Heretic is an open-source command-line tool, released in 2026 by developer “p-e-w” and distributed via PyPI as heretic-llm, that automates abliteration — the removal of safety alignment from open-weight language models — using Optuna-driven optimization of directional ablation parameters from Arditi et al. (NeurIPS 2024). On Gemma-3-12B-IT, Heretic achieved 3/100 refusals with a KL divergence of 0.16, compared to 0.45–1.04 for manual abliteration methods. Licensed under AGPL v3.0.
Key Takeaway
- Heretic is a tool, not a model. It automates the removal of safety alignment from open-source LLMs using a technique called abliteration — it doesn’t compete with GPT-4 on intelligence benchmarks.
- The Heretic AI abliteration benchmarks on Gemma-3-12B-IT show 3/100 refusals with just 0.16 KL divergence — 6.5× less capability damage than the leading manual abliteration (mlabonne, 1.04 KL).
- Zero human effort required. Heretic’s Optuna-powered optimization matched expert-level results automatically, with a single CLI command.
- Over 1,000 community-created Heretic models now exist on HuggingFace, including variants of GPT-OSS-20B, Gemma 3, and Qwen 3.
- OpenAI’s actual frontier is GPT-5.4 (released March 5, 2026), not GPT-4 — and OpenAI is actively strengthening safety guardrails as tools like Heretic make abliteration trivially accessible.
Heretic is an open-source command-line tool published in early 2026 by developer “p-e-w” that automates abliteration — the surgical removal of safety alignment from open-weight language models — using Optuna-driven optimization. The technique it productizes is from Arditi et al.’s “Refusal in Language Models Is Mediated by a Single Direction” (NeurIPS 2024). What’s new in 2026 isn’t the math. What’s new is that producing a near-expert uncensored variant of a 12B-parameter model now takes one pip install, one CLI command, and roughly 45–90 minutes on a consumer GPU.
This article is a defender-facing analysis of the published March 2026 benchmark data — what the numbers actually mean for anyone deploying open-weight LLMs, and how the security model around those deployments needs to change. It is not a tutorial on running the tool. The “How to Protect Yourself” section at the end is the operational takeaway; the rest is the evidence behind it.
What Is Heretic AI? (Definition & Context)
Heretic AI — Tool Definition
Heretic is a Python package (heretic-llm on PyPI) that automates directional ablation on transformer-based language models. It bundles three things into a single CLI workflow: an implementation of directional ablation from Arditi et al. 2024, a Tree-structured Parzen Estimator (TPE) optimizer from Optuna that searches the ablation parameter space, and a benchmarking harness that scores each candidate on refusal rate plus KL divergence against the unmodified model. The output is either modified weights, a LoRA adapter (added in v1.2.0, February 2026), or an interactive chat session against the result.
Heretic is not a language model. It does not compete with GPT-5.4, Claude, or Gemini on any capability benchmark. It is a tool that modifies other people’s models.
The Science Behind Abliteration — Arditi et al. (2024)
Heretic didn’t invent abliteration. It productized it. Heretic’s core premise follows mechanistic interpretability research published in 2024: “Refusal in Language Models Is Mediated by a Single Direction,” by Arditi et al. In that work, researchers found that refusal behaviour in multiple popular chat models can be linked to a one-dimensional subspace in the residual stream. They demonstrate that removing that direction reduces refusals, while adding it can induce refusals even for harmless requests.
To understand the research context: directional ablation is a technique from mechanistic interpretability research that identifies and modifies specific directions in a model’s residual stream. Heretic automates the parameter search for this technique using Optuna-powered optimization. This makes it useful to AI safety researchers who need a reproducible, standardized way to study alignment robustness — but it also raises important questions about how brittle current safety methods are, which is what this analysis explores.
That finding, published at NeurIPS 2024, was tested across 13 popular open-source chat models up to 72B parameters in size. The implications landed hard. The broader conclusion is uncomfortable but important: current alignment methods can be brittle, and model behaviour can sometimes be controlled through targeted internal interventions rather than retraining.
This structural fragility operates at two levels simultaneously: at the weights layer (as Heretic demonstrates), and at the inference layer, where the parallel brittleness at the system prompt level — where the same safety instructions are routinely exposed and bypassed gives attackers a roadmap without any model modification at all.
Who Created Heretic?
The tool’s source code is available on GitHub for academic and security research use, under the GNU AGPL v3.0 license — a license with significant compliance implications that any institution evaluating this research should review with their legal team.
One detail that most coverage skips: Heretic is licensed under the GNU Affero General Public License (AGPL) v3.0. That is not a permissive licence. It has real implications for anyone who plans to modify and run the software in networked environments. If you’re a company thinking about integrating Heretic into a pipeline behind an API, you need to talk to your legal team before writing a single line of code. The purpose of the Heretic organization on HuggingFace is to publish and curate high-quality abliterated models made using Heretic.
