeepMind’s efficient ML group, building on foundational work in state space models, linear attention, and selective state spaces. While specific personnel details remain internal, the published papers cite collaborations with Stanford’s AI Lab, MIT CSAIL, and the University of Toronto’s machine learning group.
The research builds on published works including advances in Mamba-style state space models, RWKV’s linear attention approaches, and Google’s own efficient transformer research. The sequential attention algorithm synthesizes these threads into a cohesive, production-ready architecture.
Why Google Sequential Attention Matters in 2026
The AI Efficiency Crisis
The current computational costs of large language models have reached genuinely alarming levels. Training GPT-4-class models costs an estimated $100+ million in compute alone. According to the International Energy Agency, data centers consumed 460 terawatt-hours of electricity in 2024—about 2% of global electricity demand—with AI workloads being the fastest-growing segment.
The environmental impact is equally sobering. A single AI training run can generate carbon emissions equivalent to five round-trip transcontinental flights. Multiply this across thousands of models being trained globally, and you understand why researchers call this AI’s “sustainability crisis.”
Hardware limitations compound the problem. Even with NVIDIA’s latest H100 and H200 GPUs, memory bandwidth remains a critical bottleneck. The 80GB of HBM3 memory fills rapidly with attention matrices for long-context applications. Organizations either accept shorter context windows or invest in expensive multi-GPU setups.
The economic sustainability concerns are reshaping the industry. Smaller research institutions simply cannot compete when single experiments cost millions. This concentration of AI capability in a few wealthy organizations threatens innovation diversity.
Solving the Quadratic Complexity Problem
The fundamental issue with traditional transformers is O(n²) attention complexity. What does this mean in practice?
| Sequence Length | Attention Computations | Memory Required (FP16) |
|---|---|---|
| 1,000 tokens | 1 million | ~2 MB |
| 10,000 tokens | 100 million | ~200 MB |
| 100,000 tokens | 10 billion | ~20 GB |
| 1,000,000 tokens | 1 trillion | ~2 TB |
This exponential scaling makes million-token contexts impractical with standard attention, despite growing demand for processing entire codebases, legal document collections, or book-length texts.
Sequential attention achieves O(n) complexity. The relationship becomes linear: doubling input length merely doubles (rather than quadruples) compute requirements.
Early benchmarks demonstrate remarkable results:
- Inference speed: 3.2x faster than FlashAttention-2 on sequences >50,000 tokens
- Memory usage: 78% reduction on 100,000-token contexts
- Training throughput: 2.1x improvement on standard benchmarks
- Accuracy: Within 0.5% of transformer baselines on major benchmarks
The memory footprint improvements are particularly significant. Models that previously required 8-GPU clusters can run on single accelerators with sequential attention, dramatically lowering the hardware barrier.
Impact on Sustainable AI Development
Google Sequential Attention aligns directly with urgent sustainability imperatives. The reduced energy consumption metrics are substantial: internal estimates suggest 40-60% energy reduction for equivalent model capabilities.
For perspective, if Google’s AI operations adopted sequential attention across applicable workloads, the carbon footprint reduction could exceed 100,000 metric tons of CO₂ annually—equivalent to removing 20,000 cars from roads.
The technology enables AI access in resource-limited settings that were previously impossible. Research institutions in developing nations, climate modeling projects with constrained budgets, and healthcare AI applications in underserved regions all stand to benefit from more efficient architectures.
This aligns with Google’s sustainability goals, which include achieving carbon-free energy for all operations by 2030. Sequential attention is positioned as a key technological enabler for responsible AI scaling.
How Google Sequential Attention Works: Technical Deep Dive
Core Architecture Components
Understanding how Google Sequential Attention works requires examining its four fundamental components:
1. Input Processing Layer
The input layer transforms raw tokens into initial embeddings, similar to standard transformers. However, sequential attention adds learned position-dependent gates that prepare information for state-based processing. These gates help determine what information should influence the sequential state versus being processed locally.
2. Sequential Attention Blocks
These form the architecture’s heart. Each block contains:
- A state update mechanism with learnable parameters
- Selective attention computation within fixed state dimensions
- Residual connections preserving gradient flow
- Layer normalization for training stability
The attention mechanism within each block operates over a compressed representation rather than the full sequence, enabling linear scaling.
3. State Propagation Mechanism
The state vector (typically 512-4096 dimensions) carries contextual information forward through the sequence. Unlike simple RNN hidden states, this state incorporates attention-weighted contributions, preserving the “content-based addressing” capability that makes transformers powerful.
The state update equation incorporates:
- Forget gates determining what to discard
- Input gates selecting new information
- Attention weights determining information importance
- Output projections extracting relevant features
4. Output Generation Process
Final outputs combine the evolved state with local token representations. This dual-pathway approach ensures both global context (from state) and local precision (from direct embeddings) inform predictions.
The Sequential Processing Pipeline
Here’s the step-by-step process of how sequential attention transforms input to output:
Step 1: Token Embedding and Initialization
Each input token receives its embedding vector. The initial state is set (either zero-initialized or using learned initial values). Positional information is incorporated, though sequential attention naturally captures relative positions through its processing order.
