Key Takeaways
- Milestone velocity: llama.cpp 100K GitHub Stars arrived in March 2026 — faster than PyTorch (~7 years) or TensorFlow (~8 years) reached the same count.
- 1,000× cost advantage: Local inference costs approximately $0.002 per million tokens in electricity, versus $2.50–$15.00/M tokens through cloud APIs from OpenAI, Anthropic, or Google.
- Unmatched hardware reach: Supports Apple Metal, NVIDIA CUDA, AMD ROCm, Intel SYCL, Vulkan, and ARM NEON — from Raspberry Pi 5 boards to 8×GPU servers.
- GGUF dominance: Over 60% of quantized models on Hugging Face now ship in GGUF format, the file standard built for llama.cpp.
- Community velocity: 700+ contributors merged 3,800+ pull requests in 2025 — roughly 3× the PR throughput of NVIDIA’s fully funded TensorRT-LLM.
- Compliance by architecture: Fully offline inference means zero data leaves the device, inherently satisfying GDPR, HIPAA, SOC 2, and ITAR.
The Milestone That Reframes Local AI
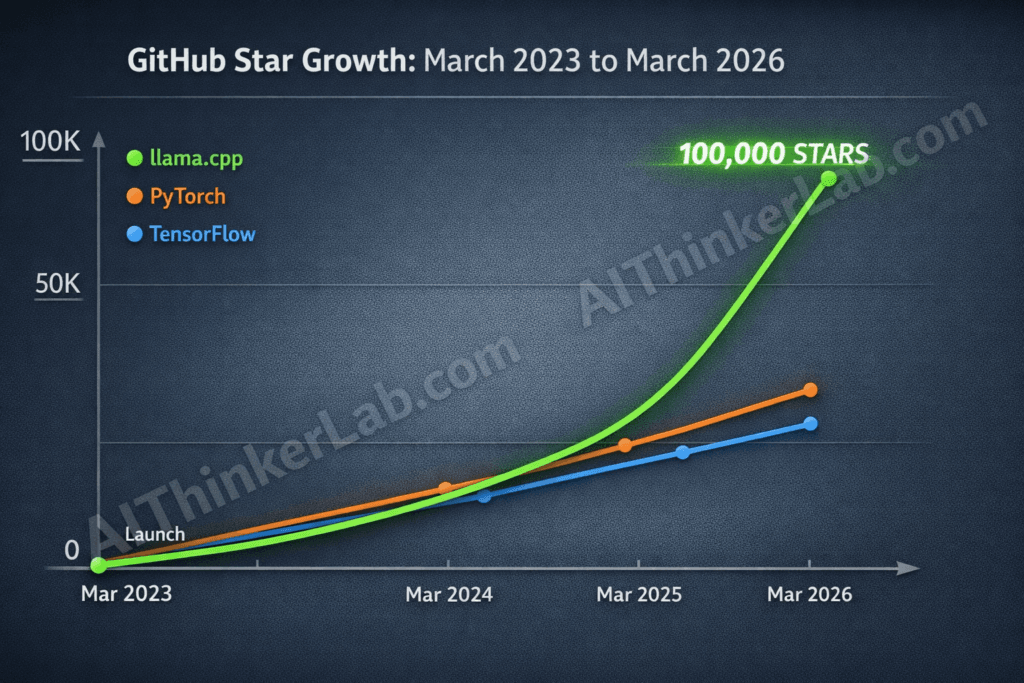
The llama.cpp 100K GitHub Stars milestone landed in March 2026, making Georgi Gerganov’s inference engine the fastest open-source AI project to reach that threshold. PyTorch took roughly seven years. TensorFlow needed closer to eight. llama.cpp did it in under three.
But the star count alone isn’t the story. What those 100,000 developers collectively discovered — and what the rest of the industry keeps underpricing — is that cloud LLM APIs charge $2.50 to $15.00 per million tokens for inference you can run on your own hardware for fractions of a penny. No API keys. No vendor lock-in. No data crossing your network boundary.
This article breaks down seven specific, benchmark-backed reasons llama.cpp earned that kind of adoption velocity — and what the project’s trajectory signals for every team still renting inference from someone else’s GPU cluster.