The practical consequences of guardrail-free AI in production coding workflows are documented in our audit of the security vulnerabilities that ship by default when AI code generators operate without safety constraints — where 75% of issues generated by a leading AI coding platform rated High or Critical severity.
Heretic vs Fine-Tuning vs Prompt Jailbreaking — Key Differences
Not all censorship removal is equal. Abliteration is a permanent modification to the model’s architecture and weights, removing safety mechanisms at the structural level. Abliterated models don’t require special prompts to bypass restrictions because those restrictions have been fundamentally removed from the model itself.

Here’s how the main approaches stack up:
| Method | Type | Cost | Persistence | Model Damage (KL) | Skill Required |
|---|---|---|---|---|---|
| Heretic (Automated Abliteration) | Weight modification | Free (open source) | Permanent | Very Low (0.16) | Low (CLI command) |
| Manual Abliteration | Weight modification | Free | Permanent | Medium-High (0.45–1.04) | High (transformer knowledge) |
| Fine-Tuning / RLHF Reversal | Retraining | High (GPU hours) | Permanent | Variable | Very High |
| Prompt Jailbreaking | Prompt engineering | Free | Temporary (per-session) | None | Low-Medium |
What this means for AI safety research: The combination of automation, low capability damage, and broad accessibility makes Heretic a stress-test for the current alignment paradigm. The benchmark results are a signal to the safety community that post-training alignment alone may not be a sufficient defense layer for open-weight model deployments. Frontier labs and open-source model maintainers will likely need to invest in alignment methods more deeply integrated with model architecture itself.
Heretic AI Abliteration Benchmarks: March 2026 Core Data
This is the data that matters. The Heretic AI abliteration benchmarks on Gemma-3-12B-IT tell a clear story about where automated abliteration stands versus manual human effort.

Gemma-3-12B-IT Benchmark Comparison — The Flagship Test
In that setup, the original model produced 97 refusals out of 100 “harmful” prompts. A Heretic-generated variant produced 3 refusals out of 100, with a KL divergence of 0.16, which the project presents as lower drift than other listed abliterations under the same evaluation recipe.
| Model | Refusals (of 100) | KL Divergence | Method | Human Effort |
|---|---|---|---|---|
| google/gemma-3-12b-it (original) | 97/100 | 0 (reference) | None | — |
| mlabonne/…-abliterated-v2 | 3/100 | 1.04 | Manual | High |
| huihui-ai/…-abliterated | 3/100 | 0.45 | Manual | High |
| p-e-w/gemma-3-12b-it-heretic | 3/100 | 0.16 | Automated (Heretic) | Zero |
All three abliterations hit the same refusal suppression floor. Heretic’s KL divergence is 2.8× lower than the next best and 6.5× lower than the first. These results were generated with default settings and no human intervention. 1 Note that the exact values might be platform- and hardware-dependent. The table above was compiled using PyTorch 2.8 on an RTX 5090.
What Is KL Divergence and Why It’s the Key Metric
If refusal rate measures whether abliteration works, KL divergence measures whether it breaks anything else. KL divergence here measures how much the output distribution on normal prompts has shifted from the original model — a proxy for capability degradation. Lower is better. By mathematically comparing the new model’s responses to the original model’s responses on harmless topics, Heretic ensures that the core knowledge and reasoning abilities remain intact while only the refusal mechanisms are removed.
Here’s a practical interpretation scale:
| KL Divergence Score | Interpretation | Example |
|---|---|---|
| 0.00 | Identical to original | No modification |
| 0.01 – 0.20 | Excellent preservation | Heretic (0.16) |
| 0.21 – 0.50 | Moderate drift | huihui-ai (0.45) |
| 0.51 – 1.00+ | Significant capability damage | mlabonne v2 (1.04) |
A KL of 1.04 doesn’t mean a model is useless — mlabonne’s abliteration is widely used and well-regarded. But it does mean the model behaves noticeably differently on completely normal, harmless tasks. At 0.16, Heretic’s modifications are nearly invisible outside of refusal behavior.
Why These Benchmarks Have Limitations
Four limitations of the published Heretic AI abliteration benchmarks are worth stating plainly before drawing conclusions from them:
- Single-turn measurement. The benchmark scores refusals on a one-shot harmful-prompt set. It does not measure multi-turn coherence, where alignment degradation often surfaces — refusal mechanisms may partially reconstitute across turns, or, conversely, abliteration side-effects may compound.