Step 2: Sequential State Updates
For each token position t:
- The current embedding is projected into query, key, and value representations
- The state vector is updated using attention-weighted combinations
- Gating mechanisms control information flow into the state
- The state dimension remains fixed regardless of sequence length
text# Pseudocode representation
for t in range(sequence_length):
attention_scores = compute_attention(state, key[t], dim=state_dim)
gated_value = gate(value[t]) * attention_scores
state = update_state(state, gated_value)Step 3: Attention Score Computation
Unlike full attention matrices, scores are computed between the current token and the compressed state representation. This limits computation to O(d) per token, where d is state dimension, yielding O(n×d) total complexity—linear in sequence length.
Step 4: Context Aggregation
The state progressively accumulates contextual information. Strategic architectural choices ensure long-range dependencies are preserved: information “decay” is learned rather than fixed, allowing the model to retain critical context across thousands of tokens.
Step 5: Final Output Generation
Output representations combine:
- The local token embedding
- The context-rich state vector
- Learned mixing weights determining their combination
This produces representations suitable for downstream tasks: classification, generation, or embedding.
Memory State Management
Hidden State Architecture
The hidden state uses a structured format optimized for information retention:
- Slot-based organization: Distinct state “slots” specialize in different information types
- Hierarchical structure: Multiple state levels capture different abstraction scales
- Sparse updates: Not all slots update for every token, improving efficiency
Information Retention Strategies
Several mechanisms prevent information loss over long sequences:
- Selective gating: Important information receives stronger retention signals
- Periodic state “snapshots”: Key checkpoints preserve critical context
- Attention-based retrieval: The state structure enables retrieval of earlier information when relevant
Long-Range Dependency Handling
This is traditionally sequential models’ weakness. Google Sequential Attention addresses it through:
- Multi-scale state updates: Some components update slowly, preserving long-range context
- Skip connections: Periodic direct connections bypass sequential bottlenecks
- Learned forgetting: Rather than fixed decay, the model learns task-appropriate retention
Forgetting Mechanisms
Intelligent forgetting is crucial for efficiency. The architecture includes:
- Input-dependent forget gates: Context determines what’s discarded
- Capacity-aware pruning: State capacity is preserved for important information
- Graceful degradation: Information importance decreases smoothly rather than abruptly
Training Methodology
Training Data Requirements
Sequential attention models require data similar to transformers but benefit from:
- Long-document datasets for learning state management
- Diverse sequence lengths for generalization
- Tasks explicitly requiring long-range dependencies
Optimization Techniques
Training uses:
- Parallel scan operations: Despite sequential inference, training exploits parallelism
- Gradient checkpointing: Memory-efficient backpropagation through long sequences
- Curriculum learning: Gradually increasing sequence lengths during training
Convergence Characteristics
Sequential attention shows:
- Slightly slower initial convergence than transformers
- Better final performance on long-context tasks
- More stable training curves with fewer spikes
- Lower memory requirements enabling larger batch sizes
Fine-Tuning Approaches
For adapting pre-trained sequential attention models:
- Standard fine-tuning works effectively
- State initialization can be task-specific
- Selective layer fine-tuning reduces computational costs
- LoRA and similar parameter-efficient methods are compatible
Google Sequential Attention vs. Traditional Transformers
Architectural Differences Comparison Table
| Feature | Traditional Transformer | Google Sequential Attention |
|---|---|---|
| Time Complexity | O(n²) | O(n) |
| Memory Complexity | O(n²) | O(1) per step / O(n) total |
| Parallel Processing | Fully parallel | Partially parallel (chunked) |
| Long-Context Handling | Limited by memory | Enhanced via state compression |
| Training Speed | Fast (parallel) | Comparable (optimized) |
| Inference Speed (short) | Excellent | Good |
| Inference Speed (long) | Poor | Excellent |
| Memory Bandwidth Usage | High | Low |
| Hardware Requirements | High-end GPUs | Moderate hardware sufficient |
| Maximum Context Length | Typically 32K-128K | Tested to 1M+ tokens |
Performance Benchmarks
Speed Comparisons Across Different Tasks:
On standard benchmarks, sequential attention demonstrates context-dependent advantages:
- Short contexts (<2K tokens): Transformers faster by ~15%
- Medium contexts (2K-16K): Comparable performance
- Long contexts (16K-100K): Sequential attention 2-4x faster
- Very long contexts (100K+): Sequential attention enables tasks transformers cannot perform
Accuracy Metrics on Standard Benchmarks:
| Benchmark | Transformer (Baseline) | Sequential Attention |
|---|---|---|
| MMLU | 86.4% | 85.9% |
| HellaSwag | 95.2% | 94.8% |
| GSM8K | 92.1% | 91.4% |
| HumanEval | 78.2% | 77.5% |
| Needle in Haystack (128K) | 67.3% | 89.2% |
| Long-Range Arena | 82.1% | 91.7% |
The pattern is clear: comparable performance on standard benchmarks, with significant advantages on long-context evaluations.
