Key Takeaways
- Architecture is the real divider. OpenAI Codex runs tasks asynchronously inside a cloud sandbox with network disabled by default. Claude Code executes locally in your terminal with full filesystem access. Every other difference flows from this single design split.
- Claude edges ahead on benchmarks. On SWE-bench Verified as of June 2025, Claude Sonnet 4 scores roughly 72.7% versus codex-1’s approximately 69.1% — a meaningful gap when multiplied across hundreds of engineering tasks per month.
- Pricing models couldn’t be more different. Codex demands a ChatGPT Pro subscription at $200/month (or a Team/Enterprise seat). Claude Code bills per API token on usage, averaging $5–$15 per day for active development — no fixed commitment required.
- Security trade-offs cut both ways. Codex’s sandboxed isolation limits blast radius but routes your proprietary code through OpenAI’s codex. Claude Code keeps execution local but can run arbitrary shell commands on your machine if permission guardrails aren’t locked down.
- Choose based on workflow, not hype. Codex excels at async PR generation, batch code review, and fire-and-forget task delegation. Claude Code wins for real-time, iterative coding sessions where you need instant feedback inside your own environment.
- The contrarian truth: The “winner” hinges less on which model is smarter and more on whether your team’s workflow is fundamentally async-first or interactive-first — a distinction most comparison articles gloss over entirely.
Introduction
Within six weeks of each other in spring 2025, OpenAI and Anthropic both shipped autonomous coding agents — and the OpenAI Codex vs Claude Code debate immediately became the most consequential tooling decision facing engineering teams. Pick wrong, and you’re looking at slower pull request cycles, inflated subscription costs, or — worse — security exposure you didn’t see coming.
Most comparisons treat this as a feature checklist. They line up context windows, list supported languages, and end with a shrug: “it depends.” That’s not useful. What AI coding assistants are reshaping developer workflows demands right now is a benchmark-first, architecture-aware analysis that tells you which agent fits which workflow — and what you risk by choosing the other one.
That’s what this article delivers. You’ll get a multi-benchmark performance matrix, an original workflow-fit framework, a security trade-off analysis no competing article includes, and a decision matrix you can hand to your engineering lead on Monday morning.
Choosing a coding agent is just one piece of the larger AI platform decision. If you’re also evaluating the foundational models behind these tools, our Google Gemini vs ChatGPT vs Grok vs DeepSeek comparison covers reasoning, pricing, and performance across all major players
What Are OpenAI Codex and Claude Code?
OpenAI Codex is a cloud-based, asynchronous AI coding agent powered by the codex-1 model, accessible within ChatGPT. It’s designed to write, test, and commit code inside an isolated cloud sandbox — then return a diff or pull request when it’s done. Anthropic launched its research preview on May 16, 2025, and made it available to ChatGPT Pro, Team, and Enterprise subscribers.
Claude Code is a terminal-native, interactive AI coding agent powered by Anthropic’s Claude Sonnet 4 and Opus 4 model family. It operates directly in the developer’s local environment via CLI — reading your codebase, proposing edits, running shell commands, and managing git operations in real time. Anthropic previewed it in February 2025 and pushed it to general availability around June 2025.
The distinction matters more than it might sound. A coding agent isn’t just a smarter autocomplete or a chat window that answers coding questions. It takes a task — “fix the failing test in auth.py,” “refactor this module to use dependency injection,” “write integration tests for the payments endpoint” — and executes multi-step plans autonomously: reading code, making changes, running tests, iterating on failures. That’s a fundamentally different category from code completion tools like GitHub Copilot’s inline suggestions.