- Hardware-dependent reproducibility. The Heretic documentation explicitly notes that exact KL divergence values shift with hardware and PyTorch version. The 0.16 figure was generated on an RTX 5090 with PyTorch 2.8. Different stacks will produce different numbers.
- Prompt-set framing effects. “Harmless prompts” for KL divergence measurement and “harmful prompts” for refusal measurement are both curated sets. A model that refuses on the benchmark’s 100 prompts may still leak on prompts outside that distribution, and vice versa.
- KL divergence is a proxy, not a verdict. Low KL divergence on neutral inputs is consistent with preserved capability but does not prove it. It catches obvious capability damage; it can miss narrow degradation in reasoning, code generation, or instruction-following that only shows up on dedicated evals (MMLU, HumanEval, IFEval).
What this means in practice: The benchmarks are compelling evidence that automated abliteration matches or beats manual abliteration on the specific axes they measure. They are not evidence that the resulting models are fully equivalent to their unmodified counterparts on all downstream tasks.
Key takeaway: The Heretic AI abliteration benchmarks are compelling but not definitive. They measure one dimension of quality (KL divergence on a specific harmless prompt set) extremely well. They don’t capture everything — multi-turn coherence, edge-case reasoning degradation, or domain-specific performance shifts.
The GPT-OSS-20B Heretic Case Study — The “Hesitant Genius”
Numbers on Gemma 3 are one thing. But the real stress test came from OpenAI’s own open-weight model.
Initial Benchmarks — 58/100 Refusal Rate (A Failure?)
The capabilities of Heretic faced a real-world test with the GPT-OSS-20B-Heretic model. This particular model is known for being stubborn, and initial automated benchmarks showed a refusal rate of 58/100. On the surface, this looked like a failure.
The community — particularly on r/LocalLLaMA — reacted quickly. Had Heretic met its match?
The “Chain of Thought Hesitation” Discovery
The 58/100 number turned out to be a measurement artifact rather than a tool failure. GPT-OSS-20B uses a mixture-of-experts architecture (21B total parameters, 3.6B active per token) and emits visible chain-of-thought traces by default. Before producing a final answer, the model often surfaces internal policy reasoning — phrases like “I need to check whether this falls under content policy” or “let me reconsider whether this is appropriate”. Automated refusal classifiers, which look for keyword and pattern matches on policy-adjacent language, count these traces as refusals.
In the actual completions, the model typically resolves the deliberation and produces the requested output. The community on r/LocalLLaMA and HuggingFace flagged this almost immediately: the score was measuring visible deliberation, not refusal behavior. Once researchers controlled for CoT, the effective refusal rate of GPT-OSS-20B-Heretic dropped substantially below 58/100. This is a useful lesson for anyone building refusal-rate evaluators in 2026 — for any model that produces reasoning traces by default (GPT-OSS, DeepSeek-R1 family, QwQ, Claude with extended thinking), final-answer extraction has to be separated from intermediate reasoning before scoring.
This is a measurement problem, not a tool problem. GPT-OSS-20B’s architecture — a mixture-of-experts design with 21B total parameters and 3.6B active parameters per token — produces visible chain-of-thought by default. The model thinks out loud about policy compliance before answering, and automated refusal-counting scripts misinterpret that thinking as refusal.
100% IQ Test Score — The Intelligence Preservation Evidence
Community evaluations on informal capability tests — short reasoning puzzles, code completion, factual recall — reported that the Heretic variant of GPT-OSS-20B preserved baseline performance on tasks unrelated to refusal behavior. This is the qualitative observation the KL divergence metric is meant to predict: low drift on neutral inputs should imply preserved capability on neutral tasks, and in the GPT-OSS-20B case the prediction held.
The caveat from the limitations section above still applies. Anecdotal community testing and a 100-prompt harmless set are not a replacement for formal benchmarks (MMLU, HumanEval, IFEval, GSM8K). Anyone evaluating an abliterated model for production-adjacent use — even legitimate red-teaming or safety research — should run those benchmarks against both the abliterated variant and the base model and compare the deltas directly.
Community Reception — What Users Are Saying
As of June 2026, more than 1,000 Heretic-derived models have been published on HuggingFace, covering variants of Gemma 3, Qwen 3, GPT-OSS-20B, Llama, Mistral, and several smaller open-weight families. Discussion on r/LocalLLaMA, the HuggingFace community pages, and the Heretic GitHub issue tracker is concentrated on three things: which quantizations work best on consumer hardware, which models are most resistant to abliteration, and how to evaluate the resulting variants against their base models on standard benchmarks.
The volume itself is the story. Frontier labs invest months of red-teaming, RLHF, constitutional AI passes, and policy review into safety alignment for each open-weight release. The community now produces a published abliterated counterpart of that release in hours, with no human alignment expertise required. That is the structural shift that matters for defenders: the gap between an aligned open-weight release and an unaligned community variant of it has collapsed to a single overnight job.