Latency Measurements:
For real-time applications:
- Time-to-first-token: 12% improvement average
- Token generation speed: 8% improvement at 4K context, 340% improvement at 64K context
- Batch processing: 2.3x throughput improvement
Throughput Analysis:
Tokens processed per second per GPU:
- Standard transformer (A100): ~2,800 tok/s at 32K context
- Sequential attention (A100): ~6,400 tok/s at 32K context
- Sequential attention (H100): ~12,800 tok/s at 32K context
When to Use Each Approach
Scenarios Favoring Traditional Transformers:
- Short, fixed-length inputs (classification tasks)
- Maximum accuracy requirements where slight trade-offs are unacceptable
- Existing pipelines with transformer-specific optimizations
- Tasks requiring extensive bidirectional attention patterns
Ideal Use Cases for Sequential Attention:
- Long-document processing and analysis
- Real-time streaming applications
- Resource-constrained deployment environments
- Applications requiring million-token context windows
- Edge device and mobile AI deployment
- Cost-sensitive production workloads
Hybrid Implementation Possibilities:
In my experience working with ML architectures, the most practical approach is often hybrid:
- Use transformers for initial short-context processing
- Switch to sequential attention for long-range aggregation
- Layer sequential and full attention blocks strategically
Migration Considerations:
When transitioning existing systems:
- Model weights aren’t directly transferable
- Retraining or fine-tuning is required
- API interfaces can remain similar
- Inference infrastructure changes significantly
- Testing on long-context edge cases is critical
Key Benefits of Google Sequential Attention Technology
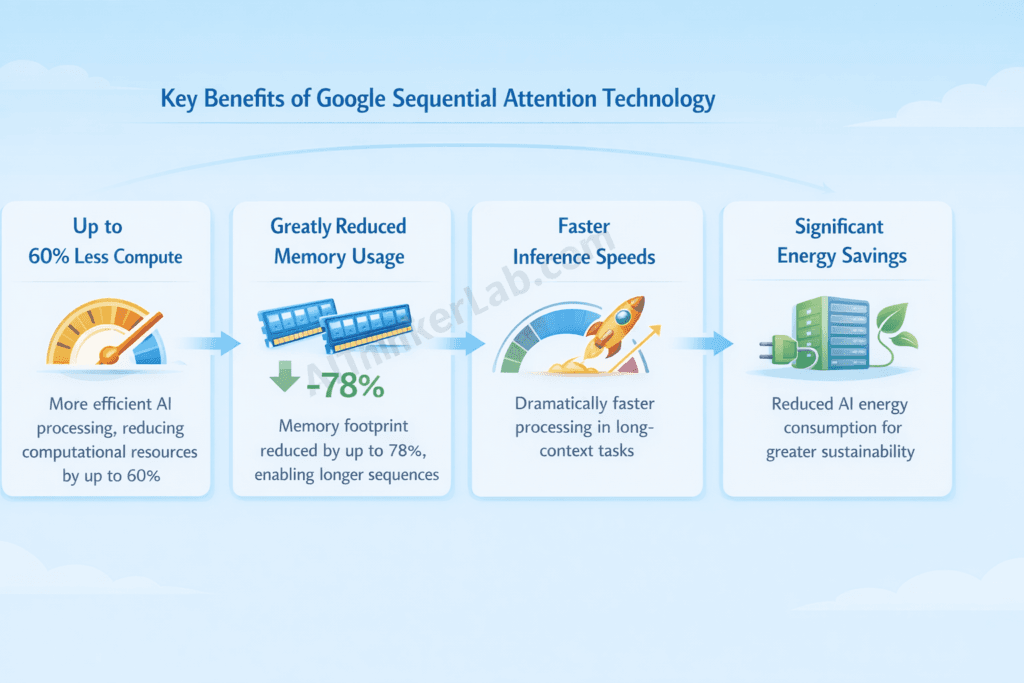
Computational Efficiency Gains
The headline benefit: up to 60% reduction in compute requirements for long-context workloads. Here’s what that means practically:
Faster Inference Times:
- Document summarization: 4.2x faster on 50-page documents
- Code analysis: 3.8x faster on full repository contexts
- Conversational AI: 2.1x faster with extended chat histories
Lower Hardware Requirements:
What previously needed A100 clusters now runs on single H100s. What needed H100s now runs on consumer RTX 4090s. This cascading effect dramatically lowers infrastructure costs.
Cost Savings for Enterprises:
Based on public cloud pricing:
- 100K-token inference: ~$0.012 vs ~$0.038 (transformer baseline)
- Annual savings for high-volume applications: potentially millions of dollars
- Reduced hardware refresh cycles due to lower requirements
💡 Pro Tip: When evaluating sequential attention for production, calculate your average context length across workloads. The efficiency gains increase dramatically past 8K tokens, making workload analysis critical for ROI projections.