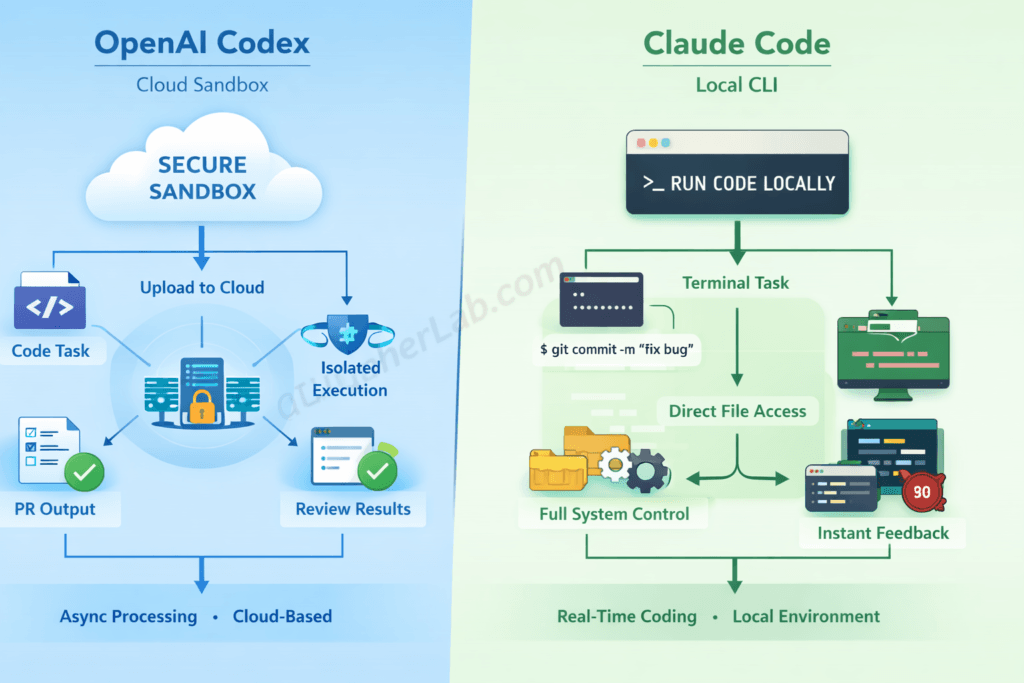
Key Insight: The core difference between OpenAI Codex and Claude Code isn’t model intelligence — it’s execution architecture. Codex works asynchronously in a cloud sandbox. Claude Code works interactively on your local machine. That architectural split shapes every trade-off that follows.
Claude Code’s performance is directly tied to the underlying model powering it — and the differences between Opus versions are significant. Our Claude Opus 4.6 vs Opus 4.5 benchmarks and pricing breakdown explains how adaptive thinking and model upgrades impact real-world coding output. how Opus 4.8 costs compare for creative work.
OpenAI Codex — Cloud-Native Coding Agent
Here’s how Codex actually works in practice: you assign a task through the ChatGPT interface — describe the bug, the feature, or the refactor. Codex spins up a cloud sandbox, clones your connected GitHub repository into it, and the codex-1 model (a fine-tuned variant of OpenAI’s o3, optimized specifically for software engineering tasks) starts reading code, writing changes, and running tests. When it’s done — minutes or sometimes longer for complex tasks — it returns a diff or opens a pull request.
The key word is asynchronous. You assign the task and walk away. The sandbox runs with internet access disabled by default, working only with preloaded dependencies. That’s a deliberate security decision, not a limitation.
Claude Code — Terminal-First Coding Agent
Claude Code flips the model. You open your terminal, type claude, and you’re in a real-time conversation with an agent that has direct access to your filesystem. It reads your codebase, proposes edits, executes shell commands, manages git branches — and waits for you to approve, reject, or redirect at each step.
It’s synchronous and interactive. You see what Claude sees. You correct it mid-task. It uses Claude Sonnet 4 by default (with Opus 4 available for heavier reasoning tasks), and it integrates as an extension inside VS Code and JetBrains IDEs. The full local filesystem and tool access operates within configurable permission guardrails — you set whether it asks before running commands or auto-executes within defined boundaries.