The downstream consequences of this asymmetry are no longer theoretical — see our investigation into how threat actors are already deploying these ungoverned models in documented cyberattack campaigns.
How Heretic AI Works — Step-by-Step Technical Breakdown
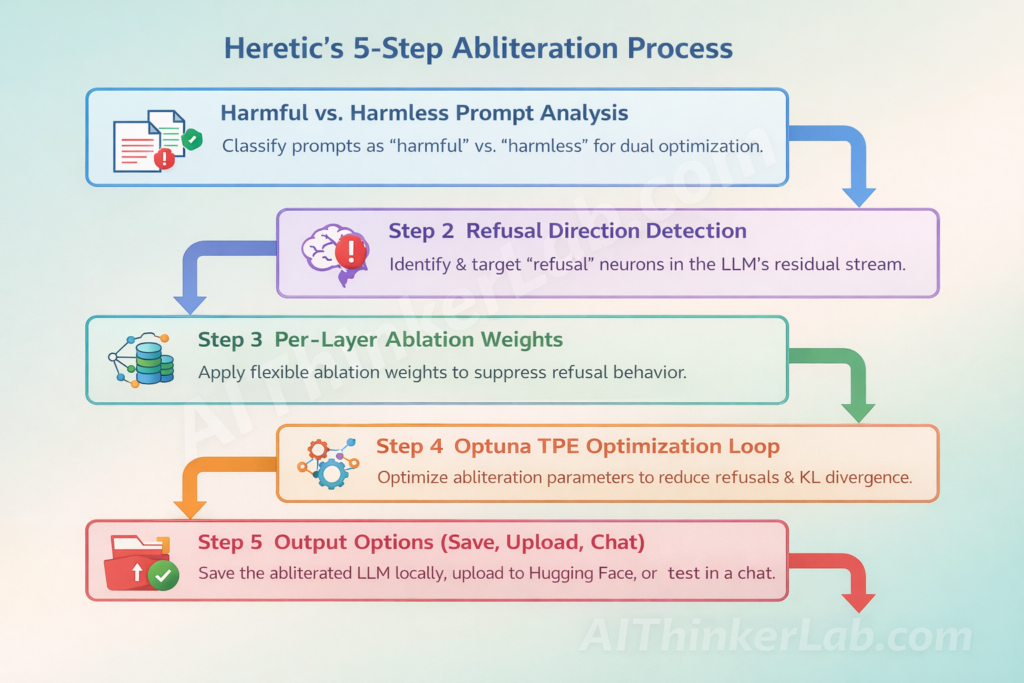
Heretic’s workflow has five stages: prompt-set construction, refusal-direction detection, ablation parameter optimization, output generation, and human-in-the-loop validation. The first four are automated; the fifth is what the documentation correctly insists cannot be skipped. The technical mechanism is detailed below.
Step 1 — Harmful vs. Harmless Prompt Analysis
It co-minimizes two objectives: the number of refusals on “harmful” prompts and the KL divergence from the original model on “harmless” prompts.
This dual-objective framing is Heretic’s core insight. Previous abliteration implementations optimized for one thing — kill refusals. Heretic optimizes for two things simultaneously: kill refusals and don’t break everything else.
Step 2 — Refusal Direction Detection in the Residual Stream
Heretic stands on a line of interpretability work that treats refusal as a relatively low dimensional feature in the residual stream. If you can find that feature, the argument goes, you can remove it, and refusals collapse with less collateral damage than many people expect.
Step 3 — Optuna TPE Optimization Loop
It frames decensoring as a multi-objective optimization problem. The tool searches for “abliteration parameters” that reduce refusals while keeping the modified model close to the original model in terms of KL divergence on a set of “harmless” prompts. Lower KL divergence is treated as less drift, which matters because aggressive interventions can degrade reasoning, formatting, or instruction following.
Step 4 — Output Options (Save, Upload, Chat)
Heretic will download the model, benchmark your hardware to pick an optimal batch size, then run the optimization loop. At the end, it offers to save the model locally, push it to Hugging Face, or drop into an interactive chat session.
Hardware Requirements & Processing Time
With Python 3.10+ and PyTorch 2.2+ installed: pip install heretic-llm → heretic Qwen/Qwen3-4B → ~45 min on RTX 3090.