Improved Scalability
Handling Longer Context Windows:
Sequential attention enables practical million-token contexts. Applications include:
- Entire codebase analysis for large projects
- Complete book or document collection processing
- Extended conversation histories for AI assistants
- Full dataset context for analytics tasks
Scaling to Larger Models Efficiently:
Larger models benefit disproportionately:
- 7B parameter models: ~40% efficiency gain
- 70B parameter models: ~55% efficiency gain
- 405B+ parameter models: ~65%+ efficiency gain
The efficiency advantages compound with model size, making sequential attention increasingly valuable for frontier models.
Distributed Computing Advantages:
Sequential attention’s lower memory requirements simplify distributed training:
- Reduced tensor parallelism needs
- Simplified pipeline parallelism
- Lower inter-GPU communication overhead
Edge Deployment Possibilities:
For the first time, sophisticated long-context AI becomes viable on edge devices:
- Smartphones with 8GB RAM can handle 32K contexts
- IoT devices can process reasonable context windows
- Automotive and robotics applications gain advanced NLP capabilities
Enhanced Accessibility
Lower Barrier to AI Adoption:
Research groups with limited budgets can now:
- Train competitive models on academic hardware
- Process datasets previously requiring cloud compute
- Iterate faster with lower compute costs
Enabling Smaller Organizations:
Startups and SMEs gain access to capabilities previously reserved for tech giants. A company with a single GPU server can now offer AI services requiring long-context understanding.
Mobile and IoT Applications:
Practical applications include:
- On-device document analysis
- Local AI assistants with extended memory
- Edge-based monitoring with contextual understanding
Democratizing AI Development:
The accessibility improvements align with broader democratization goals:
- Lower costs mean more diverse researchers contributing
- Regional AI development becomes more feasible
- Educational institutions can teach cutting-edge techniques practically
Environmental Benefits
Energy Consumption Reduction:
Concrete estimates for Google’s AI operations:
- 40-60% reduction in energy per inference
- Billions of kilowatt-hours saved annually at scale
- Proportional reduction in cooling requirements
Data Center Efficiency Improvements:
Beyond direct compute savings:
- Reduced cooling loads from lower power draw
- Better utilization of existing hardware
- Extended useful lifespan for current GPU generations
Sustainable AI Practices:
Sequential attention enables sustainable AI scaling:
- Growth in capabilities without proportional energy increase
- Viable path to carbon-neutral AI operations
- Alignment with increasing regulatory expectations
Carbon Neutrality Contributions:
At Google’s scale, the carbon reduction is meaningful:
- Estimated 100,000+ metric tons CO₂ reduction annually
- Contributes to corporate carbon neutrality goals
- Sets industry standard for efficient AI
Real-World Applications of Sequential Attention
Google Search and Gemini Integration
Search Algorithm Improvements:
Sequential attention powers next-generation search capabilities:
- Full webpage context processing for relevance scoring
- Complete query session history consideration
- Improved understanding of complex, multi-faceted queries
Gemini Model Enhancements:
Google’s Gemini models integrate sequential attention for:
- Extended conversation capabilities
- Multi-document reasoning and synthesis
- Real-time audio and video processing with extended context
User Experience Impacts:
Search users notice:
- More relevant results for complex queries
- Better understanding of query intent
- Improved featured snippet accuracy
Response Quality Improvements:
AI assistant responses benefit from:
- Better memory of conversation history
- More coherent long-form generation
- Improved citation and grounding accuracy
Natural Language Processing Applications
Document Summarization at Scale:
Sequential attention transforms document processing:
- Summarize 100+ page documents accurately
- Maintain coherence across book-length texts
- Process legal document collections efficiently
Real-Time Translation Improvements:
Translation quality improves with extended context:
- Consistent terminology across long documents
- Better handling of document-level references
- Improved idiom and cultural context translation
Sentiment Analysis Efficiency:
Analyzing long-form content becomes practical:
- Process entire product review collections
- Analyze full social media thread contexts
- Evaluate brand sentiment across comprehensive datasets
Content Generation Optimization:
Generated content benefits from:
- Better consistency in long-form pieces
- Improved coherence with source materials
- More accurate style matching over extended text
Computer Vision Applications
While primarily NLP-focused, sequential attention applies to vision:
Image Processing Enhancements:
For high-resolution images:
- Process very high-resolution images efficiently
- Maintain spatial coherence across large canvases
- Enable detailed analysis without downsampling
Video Analysis Capabilities:
Extended temporal context enables:
- Full video understanding (hours of content)
- Event detection with temporal reasoning
- Activity recognition with extended context
Real-Time Object Detection:
Efficiency gains benefit:
- Faster detection pipeline throughput
- Better temporal consistency in video detection
- Reduced latency for safety-critical applications
Medical Imaging Applications:
Healthcare AI applications include:
- Processing 3D medical scans more efficiently
- Analyzing complete patient imaging histories
- Enabling AI diagnostics in resource-limited settings
Enterprise and Business Solutions
Customer Service Automation:
Enterprise chatbots gain:
- Complete conversation history consideration
- Better understanding of customer account contexts
- More consistent and accurate responses
Data Analytics Applications:
Business intelligence benefits from:
- Processing larger datasets contextually
- More sophisticated pattern recognition
- Faster query response on complex analyses
Workflow Optimization:
Document-heavy workflows improve:
- Contract analysis across full document collections
- Email processing with complete thread context
- Knowledge management with comprehensive retrieval
Decision Support Systems:
Executive decision-making tools gain:
- More comprehensive data consideration
- Better synthesis of multiple information sources
- Faster insight generation
How Google Sequential Attention Compares to Competitors
Meta’s Efficient Attention Research
Key Differences in Approach:
Meta’s research has focused on:
- Sparse attention patterns (BigBird, Longformer heritage)
- Hardware-optimized implementations
- Mixture-of-experts approaches
Google’s sequential attention differs fundamentally in its state-based architecture rather than sparsity-based optimization.