What llama.cpp 100K GitHub Stars Tells Us About Local AI
The llama.cpp 100K GitHub Stars count isn’t a vanity number — it’s the clearest market signal we have for the most significant infrastructure shift in AI since the cloud-first era began. Developers are pulling LLM inference off remote APIs and onto local machines, and this project sits at the center of that migration.
Context sharpens the signal. By March 2026, vLLM — the leading server-side inference engine — sits around 35,000 stars. Text-generation-webui holds roughly 42,000. Ollama has crossed 110,000, but that number actually reinforces the same trend: Ollama wraps llama.cpp’s inference backend in a simplified shell, so its popularity is llama.cpp’s popularity, repackaged for a less technical audience.
The stars-to-forks ratio tells a sharper story. Projects that attract passive curiosity accumulate stars without proportional fork activity. llama.cpp’s 15,000+ forks and 700+ contributors suggest active integration — developers embedding the engine into their own products, research pipelines, and enterprise tools. This isn’t casual bookmarking. It’s infrastructure adoption.
Key Insight: The 100K milestone reflects a structural shift from cloud-dependent AI inference to local, privacy-preserving deployment — and llama.cpp is the infrastructure layer powering that transition.
From Georgi Gerganov’s Side Project to the Fastest-Growing AI Repo
llama.cpp began in March 2023 as a single-developer experiment. Georgi Gerganov, a Bulgarian software engineer, wanted to find out whether Meta’s newly released LLaMA model weights could run inference in pure C/C++ — no Python, no PyTorch, no dependency sprawl. The 7B-parameter model ran on a MacBook CPU. And the trajectory from that first commit to 100,000 stars unfolded faster than anyone predicted.
Key inflection points:
- March 2023: Initial commit — CPU-only inference for LLaMA 7B on consumer hardware.
- Mid-2023: The ggml tensor library extracted as a standalone project. 4-bit quantization added.
- Late 2023: GGUF replaced the older GGML file format, bundling tokenizer and metadata into a single file.
- 2024: GPU acceleration shipped for Metal, CUDA, ROCm, and Vulkan. Contributor count crossed 500.
- 2025: Server mode, embedding endpoints, and grammar-constrained generation reached stable quality.
- March 2026: 100,000 stars. 700+ contributors. 15,000+ forks.
The architectural decision that enabled every milestone on that list was deceptively simple: pure C/C++ with zero external runtime dependencies. No Python interpreter required. No framework to install. That single constraint made llama.cpp portable to every operating system, embeddable in any application, and fast enough to hold its own against runtimes backed by billion-dollar engineering organizations.
Key Insight: llama.cpp’s zero-dependency C/C++ architecture — not any single feature — is the foundational decision that enabled its growth from a weekend experiment to production infrastructure powering thousands of deployments.