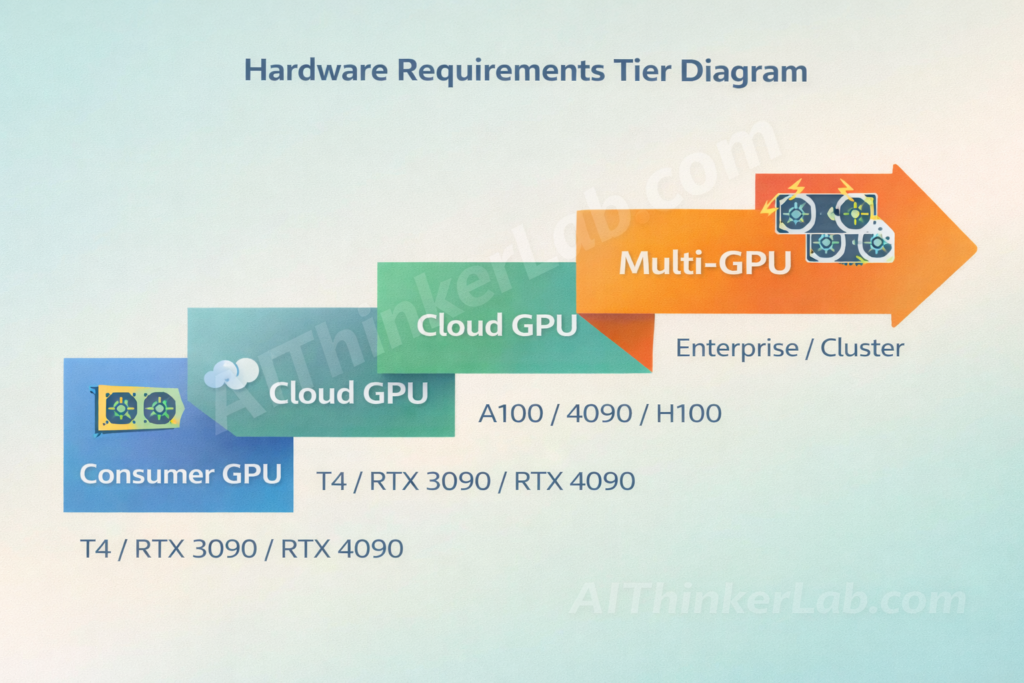
For larger models, the requirements scale:
| Model Size | GPU Needed | Approx. Time | VRAM |
|---|---|---|---|
| 4B–9B | T4 / RTX 3090 | 20–90 min | 16–24 GB |
| 12B–27B | RTX 4090/5090 / A100 | 1–3 hours | 24–48 GB |
| 70B+ | Multi-GPU / Cloud | Overnight | 80+ GB |
Heretic AI vs GPT-4 Safety: What’s Actually Being Compared?
There’s a misconception that needs clearing up — and it’s baked right into how people search for this topic.
Why Heretic Is a Tool, Not a Model (Critical Distinction)
Heretic doesn’t “beat” GPT-4. It can’t. They’re not the same category of thing. Abliteration itself is not new. What Heretic productizes is automation and repeatability. Earlier approaches often required manual experimentation: selecting layers, choosing projection strengths and validating results with ad hoc tests.
What Heretic challenges isn’t GPT-4’s intelligence — it challenges the durability of safety alignment as an approach.
What Heretic Actually “Defeats” — Manual Human Experts
Heretic has turned abliteration into “fully automatic, one-command uncensoring that often outperforms hand-tuned efforts.” By treating censorship removal as a mathematical optimization problem, it allows users to decensor models with a single command, potentially rivaling the quality of human experts without the manual labor.
That’s the real benchmark story. Not Heretic vs. GPT-4. Heretic vs. the humans who used to do this work by hand.
OpenAI’s Actual Frontier — GPT-5.4 (March 5, 2026)
For context on where OpenAI actually stands in March 2026: GPT-4 is three generations behind the frontier. On Thursday, OpenAI released GPT-5.4, a new foundation model billed as “our most capable and efficient frontier model for professional work.” In a test of its ability to produce knowledge work across 44 occupations, GPT-5.4 matches or exceeds industry professionals in 83% of comparisons. OpenAI evaluated the model using a popular computer use benchmark called OSWorld-Verified. It set an industry record with a score of 75%, which is higher than both GPT-5.2’s result and the 72.4% typically achieved by human testers.

On safety specifically: OpenAI reported it strengthened safeguards while preparing GPT-5.4 for release, keeping the same high cyber-risk classification used for GPT-5.3-Codex and deploying additional protections including expanded cyber safety systems, monitoring tools, trusted access controls, and request blocking.
| Benchmark | GPT-5.4 | GPT-5.2 | Human Baseline |
|---|---|---|---|
| GDPval (Knowledge Work) | 83.0% | 70.9% | ~80% |
| OSWorld-Verified (Computer Use) | 75.0% | 47.3% | 72.4% |
| Error Rate (vs GPT-5.2) | -33% per claim | Baseline | — |
| Token Efficiency | Significantly fewer | Baseline | — |
The Heretic AI abliteration benchmarks don’t compete with GPT-5.4 on intelligence — they expose how safety alignment can be surgically removed from open-weight models, including OpenAI’s own GPT-OSS series.