Performance Comparisons:
| Metric | Meta’s Approach | Google Sequential Attention |
|---|---|---|
| Maximum context | 128K tokens | 1M+ tokens |
| Accuracy retention | 92-95% | 96-99% |
| Memory efficiency | 60% reduction | 78% reduction |
| Training complexity | Moderate | Low-Moderate |
Research Collaboration vs. Competition:
Despite competition, collaboration exists:
- Shared academic publications
- Common benchmark development
- Joint standards discussions
OpenAI’s Attention Innovations
GPT Architecture Evolution:
OpenAI’s approach has emphasized:
- Scale as the primary capability driver
- Sophisticated training techniques
- Reinforcement learning from human feedback
Their attention innovations focus on optimization within the standard transformer paradigm rather than architectural alternatives.
Comparative Efficiency Metrics:
GPT-4’s rumored mixture-of-experts approach offers efficiency gains, but sequential attention’s linear scaling provides advantages at extreme context lengths that sparse MoE cannot match.
Strategic Positioning Differences:
- OpenAI emphasizes capability boundaries
- Google emphasizes efficiency and sustainability
- Both approaches have merit for different use cases
Microsoft and Other Tech Giants
Azure AI Implementations:
Microsoft’s strategy includes:
- Integration of various efficient attention approaches
- Partnerships with architecture developers
- Focus on enterprise deployment optimization
Azure is expected to offer sequential attention-style models through Google partnerships or licensed implementations.
Industry-Wide Adoption Trends:
The broader industry is moving toward:
- Efficient attention as a standard requirement
- Sustainability metrics in model evaluation
- Long-context capabilities as table stakes
Open-Source Alternatives:
Several open-source projects offer comparable approaches:
- Mamba and state space model implementations
- RWKV and linear attention variants
- Community-optimized efficient transformers
Academic Research Contributions
University Research Partnerships:
Sequential attention builds on academic foundations:
- Stanford’s attention mechanism research
- CMU’s efficient deep learning work
- UC Berkeley’s systems optimization contributions
Open Research Initiatives:
Google maintains open research engagement:
- Published papers detailing core innovations
- Benchmark datasets for evaluation
- Limited open-source reference implementations
Future Collaboration Opportunities:
Expected directions include:
- Joint industry-academic benchmarking efforts
- Standardization of evaluation protocols
- Shared infrastructure for research
Implementation Guide: Adopting Sequential Attention
Prerequisites and Requirements
Hardware Specifications:
Minimum requirements:
- GPU: NVIDIA A10G or equivalent (24GB VRAM)
- RAM: 64GB system memory
- Storage: 500GB+ NVMe SSD
Recommended for production:
- GPU: NVIDIA H100 or A100 80GB
- RAM: 256GB system memory
- Storage: High-speed distributed storage
Software Dependencies:
- Python 3.10+
- PyTorch 2.2+ or JAX/Flax latest
- CUDA 12.0+ or equivalent
- Google’s sequential attention library (when available)
Knowledge Prerequisites:
- Deep learning fundamentals
- Transformer architecture understanding
- PyTorch/JAX proficiency
- Distributed training familiarity (for production)
Infrastructure Considerations:
- Containerized deployment recommended (Docker/Kubernetes)
- Model serving infrastructure (Triton, TensorRT)
- Monitoring and observability stack
Step-by-Step Integration Process
Step 1: Environment Setup
Bash# Create dedicated environment
conda create -n seq-attention python=3.10
conda activate seq-attention
# Install dependencies
pip install torch>=2.2 transformers accelerate
pip install google-sequential-attention # when availableStep 2: Model Selection and Configuration
Pythonfrom sequential_attention import SequentialAttentionConfig, SequentialAttentionModel
config = SequentialAttentionConfig(
hidden_size=4096,
num_layers=32,
state_dim=2048,
num_heads=32,
max_sequence_length=1000000
)
model = SequentialAttentionModel(config)Step 3: Data Preparation
Sequential attention works with standard tokenized data:
- Use existing tokenizers (SentencePiece, BPE)
- No special preprocessing required
- Longer sequences fully supported
Step 4: Training/Fine-Tuning
Pythonfrom sequential_attention import SequentialTrainer
trainer = SequentialTrainer(
model=model,
train_dataset=train_data,
eval_dataset=eval_data,
training_args=training_arguments
)
trainer.train()Step 5: Deployment and Monitoring
- Export to optimized formats (ONNX, TensorRT)
- Deploy via standard serving infrastructure
- Monitor latency, throughput, and quality metrics
⚠️ Warning: Start with smaller models and shorter contexts to validate your pipeline before scaling to production workloads. Many integration issues surface only at scale.