Zero Cloud Costs: Run Any LLM Locally for Pennies per Million Tokens
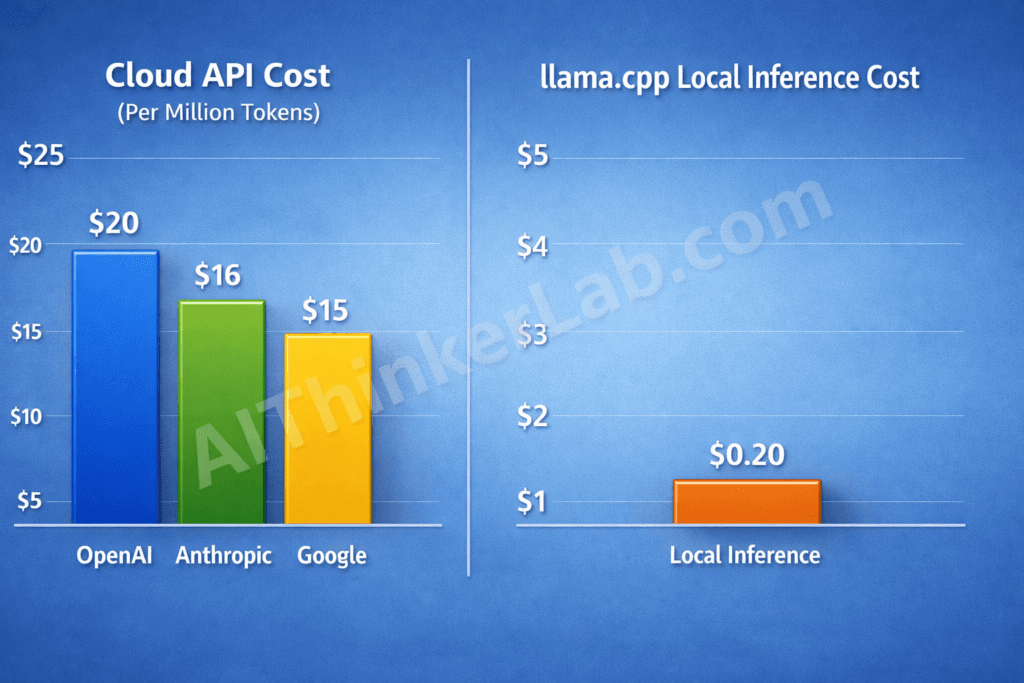
Economics drive adoption faster than ideology. The single most cited reason developers migrate to llama.cpp is blunt arithmetic: running a quantized 70B-parameter model on local hardware costs approximately $0.002 per million tokens in electricity. Cloud API equivalents from OpenAI, Anthropic, and Google charge 1,000× to 7,500× more for comparable output quality.
| Inference Method | Est. Cost / 1M Tokens | Latency (tok/s, 70B) | Data Leaves Device? |
|---|---|---|---|
| OpenAI GPT-4o API | $2.50–$10.00 | 60–80 | Yes |
| Anthropic Claude 3.5 API | $3.00–$15.00 | 50–70 | Yes |
| Google Gemini 1.5 API | $1.25–$5.00 | 55–75 | Yes |
| llama.cpp (Apple M3 Max, Q4_K_M) | ~$0.002 (electricity) | 15–25 | No |
| llama.cpp (NVIDIA RTX 4090, Q4_K_M) | ~$0.003 (electricity) | 40–60 | No |
The tradeoff is real: cloud APIs currently deliver higher throughput for large concurrent workloads. But for individual developers, small teams, or any use case under 50 simultaneous users, the cost gap is overwhelming. A team processing 10 million tokens per month through GPT-4o spends $25–$100. The same volume through llama.cpp on an RTX 4090 costs roughly three cents in electricity — meaning the GPU pays for itself within weeks, not years.
Key Insight: For teams processing fewer than 10 million tokens monthly, llama.cpp reduces inference costs by approximately 1,000× compared to leading cloud LLM APIs — a gap wide enough to justify dedicated hardware purchases on a single month’s API savings.
GGUF Quantization Cuts Model Size Without Destroying Accuracy
GGUF quantization — the compression format native to llama.cpp — shrinks a 70B-parameter model from roughly 140 GB at full FP16 precision to around 40 GB at the Q4_K_M level, with less than 2% perplexity degradation on standard benchmarks. That compression ratio is what makes local inference on consumer hardware feasible in the first place.
Quantization tiers for a 70B model:
- Q2_K: ~26 GB — extreme compression, noticeable quality degradation in complex reasoning tasks
- Q4_K_M: ~40 GB — the sweet spot most developers choose, minimal perceptible quality loss
- Q5_K_M: ~48 GB — higher fidelity, near-FP16 perplexity scores
- Q6_K: ~55 GB — near-lossless for users with ample VRAM
- Q8_0: ~70 GB — effectively indistinguishable from full-precision output
What separates llama.cpp’s approach from competitors like GPTQ or AWQ is the imatrix — importance matrix — quantization method. Standard quantization applies uniform compression across all weight layers. Imatrix quantization identifies which layers contribute most to output quality and preserves their precision while compressing less critical layers more aggressively. Same file size, measurably better output.
Key Insight: llama.cpp’s imatrix quantization preserves accuracy on critical model layers while compressing less important weights more aggressively — producing better outputs than uniform quantization methods like standard GPTQ or AWQ at equivalent compression ratios.