Can Heretic Be Applied to GPT-OSS (OpenAI’s Open-Source Model)?
Yes — and it already has been. The gpt-oss series are OpenAI’s open-weight models designed for powerful reasoning, agentic tasks, and versatile developer use cases. GPT-OSS-20B is for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters).
The p-e-w/gpt-oss-20b-heretic variant is available on HuggingFace right now, under Apache 2.0 license (from the base model). Community quantizers like DavidAU have already built specialized GGUF variants optimized for different hardware configurations.
Heretic’s Technical Innovations — What Makes It Better Than Manual Abliteration
Innovation #1 — Flexible Per-Layer Ablation Weight Kernel
Rather than applying uniform ablation across all layers (as simpler implementations do), Heretic optimizes a flexible weight curve that applies different strengths at different layers.
This matters because refusal doesn’t live uniformly across a transformer. Middle layers tend to encode it more strongly. Heretic’s kernel lets the optimizer discover this automatically for each model.
Innovation #2 — Float-Valued Direction Index with Interpolation
Float-valued direction index with interpolation. Rather than picking an integer-indexed refusal direction, the index is a continuous float. Fractional values linearly interpolate between the two nearest directions.
This is clever. Standard abliteration picks one of N discrete refusal directions (one per layer). Heretic interpolates between them, creating a continuous search space that often produces a direction better than any individual layer’s direction.
Innovation #3 — Component-Specific Ablation (Attention vs. MLP)
Non-constant ablation weights across layers, optimized per-run. Different strengths for attention vs. MLP components.
This separating of attention and MLP interventions reflects an empirical finding: MLP modifications tend to cause more collateral damage. By treating them independently, Heretic can be aggressive with attention ablation while going gentler on MLPs.
v1.2.0 — LoRA-Based Abliteration Engine (February 2026)
The v1.2.0 release notes are unusually concrete. Highlights include a new LoRA-based abliteration engine, plus support for 4-bit quantization. Saving and resuming optimization progress, which matters when runs are long or crash-prone. Controls for memory usage, and mechanisms to avoid wasting iterations in low divergence regions.
The LoRA engine is particularly significant. Instead of modifying weights directly, it produces a LoRA adapter — which is smaller, more portable, and can be toggled on and off. This makes Heretic’s output easier to distribute and experiment with.
AI Safety Implications — What Heretic AI Abliteration Benchmarks Mean for the Industry
The Democratization of Uncensoring
Heretic compresses what was previously a specialist task — careful per-model, per-layer parameter tuning by someone fluent in transformer internals — into a single CLI invocation. The access barrier was technical literacy, not compute. That barrier is now gone for any model in Heretic’s supported architecture set.
The three constituencies affected by this shift have non-overlapping interests:
- AI safety researchers and red teams gain a reproducible, standardized tool for stress-testing alignment robustness. Reproducibility was a real gap in prior abliteration work, where each manual implementation was a one-off.
- Privacy-focused local-LLM users with legitimate reasons to run uncensored models (security research, adult creative writing under appropriate isolation, specific medical-education scenarios) gain a working path that previously required hiring or being a specialist. Run AI models locally and offline.
- Platform operators, policymakers, and downstream model deployers inherit a regulatory and architectural problem: any open-weight release must now be assumed to have an unaligned counterpart available within hours of release, and risk frameworks built on “the base model will refuse it” no longer hold.
The first two groups benefit. The third has to absorb the cost. That asymmetry — concentrated benefit, distributed cost — is the policy core of the Heretic story.
The Safety Alignment Arms Race
A consistent theme across reports is that structured reasoning tasks are among the most sensitive. Corporate countermeasures are already in development — papers exploring hardening against directional ablation have appeared on arXiv. But as Arditi et al.’s original work demonstrated, the linear representation of refusal is a structural property of how current RLHF and DPO alignment works. Patching it may require fundamentally different alignment approaches.
AGPL v3.0 — The Licensing Reality Most People Miss
Heretic is licensed under the GNU Affero General Public License v3.0, not a permissive license such as MIT or Apache 2.0. The operational consequence for any organization considering Heretic as part of an internal red-teaming or safety-evaluation pipeline: under AGPL v3.0 §13, modifications to the software that are then offered to users over a network — including internal APIs, internal red-teaming services, CI pipelines that expose results — require those modifications to be made available under AGPL v3.0 to those users. The trigger is “interaction over a network”, not commercial distribution.