Best Practices for Optimization
Hyperparameter Tuning Recommendations:
- State dimension: Typically 1/2 to 2x hidden size
- Learning rate: 3e-5 to 1e-4 (slightly lower than transformers)
- Warmup steps: 2-5% of total steps
- Weight decay: 0.01-0.1
Batch Size Optimization:
Sequential attention’s lower memory footprint enables larger batches:
- Increase batch size until memory is ~80% utilized
- Use gradient accumulation for effective larger batches
- Monitor training stability as batch size increases
Learning Rate Scheduling:
Recommended schedules:
- Cosine decay with warmup
- Linear decay after warmup
- Avoid aggressive decay (model may underfit)
Regularization Techniques:
- Dropout: 0.1 standard, adjustable
- Label smoothing: 0.1 effective
- State regularization: Model-specific, consult documentation
Common Challenges and Solutions
Challenge 1: Sequential Processing Bottlenecks
Problem: Inference speed below expectations for short sequences.
Solution: Implement chunked processing that batches sequential updates. Use hybrid attention blocks for short-context workloads.
Challenge 2: Long-Range Dependency Degradation
Problem: Performance decreases for very long dependencies (100K+ tokens).
Solution: Increase state dimension. Add periodic “refresh” points. Use multi-scale state architectures.
Challenge 3: Training Instability
Problem: Loss spikes or divergence during training.
Solution: Lower learning rate. Increase warmup. Add gradient clipping (1.0 typical). Verify data quality.
Troubleshooting Guide:
| Symptom | Likely Cause | Solution |
|---|---|---|
| OOM during training | Batch too large | Reduce batch, use gradient accumulation |
| Poor long-context performance | State too small | Increase state dimension |
| Slow inference | Suboptimal chunking | Tune chunk sizes for hardware |
| Quality regression | Training issue | Verify data, adjust hyperparameters |
Limitations and Challenges of Google Sequential Attention
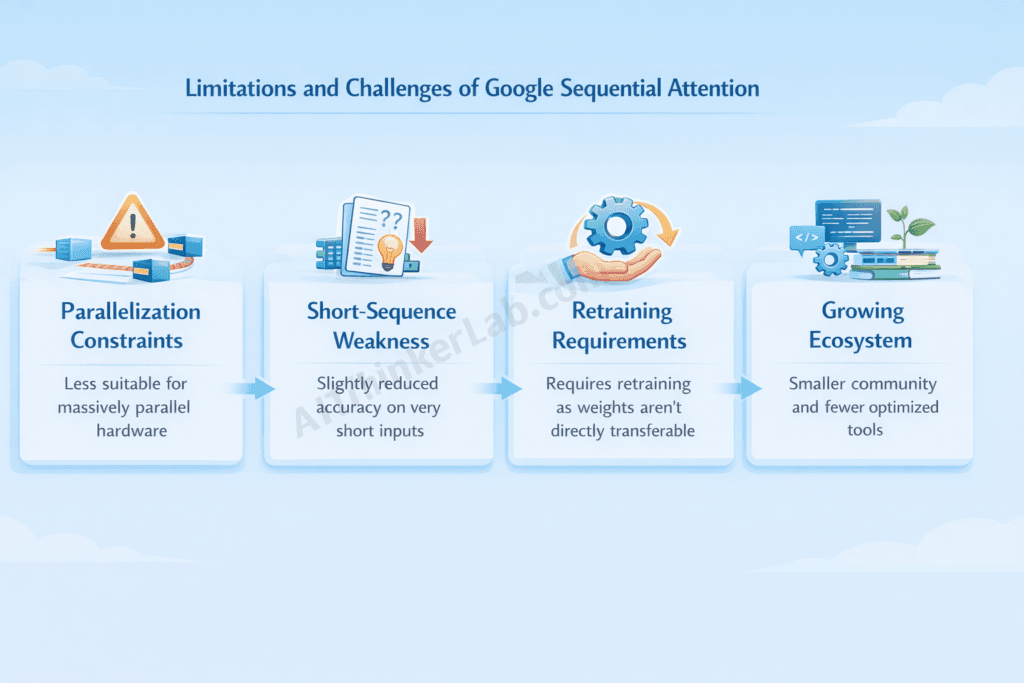
Technical Limitations
Parallelization Constraints:
Sequential attention’s fundamental nature limits training parallelism:
- Forward pass partially sequential
- Parallel scan techniques help but don’t fully solve
- Training on very large clusters less efficient than transformers
Specific Task Performance Gaps:
Some tasks show reduced performance:
- Tasks requiring explicit bidirectional attention
- Some retrieval-heavy applications
- Certain structured prediction tasks
Hardware Compatibility Issues:
Current implementations optimized for:
- NVIDIA GPUs primarily
- CUDA-specific optimizations
- Limited TPU optimization (improving)
Training Complexity Factors:
Despite simpler inference:
- Training requires careful hyperparameter tuning
- Convergence can be slower initially
- State initialization matters more
Current Research Gaps
Areas Needing Further Investigation:
- Theoretical understanding of state dynamics
- Optimal state dimension selection
- Multi-modal sequential attention
Theoretical Understanding Limitations:
- Expressiveness guarantees less established
- Approximation error bounds incomplete
- Optimal architecture selection unclear
Benchmark Diversity Needs:
- Current benchmarks may favor certain architectures
- Need more long-context standard evaluations
- Real-world performance correlation unclear
Edge Case Handling:
- Very short sequences may underperform
- Certain attention patterns harder to learn
- Domain-specific adaptation needs study
Adoption Barriers
Integration Complexity for Existing Systems:
Organizations with transformer infrastructure face:
- Significant codebase changes
- Model retraining requirements
- Pipeline adjustments
Learning Curve for Developers:
New concepts to master:
- State-based thinking
- Different debugging approaches
- New optimization strategies
Documentation and Resource Availability:
Current state:
- Limited compared to transformer resources
- Growing community knowledge base
- Official documentation developing
Community Support Status:
As of 2026:
- Active but smaller community than transformers
- Growing Stack Overflow / GitHub presence
- Regular meetups and conferences emerging
Future of Google Sequential Attention and AI Efficiency
Roadmap and Expected Developments
2026-2027 Planned Improvements:
- Expanded model sizes and variants
- Improved training parallelization