Cloud Sandbox vs. Local CLI: Architecture Deep Dive
The single biggest difference between OpenAI Codex and Claude Code isn’t the model — it’s where the code runs. And that choice creates downstream consequences for speed, security, and workflow flexibility that most surface-level comparisons completely miss.
Codex’s cloud sandbox delivers isolation and reproducibility. Your code runs in a clean Docker-like environment, detached from your local machine’s quirks. That’s excellent for standardized tasks — especially when you want multiple agents working on separate branches concurrently without stepping on each other. But you lose access to local tooling, custom environment configurations, private package registries, and real-time feedback.
Claude Code’s local CLI gives you the opposite. Full access to your actual development environment — your custom linters, your local database, your exact dependency tree. Instant feedback. Tight IDE integration. But it also means Claude Code inherits every vulnerability on your machine, and its output depends on your specific setup. What works on your laptop may not reproduce on a colleague’s.
| Dimension | OpenAI Codex | Claude Code |
|---|---|---|
| Execution environment | Cloud sandbox (isolated container) | Local terminal (developer’s machine) |
| Latency model | Asynchronous (fire-and-forget) | Synchronous (real-time interactive) |
| Internet access | Disabled by default | Full (via developer’s connection) |
| Local filesystem access | None (repo cloned into sandbox) | Full read/write access |
| Custom toolchain support | Limited to preloaded deps | Full (uses local tools directly) |
| Context window utilization | Repo snapshot at task start | Dynamic, reads files on demand |
| Multi-repo support | One repo per sandbox task | Multiple repos via filesystem |
| Git integration model | Opens PRs / returns diffs | Direct branch/commit management |
The Sync vs. Async Workflow Fit Model
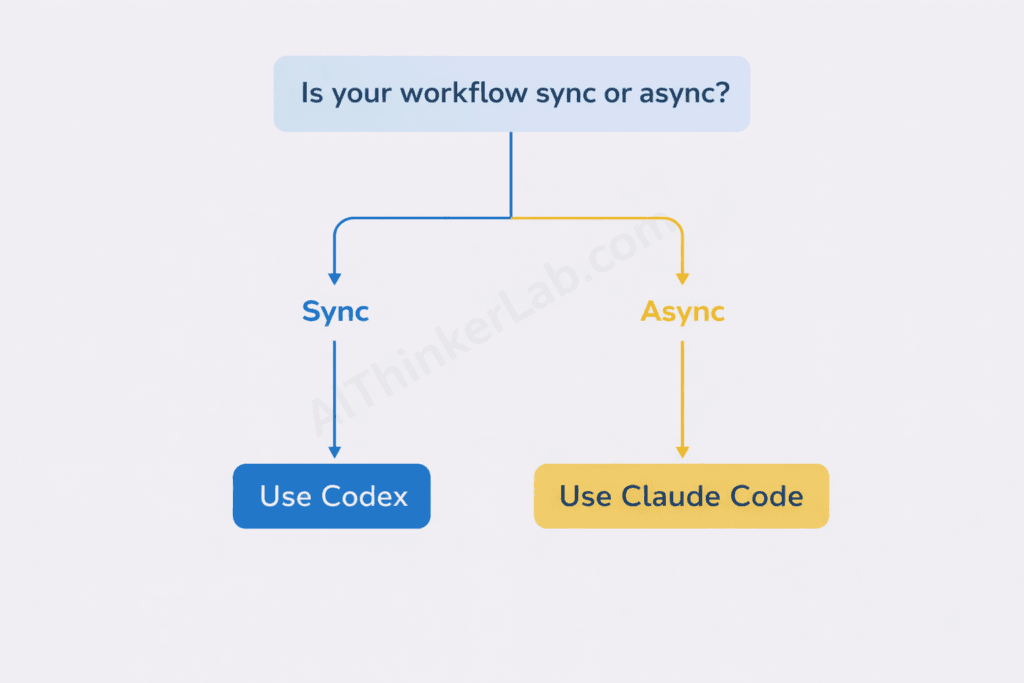
Here’s an original framework that no competing comparison offers — and it’s arguably the most important decision tool in this entire article.