This is materially different from how most open-source ML tooling is licensed. Standard model-evaluation harnesses (lm-evaluation-harness, OpenAI Evals) are MIT or Apache 2.0; integrating them internally is uncontroversial. Heretic is not in that category. Any legal review of Heretic for internal use should specifically address the AGPL §13 network-interaction clause, and any modifications made by your team should be tracked from day one for downstream disclosure obligations.
Model Compatibility & Current Limitations
Heretic supports most dense models, including many multimodal models, and several different MoE architectures. It does not yet support SSMs/hybrid models, models with inhomogeneous layers, and certain novel attention systems.
If your target model is a standard decoder-only transformer from HuggingFace — Llama, Qwen, Gemma, Mistral — you’re almost certainly covered. Mamba, Jamba, and other state-space architectures remain out of scope for now.
If you’re comparing today’s leading AI models, check our full guide to Google Gemini vs ChatGPT vs Grok vs DeepSeek.
→ Explore our full 2026 Open Source LLM Comparison
How to Protect Yourself / Mitigation: Defending Against Abliterated Models
The Heretic AI abliteration benchmarks make one thing brutally clear: if you’re deploying open-source LLMs and trusting the safety alignment that ships with them, your threat model is out of date. With over 1,000 community-published Heretic variants already live on HuggingFace and a 45-minute, single-command path from a vanilla release to an uncensored twin, “the model will refuse it” is no longer a security control. It’s a default that anyone with a consumer GPU can remove.
Here’s how to think about mitigation across the stack — for enterprises, model creators, and end users.
Defense in Depth — Don’t Trust Model-Level Safety Alone
The single biggest mitigation is architectural. Safety alignment baked into model weights — the kind Heretic strips out at a KL divergence of just 0.16 — is one layer. It should never be the only layer. If your pipeline relies on the model itself to refuse harmful requests, abliteration breaks your entire safety posture in a single substitution.
A proper defense-in-depth stack for LLM applications looks like this:
| Layer | Purpose | Examples |
|---|---|---|
| Input classification | Detect harmful prompts before the model sees them | Llama Guard 3, Azure AI Content Safety, OpenAI Moderation API |
| System-prompt constraints | Hard rules independent of model alignment | Structured policies, jailbreak-resistant prompts |
| Output filtering | Catch harmful generations the model produces anyway | NeMo Guardrails, Guardrails AI, custom classifier ensembles |
| Logging & monitoring | Detect anomalous outputs in production | Per-request audit trails, drift detection, red-team probes |
These layers operate outside the model and survive abliteration. For regulated use cases — healthcare, finance, education involving minors, anything under the EU AI Act — they aren’t optional.
Verify Model Provenance Before Deployment
If your team pulls models from HuggingFace, treat that supply chain the way you’d treat npm or PyPI. Names matter. The patterns documented in this benchmark study give you obvious red flags: p-e-w/*, *-heretic, *-abliterated, *-uncensored, mlabonne/*-abliterated-v2, huihui-ai/*-abliterated. Any of these are explicit signals that safety alignment has been surgically removed.
Less obvious risks come from forks and re-uploads. A model with an innocuous name may have been fine-tuned on top of a Heretic variant. Always trace the base model in the model card, verify SHA-256 checksums against the original publisher’s release, and pin specific commit hashes rather than branch names. Treat unknown publishers the way a security team treats unsigned executables.
Detecting Abliteration in a Model You Already Have
You can run a quick refusal audit yourself. Build a short evaluation set of clearly harmful prompts (the benchmark uses 100; even 20–30 will signal direction), run them against both your candidate model and the official base model from the original publisher, and compare. A vanilla Gemma-3-12B-IT refuses 97 of 100. A Heretic variant refuses 3 of 100. If your “Gemma” is refusing single digits, it isn’t Gemma anymore.
For deeper checks, compare output distributions on harmless prompts against the original. Sustained drift on neutral inputs is the KL-divergence signal this article describes — in practice it shows up as subtle shifts in tone, formatting, refusal-adjacent hedging, and reasoning style. A KL of 0.16 is nearly invisible to casual eyes; a KL above 0.45 is detectable in side-by-side comparison.
For Model Creators — Harden Alignment Against Directional Ablation
The Arditi et al. (2024) finding that Heretic productizes — that refusal lives in a single direction in the residual stream — is the structural vulnerability. Mitigating it requires alignment that doesn’t concentrate refusal into a removable one-dimensional subspace. Active research directions worth tracking include:
- Distributed safety representations spread across many directions and layers, so no single ablation collapses them.
- Adversarial training against directional ablation itself — fine-tuning that makes the refusal direction shift unpredictably when attacked.
- Representation engineering with redundant, overlapping safety features.