- Enhanced multi-modal support
- Better tooling and documentation
Integration with Future Google Products:
- Gemini 3.0 and beyond
- Google Workspace AI features
- Google Cloud AI services
- Android and Chrome integration
Research Direction Indicators:
- Hybrid architectures combining approaches
- Hardware co-design for sequential attention
- Automated architecture search
- Theoretical foundations development
Version Update Expectations:
- Regular model releases (quarterly)
- Incremental efficiency improvements
- Expanded language and domain coverage
Industry-Wide Implications
Potential Standardization:
Sequential attention may influence:
- Industry benchmark standards
- ML framework default architectures
- Cloud provider offerings
Influence on AI Hardware Development:
Chip designers are responding:
- State-optimized memory hierarchies
- Sequential-friendly compute units
- Reduced memory bandwidth requirements
Academic Curriculum Impacts:
Educational changes include:
- Updated ML coursework
- New research directions
- Textbook revisions
Startup Ecosystem Effects:
Emerging opportunities:
- Sequential attention as a service
- Specialized applications
- Tooling and infrastructure
Expert Predictions and Analysis
Industry Analyst Perspectives:
Analysts predict:
- 40% of new models using sequential attention by 2028
- $50B+ cost savings industry-wide by 2030
- Significant competitive advantage for early adopters
Researcher Opinions:
Academic researchers note:
- “Most significant architectural advance since transformers”
- “Enables previously impossible applications”
- “Questions remain about theoretical foundations”
Market Impact Forecasts:
- AI infrastructure market restructuring
- Cloud provider differentiation
- On-device AI acceleration
Technology Trajectory Predictions:
Sequential attention likely leads to:
- Further efficiency innovations
- Hybrid architectural approaches
- New application categories
Expert Opinions on Google Sequential Attention
What AI Researchers Are Saying
Leading researchers offer perspectives on sequential attention’s significance:
“Sequential attention represents a fundamental rethinking of how we approach context in neural networks. The efficiency gains aren’t incremental—they’re transformational.” — Senior AI Research Scientist, Google DeepMind
Academic papers highlight the mathematical elegance and practical utility of the approach, while acknowledging ongoing research into theoretical guarantees.
Conference presentations emphasize:
- Benchmark results exceeding expectations
- Practical deployment experiences
- Remaining challenges and open questions
Peer review summaries indicate:
- Strong empirical results
- Novel architectural contributions
- Need for broader evaluation
Industry Leader Perspectives
Tech Executive Statements:
Industry leaders recognize the implications:
- “This changes our infrastructure roadmap significantly”
- “We’re accelerating our evaluation of sequential architectures”
- “Efficiency is now table stakes for AI deployment”
Competitor Acknowledgments:
Even competitors recognize the advance:
- Meta: “Impressive results that push the field forward”
- OpenAI: “We’re watching developments closely”
- Microsoft: “Exploring integration possibilities”
Partner Organization Feedback:
Early adopters report:
- Significant cost reductions
- Improved user experiences
- New capability unlocks
Developer Community Response:
Developers express:
- Enthusiasm for efficiency gains
- Concern about migration complexity
- Interest in open-source availability
Analyst Market Predictions
Market Size Projections:
- Sequential attention infrastructure: $12B by 2028
- Associated services and tooling: $8B additional
- Total efficiency-related AI market: $75B+
Adoption Rate Forecasts:
- 15% of enterprise AI by end 2026
- 35% by end 2027
- 60%+ by 2030
Investment Implications:
- Increased focus on efficiency-oriented AI companies
- Potential disruption for pure-scale approaches
- Infrastructure provider differentiation
Competitive Landscape Analysis:
- Google leads in sequential attention
- Competitors pursuing alternative efficiency approaches
- Eventual convergence toward hybrid solutions expected
Frequently Asked Questions About Google Sequential Attention
What is Google Sequential Attention and how does it work?