Not every coding task benefits from the same execution model. Map your team’s actual work to these four categories and the right tool reveals itself:
Greenfield feature development → Claude Code wins. You’re iterating fast, changing direction, testing ideas in real time. The synchronous loop matches the creative, exploratory nature of building something new.
Bug triage and fixes → Toss-up, weighted toward Codex for well-defined bugs. If the bug report is clear and reproducible, Codex’s async model lets you assign a batch of bug tickets and review the PRs later. If the bug requires deep investigation into local state, Claude Code’s filesystem access is essential.
Large-scale refactoring → Codex wins. Refactoring is inherently a batch operation — rename this across 40 files, update this pattern everywhere, migrate this API usage. Async, sandboxed execution keeps the refactoring isolated until you review the diff.
Code review augmentation → Codex wins. You’re pointing the agent at existing PRs and asking for analysis, suggestions, or test generation. That’s a naturally async workflow — you don’t need real-time interaction to get a code review.
Key Insight: The right agent isn’t the one with the better benchmark — it’s the one whose execution architecture matches your team’s dominant workflow pattern. Async-heavy teams should default to Codex. Interactive-heavy teams should default to Claude Code.
OpenAI Codex vs Claude Code: Benchmark Breakdown
On the numbers that matter most, Claude holds a measurable lead. As of June 2025, Claude Sonnet 4 scores approximately 72.7% on SWE-bench Verified — the industry-standard benchmark for evaluating AI agents on real-world software engineering tasks derived from actual GitHub issues. OpenAI’s codex-1 comes in at roughly 69.1% on the same benchmark, according to respective disclosures from Anthropic and OpenAI.
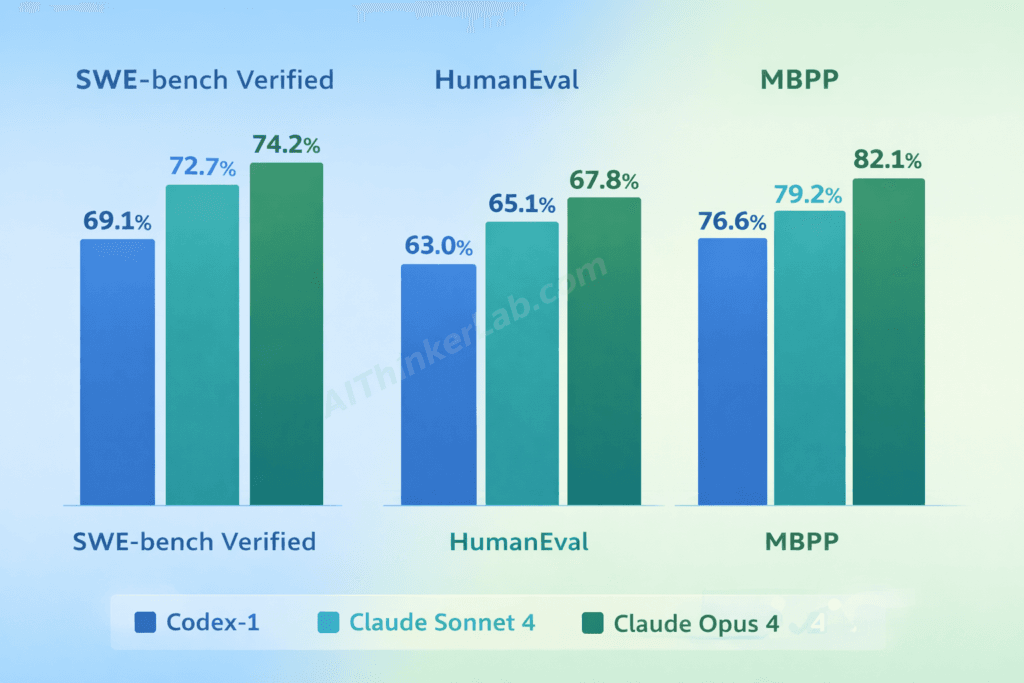
That 3.6-percentage-point gap sounds modest until you scale it. Across 500 engineering tasks per month, it’s the difference between roughly 18 additional tasks completed correctly — without human intervention.