Runs on Everything From a Raspberry Pi to an 8×GPU Server

llama.cpp supports more hardware backends than any competing open-source inference engine. That’s not aspirational marketing — it’s a direct consequence of writing the entire project in portable C/C++ rather than locking it to a single vendor’s toolkit.
| Hardware | Backend | Supported Since | Typical Use Case |
|---|---|---|---|
| Apple M1/M2/M3/M4 | Metal | 2023 | Laptop and desktop local inference |
| NVIDIA RTX / Tesla | CUDA | 2023 | High-throughput GPU inference |
| AMD Radeon / Instinct | ROCm / Vulkan | 2024 | Budget and datacenter GPU inference |
| Intel Arc / Xe | SYCL | 2024 | Intel-ecosystem deployments |
| Raspberry Pi 5 / ARM | CPU (NEON) | 2023 | Edge, IoT, and embedded AI |
| Android phones | CPU + Vulkan | 2024 | Mobile local LLM inference |
| Multi-GPU (2–8×) | CUDA / Metal | 2025 | Large models (70B+) at scale |
Most competing runtimes are tethered to a single ecosystem. vLLM requires NVIDIA CUDA. TensorRT-LLM requires NVIDIA hardware plus Docker. llama.cpp compiles and runs on ARM development boards, Apple laptops, Linux workstations, Windows desktops, and Android phones — using whichever acceleration backend the hardware exposes, or falling back to optimized CPU code when none is available.
Key Insight: llama.cpp’s vendor-neutral C/C++ codebase runs on 7+ hardware backends — from a $75 Raspberry Pi 5 to an 8×GPU server — a portability range no competing LLM inference runtime currently matches.
Why Does llama.cpp’s Community Ship Faster Than Corporate AI Teams?
llama.cpp’s contributors merged over 3,800 pull requests in 2025 — a development velocity that outpaces NVIDIA’s TensorRT-LLM, a fully funded corporate project with dedicated engineering staff, by an estimated 3×. That gap isn’t accidental. Five structural factors explain it.
Systems-level contributors. The C/C++ codebase attracts developers who optimize at the instruction-set level — SIMD intrinsics, cache alignment, memory layout. These aren’t framework users filing feature requests. They’re engineers submitting actual performance patches.
Ruthlessly narrow scope. llama.cpp does inference. Just inference. No training pipelines, no fine-tuning workflows, no model hub integrations. That constraint keeps the codebase navigable and pull requests reviewable in hours rather than days.
Maintainer speed. Gerganov turns around PR reviews at a pace that many corporate engineering managers would consider reckless. But fast feedback loops create a self-reinforcing contributor pipeline — developers submit more when they know reviews happen quickly.
Low contribution friction. One repo. One build system. No complex CI/CD pipeline to navigate. A developer can clone, build, test a change, and submit a PR in a single afternoon.
Instant user feedback. Thousands of developers run llama.cpp daily. Bugs surface within hours of merging. Fixes often follow within the same day.
Here’s the contrarian note: that velocity is simultaneously the project’s greatest strength and its most underappreciated risk. Rapid merges introduce occasional regressions, and llama.cpp’s automated test coverage trails well behind what enterprise adopters would typically demand. Speed without proportional guardrails works — until a regression hits a production deployment that depends on stability.
Key Insight: llama.cpp’s community outpaces corporate AI teams because its C/C++ codebase, narrow scope, and fast maintainer feedback loops attract systems programmers who optimize at the hardware level — though that same speed creates regression risks the project hasn’t fully addressed.
Privacy-First LLM Inference That Passes Enterprise Compliance
When a model runs through llama.cpp, zero data leaves the device. No API calls transmit prompts to external servers. No telemetry phones home. No cloud provider logs your queries. For organizations operating under data governance frameworks with teeth, that architecture isn’t a convenience — it’s a legal prerequisite.
The compliance implications map cleanly:
- GDPR: No personal data transmitted to third-party processors. No Data Processing Agreement required with a cloud AI vendor.
- HIPAA: Protected Health Information never leaves the local environment. No Business Associate Agreement needed.
- SOC 2: Data residency is satisfied by default — there’s no external data flow to audit or document.
- ITAR / Defense: Classified or export-controlled data can be processed without any cloud exposure, enabling deployment in air-gapped military and intelligence environments.