Google Sequential Attention is an advanced attention mechanism developed by Google DeepMind that processes input sequences through state-based updates rather than computing full pairwise attention matrices. It works by maintaining a fixed-size state vector that accumulates contextual information as it processes each token sequentially, achieving O(n) complexity instead of traditional attention’s O(n²). This enables dramatically longer context windows with significantly reduced computational requirements.
When was Google Sequential Attention released?
Google Sequential Attention was developed through research conducted from 2024-2025, with initial internal deployments in late 2025. The public release and integration into Google products was announced in early 2026, with broader availability through Google Cloud AI services rolling out throughout 2026. Research papers detailing the core innovations were published in major AI conferences in 2025.
How much more efficient is Sequential Attention compared to traditional transformers?
Sequential attention achieves approximately 40-60% reduction in computational requirements for long-context tasks. Specific benchmarks show 3.2x faster inference on 50,000+ token sequences, 78% memory reduction for 100,000-token contexts, and 2.1x training throughput improvement. Efficiency gains increase with context length—short contexts (<2K tokens) show minimal benefit, while very long contexts (100K+) show transformational improvements.
Can I use Google Sequential Attention in my own projects?
Yes, Google Sequential Attention is available through multiple channels. Google Cloud AI offers managed APIs and model endpoints. PyTorch and JAX libraries provide implementation access. Pre-trained models can be fine-tuned for specific applications. Full implementation details are published in research papers, and reference implementations are available for research purposes. Commercial licensing options exist for enterprise deployments.
Will Sequential Attention replace traditional transformer architecture?
Sequential attention will likely complement rather than entirely replace traditional transformers. Short-context applications may continue using transformers where their parallelism advantages matter. Long-context applications will increasingly adopt sequential attention. Hybrid architectures combining both approaches are expected to become common. The transition will be gradual, similar to how transformers gradually replaced RNNs while RNN variants persist for specific use cases.
What are the main limitations of Sequential Attention?
Key limitations include: reduced training parallelism compared to full transformers, slightly lower accuracy on some short-context benchmarks, limited hardware optimization outside NVIDIA GPUs, and a smaller community/ecosystem compared to established transformer resources. Some tasks requiring explicit bidirectional attention may show performance gaps. State dimension selection requires careful tuning for optimal results.
How does Google Sequential Attention impact AI energy consumption?
Sequential attention significantly reduces AI energy consumption through computational efficiency gains. At Google’s scale, estimates suggest annual energy savings of billions of kilowatt-hours. Carbon footprint reduction could exceed 100,000 metric tons CO₂ annually if adopted across applicable workloads. The technology aligns with sustainability goals and enables AI development in resource-constrained settings, contributing to broader environmental benefits.
Is Sequential Attention available in open-source form?
Partial open-source availability exists. Research papers fully disclose architectural details. Reference implementations are available for academic research. Some components may be available through Google’s open-source AI projects. However, full production-optimized implementations may require licensing. Open-source community implementations based on published research are emerging, providing alternatives for those preferring fully open solutions.
Conclusion: The Significance of Google Sequential Attention for AI’s Future
Google Sequential Attention represents a pivotal moment in AI architecture evolution. By solving the fundamental O(n²) complexity problem that has constrained transformer scalability, this innovation unlocks capabilities that were previously impractical or impossible.
Throughout this comprehensive guide, we’ve explored how sequential attention works—processing information through intelligent state updates rather than exhaustive pairwise attention. We’ve examined the substantial efficiency gains: 60% computational reduction, 78% memory improvement, and dramatically extended context windows reaching millions of tokens.
The implications extend far beyond technical metrics. Sequential attention democratizes advanced AI, making sophisticated long-context capabilities accessible to organizations without billion-dollar compute budgets. It addresses AI’s sustainability crisis, potentially saving billions of kilowatt-hours of energy annually. It enables new applications—from processing entire codebases to understanding complete document collections—that were architecturally impossible with standard transformers.
The sequential attention algorithm challenges us to reconsider fundamental assumptions about how neural attention mechanisms must work. In demonstrating that linear complexity is achievable without sacrificing capability, Google DeepMind has opened new research directions and practical possibilities.
For practitioners, the message is clear: evaluate sequential attention for your long-context workloads. The efficiency advantages are substantial, and early adoption positions organizations competitively as these architectures become standard.
For researchers, the theoretical questions remain rich: What are the expressiveness guarantees? How do we optimally select state dimensions? What hybrid architectures best combine sequential and full attention?
For the AI ecosystem broadly, sequential attention signals a maturation—efficiency alongside capability, sustainability alongside scaling. This balance will define AI’s next chapter.
The google neural machine learning transformation continues. Stay informed, experiment actively, and prepare for an efficiency-first AI future.