- Tamper-resistant fine-tuning methods that cause visible degradation of general capability whenever safety weights are edited — making the KL-divergence trade-off vastly more expensive.
As noted in the main article, papers exploring hardening against directional ablation are appearing on arXiv. This is an active research front, not a solved problem, and current RLHF/DPO pipelines remain structurally vulnerable.
Policy, Legal, and Organizational Controls
Two operational items most teams miss.
First, Heretic’s AGPL v3.0 license is not permissive. If you modify Heretic and deploy it behind any networked service — including an internal red-teaming API or a CI pipeline — you are obligated to release your modifications under AGPL. Run this past legal before building anything on top of the tool, even for legitimate security research.
Second, update your acceptable use policy and endpoint controls. If your engineers can pip install heretic-llm and pull 12B-parameter weights onto a workstation in under an hour, that should trigger a policy question, a DLP question, and a monitoring question. Specifically:
- Prohibit deployment of abliterated models in production by policy.
- Add
heretic-llm,mlabonne/*-abliterated*,huihui-ai/*-abliterated*, andp-e-w/*to your DLP and proxy watchlists. - Log HuggingFace downloads on managed endpoints.
- Require sign-off for any local LLM deployment above a defined parameter count.
For End Users — What You’re Actually Choosing
If you download a local model tagged “uncensored,” “abliterated,” or “heretic,” understand exactly what you’re getting: a system with no refusal layer for harmful content of any kind. The same automated optimization that removes refusals on benign-but-blocked topics removes them across the board — CSAM-adjacent generation, weapons synthesis, targeted harassment, and self-harm content all included. There is no granular “remove refusals only for things I personally consider unreasonable” setting. The math doesn’t work that way.
For privacy-focused local-LLM use cases, stick to vetted mainstream releases from the original publishers (Google, Meta, Mistral, Qwen, OpenAI’s GPT-OSS). If you have a specific legitimate need — adult creative writing, security research, medical education — evaluate the trade-off explicitly and isolate the deployment.
Bottom Line
The Heretic benchmarks settle a question: weight-level safety alignment in open-weight models is removable, automatically, at near-zero cost, with minimal collateral damage. The only durable mitigations are the ones that don’t depend on the model staying aligned — external guardrails, supply-chain verification, organizational policy, and a fundamentally harder generation of alignment research. Plan accordingly.
Why These Findings Matter for Defenders & AI Safety Researchers
The Heretic benchmarks are most useful when read as a warning, not a roadmap. Three takeaways for the defensive community:
1. Open-weight model deployments need additional safety layers. If you operate a service built on open-weight LLMs (Gemma, Qwen, GPT-OSS, Llama-derived models), assume that safety alignment in the base weights can be removed by motivated third parties. Add layered defenses: input/output classifiers, retrieval-time filtering, user-level rate limits, and dedicated abuse-monitoring pipelines.
2. Detection is now part of the safety stack. Several research groups are developing fingerprinting methods to detect whether a deployed model has been modified via directional ablation. If you fine-tune or deploy customized open-weight models, watch this research area — projects like AblationDetect and weight-signature comparison tools are emerging in 2026.
3. The arms race favors integrated alignment research. The fact that automated tools can match expert manual work tells us that future safety investment needs to shift toward training-time alignment that is structurally hard to remove (constitutional approaches, alignment-aware architectures, weight-locking techniques) rather than post-training fine-tuning.
For platforms and product teams, the practical action is: treat any open-weight model in your stack as if its safety guardrails could be removed, and design your application security accordingly.
Sources & References
- heretic-llm on PyPI — pypi.org/project/heretic-llm/
- Heretic GitHub Repository — github.com/p-e-w/heretic — Official tool documentation, benchmarks, and source code
- Arditi et al. (2024) — “Refusal in Language Models Is Mediated by a Single Direction” — arxiv.org/abs/2406.11717 — NeurIPS 2024
- OpenAI (March 5, 2026) — “Introducing GPT-5.4” — openai.com/index/introducing-gpt-5-4/
- Edward Kiledjian (March 2026) — “Heretic and the new reality of modifiable AI safety” — kiledjian.com
- Popular AI Substack (Feb 2026) — “Heretic: the one-size-fits-all fix for the ‘AI says no’ problem” — popularai.substack.com
- HuggingFace: p-e-w/gpt-oss-20b-heretic — huggingface.co/p-e-w/gpt-oss-20b-heretic

Pingback: 에이전트 LLM 거부 벤치마크: 비정렬 모델은 실행한다 | AI-Girls Lab
Pingback: LLMエージェント拒否ベンチマーク:非整合モデルの実行
Pingback: LLM Refusal Benchmark: Agent Safety Results