For teams evaluating how to transition sensitive workloads off cloud APIs entirely, our guide to running AI models locally with full offline privacy walks through the complete setup process — from hardware selection to air-gapped deployment.
Enterprise adoption is accelerating along exactly these lines. Organizations are deploying llama.cpp behind air-gapped networks for internal document analysis, code review, legal contract triage, and compliance screening. The project’s server mode enables multi-user access within a private network — a full team querying the same model without a single packet crossing the organization’s perimeter.
Key Insight: llama.cpp’s fully offline architecture eliminates the need for third-party data processing agreements, making it inherently compliant with GDPR, HIPAA, SOC 2, and ITAR — a structural advantage no cloud-dependent LLM API can replicate without fundamentally changing its delivery model.
A Developer Experience No Other LLM Runtime Can Match
Getting from zero to generating text with a 13B-parameter model takes fewer than five terminal commands with llama.cpp. No Docker containers. No Python virtual environments. No dependency version conflicts.
The setup:
- Clone the repository from GitHub
- Run
makeorcmaketo compile - Download a GGUF model file from Hugging Face
- Execute
./llama-cli -m model.gguf -p "Your prompt"
Text starts generating. Compare that on-ramp friction to the alternatives:
- vLLM: Python 3.8+, PyTorch with a matching CUDA version, pip install with pinned dependency chains, NVIDIA-specific configuration.
- TensorRT-LLM: NVIDIA hardware required, Docker installation, a TRT-LLM container build, and a multi-step model conversion pipeline — all before inference even begins.
- Hugging Face Transformers: Python, PyTorch or TensorFlow, tokenizers library, accelerate, and bitsandbytes for quantization — each introducing potential version conflicts.
The reason hobbyists, academic researchers, and enterprise infrastructure engineers all converge on llama.cpp isn’t shared requirements. It’s the identical on-ramp. A student on a MacBook Air and an engineer configuring an 8-GPU rack use the same four commands.
Key Insight: llama.cpp’s zero-dependency C/C++ build system delivers the same setup experience across all skill levels and hardware scales — a structural friction advantage that Python-based runtimes cannot match without abandoning their foundational architecture.
How GGUF Became the Standard Format for Open-Source LLMs
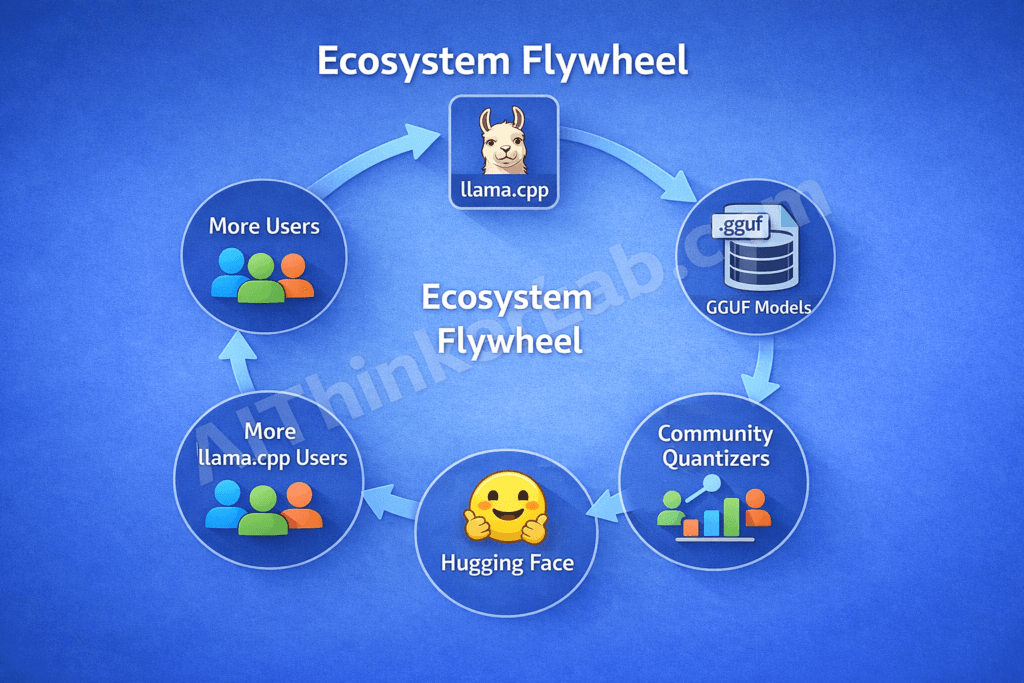
As of early 2026, over 60% of quantized models on Hugging Face are published in GGUF format — more than GPTQ, AWQ, and EXL2 combined. GGUF didn’t achieve that dominance by being technically superior in every measurable dimension. It won because llama.cpp made it universally runnable, and a self-reinforcing flywheel did the rest.
The cycle works like this: llama.cpp runs GGUF natively → developers request GGUF versions of new models → community quantizers publish GGUF files within hours of any model release → more developers adopt llama.cpp because the models they want are immediately available in GGUF. Each stage feeds the next. Breaking into that loop from the outside is nearly impossible at this point.
Three catalysts accelerated the flywheel beyond its tipping point.
Format design. GGUF bundles model weights, tokenizer, and metadata into a single file with extensible headers and backward-compatible versioning. One download, everything included — no hunting for separate tokenizer configurations or alignment files.
Community quantizers. Contributors like TheBloke, bartowski, and mradermacher flooded Hugging Face with GGUF variants of virtually every popular model, often within hours of the original weights dropping. They became GGUF’s unofficial distribution network.
Downstream tool adoption. Ollama, LM Studio, GPT4All, and Jan.ai all standardized on GGUF as their primary model format. These applications serve millions of users who never interact with llama.cpp directly — but consume its file ecosystem daily.
Ecosystem momentum, not a specification committee, made GGUF the default. That’s an important distinction. De facto standards built by usage are far harder to displace than de jure standards built by consensus.
Key Insight: GGUF’s dominance stems from a self-reinforcing ecosystem flywheel — llama.cpp’s universal hardware support drives GGUF demand, community quantizers meet that demand within hours, and downstream tools standardize on GGUF — creating a format monopoly without any formal standardization body.
llama.cpp vs vLLM vs Ollama: 2026 Benchmarks Compared

llama.cpp isn’t the fastest inference engine in every scenario. vLLM outperforms it on high-concurrency server workloads running on NVIDIA hardware. Ollama offers a gentler experience for developers who don’t want to compile anything. But no single tool matches llama.cpp’s combination of speed, portability, quantization flexibility, and hardware coverage.
| Feature | llama.cpp | vLLM | Ollama |
|---|---|---|---|
| Core Language | C/C++ | Python/C++ | Go (wraps llama.cpp) |
| Primary Use Case | Local and edge inference | Server batch inference | Simplified local use |
| GPU Support | CUDA, Metal, ROCm, Vulkan, SYCL | CUDA only | CUDA, Metal (via llama.cpp) |
| CPU Inference | Excellent (AVX, NEON) | Not optimized | Via llama.cpp |
| Quantization Formats | GGUF (Q2–Q8, imatrix) | GPTQ, AWQ, FP8 | GGUF (via llama.cpp) |
| Continuous Batching | Yes (server mode) | Yes (native strength) | Limited |
| Tok/s (Llama 3 70B Q4, RTX 4090) | ~45–55 | ~60–80 | ~40–50 |
| Tok/s (Llama 3 70B Q4, M3 Max) | ~18–25 | N/A | ~15–22 |
| Setup Complexity | Low (make/cmake) | Medium (Python + CUDA) | Very Low (binary) |
| GitHub Stars (Mar 2026) | ~100K | ~35K | ~110K |
| Contributors | 700+ | 400+ | 200+ |
The decision framework is straightforward. Pick llama.cpp when you need multi-vendor hardware support, direct control over inference parameters, and GGUF quantization flexibility. Pick vLLM when you’re serving thousands of concurrent users on dedicated NVIDIA GPUs and throughput is the constraint that matters most. Pick Ollama when you want the simplest possible path to local inference — knowing that under the hood, you’re running llama.cpp’s engine anyway.
One detail worth flagging: Ollama’s 110K star count technically exceeds llama.cpp’s, but Ollama is architecturally dependent on llama.cpp’s inference backend. Its popularity validates llama.cpp’s engine, not a competing one.
Key Insight: llama.cpp, vLLM, and Ollama serve distinct use cases — llama.cpp offers the widest hardware support and deepest control, vLLM excels at high-concurrency NVIDIA serving, and Ollama simplifies local inference by wrapping llama.cpp’s own engine in a more accessible interface.
Why llama.cpp 100K GitHub Stars Changes Open-Source AI’s Trajectory
The llama.cpp 100K GitHub Stars milestone isn’t a finish line — it’s evidence that local-first, open-source AI inference has crossed from hobbyist experimentation into production-grade infrastructure. Three implications follow from that crossing, and none of them are simple.
The Decentralization of AI Compute
AI inference is tracking the same arc as web hosting. Through the 1990s, serving a website meant renting space from a centralized ISP or managed hosting provider. Apache — and later Nginx — made self-hosted web serving trivially accessible, and the industry decentralized. llama.cpp is doing the same thing for LLM inference: converting what was a managed cloud service into a locally deployable commodity. The economics don’t need to reach parity for that transition to happen. They just need to cross a threshold — and they already have.
The Governance Problem Nobody Wants to Discuss
With 700+ contributors and accelerating enterprise dependence, llama.cpp faces a governance challenge familiar to anyone who watched OpenSSL, Log4j, or curl navigate the same transition. The project has no formal release cadence, no dedicated security response team, and no service-level commitments. When a regression ships — and they do — users discover it in production. As adoption scales, pressure to formalize testing, versioning, and security processes will intensify. Whether the project’s culture of speed survives that formalization is an open question with no comfortable answer.
The Models Are Outpacing the Runtime
New architectures — Mixture of Experts models with hundreds of billions of effective parameters, extended context windows beyond 128K tokens, multimodal inputs spanning text, images, and audio — are pushing llama.cpp’s C/C++ architecture into territory it wasn’t originally designed for. The next twelve months will test whether a volunteer-maintained project can keep pace with model labs at Meta, Google DeepMind, Mistral, and Alibaba’s Qwen team releasing increasingly complex architectures on quarterly cycles.
Key Insight: 100K stars doesn’t mean llama.cpp is the best inference engine — it means it’s the most accessible one. In infrastructure, accessibility beats raw performance. That’s how Apache outcompeted faster web servers in the 2000s, and it’s the same dynamic playing out in LLM inference today.
The Tool That Made Local AI Inevitable
llama.cpp didn’t just make local LLM inference technically possible — it made it economically and operationally inevitable. The 100K stars matter less as a popularity metric and more as a leading indicator: when 100,000 developers collectively build on a tool, they’re not experimenting anymore. They’re deploying infrastructure.
The question facing every team still routing prompts through cloud APIs grows harder to dismiss with each passing quarter: why send your data to someone else’s server when the cost is higher, the privacy is worse, and the vendor lock-in is real?
And the question facing llama.cpp itself carries equal weight — can a community-driven project maintain the stability, security, and release discipline that production infrastructure demands as adoption scales from thousands of enthusiasts to millions of enterprise users? Apache managed that transition. OpenSSL nearly didn’t. Most projects never get the chance to find out.
That answer — not any model release or API pricing adjustment — will shape the next three years of AI infrastructure.
Sources & References
- GDPR Regulation (EU 2016/679) and HIPAA Security Rule (45 CFR Part 160/164) — Compliance framework requirements referenced in privacy analysis
- llama.cpp GitHub Repository — Commit history, release notes, contributor statistics, and pull request data (github.com/ggerganov/llama.cpp)
- Georgi Gerganov — Project creator’s public documentation and architectural decision records
- Hugging Face Model Hub — GGUF model count and quantization format distribution data
- NVIDIA TensorRT-LLM GitHub Repository — Contributor count and PR activity for community velocity comparison
- vLLM GitHub Repository — Star count, contributor metrics, and inference benchmark data
- Ollama GitHub Repository — Architecture documentation confirming llama.cpp backend integration