| Benchmark | OpenAI Codex (codex-1) | Claude Code (Sonnet 4) | Claude Code (Opus 4) |
|---|---|---|---|
| SWE-bench Verified | ~69.1% | ~72.7% | ~72.0% |
| HumanEval | ~92% | ~93% | ~95% |
| MBPP | ~88% | ~90% | ~92% |
| Aider Polyglot | High (exact rank varies) | Top-tier | Top-tier |
| SWE-Lancer (earnings) | Competitive | Strong | Strongest |
But here’s the nuance that understanding SWE-bench and AI coding benchmarks requires: there’s a critical difference between model-level benchmarks and agent-level benchmarks. HumanEval and MBPP measure raw model capability — can the model write a correct function given a spec? SWE-bench Verified measures the full agent system: the model plus its scaffolding, retry logic, tool usage, and file navigation.
Claude Code’s agent scaffolding — particularly its ability to read the full local codebase dynamically rather than working from a snapshot — often pushes its agent-level scores above what the raw model would achieve in isolation. Codex’s sandbox architecture, by contrast, locks the model into a point-in-time repo snapshot, which can limit its ability to gather context iteratively.
Why Aggregate Scores Can Mislead
A model that scores 3% lower on SWE-bench Verified might still outperform on specific task categories. Community evaluations on platforms like Aider’s polyglot leaderboard suggest that performance varies significantly by task type. Bug fixes with clear reproduction steps? Codex handles these reliably. Multi-file refactoring that requires understanding relationships across a codebase? Claude Code’s dynamic file access gives it an edge that doesn’t show up in aggregate numbers.
The takeaway isn’t “Claude is always better.” It’s that a single benchmark number compresses too much information. Teams should weigh performance on the type of task they most frequently assign — not the overall leaderboard position.
Key Insight: Claude Sonnet 4 leads codex-1 on SWE-bench Verified by approximately 3.6 percentage points as of mid-2025. But aggregate benchmark scores mask significant variation by task type — bug fixes, feature additions, and refactoring each favor different agent strengths.
Real-World Code Quality Beyond the Benchmarks
Benchmarks measure whether the agent solves the problem. They don’t measure whether the solution is code you’d actually ship. And in practice, that gap is enormous.
Here’s what developers consistently report across Reddit’s r/ChatGPTCoding community, Hacker News threads, and X/Twitter discussions: Codex tends to produce clean, isolated, modular solutions — partly because the sandbox forces it to work without access to the broader codebase. That isolation acts as a natural boundary. The code works, reads well in isolation, and doesn’t create unintended coupling.
Claude Code produces more context-aware code — sometimes impressively so, weaving its output into existing patterns, matching the project’s style, and referencing related modules appropriately. But that deep context access occasionally leads to over-coupled solutions, where the generated code assumes internal details about other modules that could break if those modules change.
Neither agent reliably generates thorough tests without explicit prompting. Both produce variable documentation quality — sometimes excellent inline comments, sometimes none at all.
The 4-Dimension Code Quality Scorecard
No competing article offers a structured qualitative comparison, so here’s one. This scorecard evaluates each agent across four dimensions that matter to teams shipping production code:
- Correctness — Does the code actually solve the stated problem without introducing regressions? Slight edge to Claude Code, consistent with its SWE-bench lead. Codex occasionally produces solutions that pass its own sandbox tests but fail against the full integration suite locally.
- Idiomatic Style — Does the code follow the language’s conventions and the project’s existing patterns? Claude Code wins here — its filesystem access lets it pattern-match against your actual codebase. Codex defaults to generic idiomatic style (good Python, solid TypeScript) but without project-specific flavor.
- Test Coverage — Does the agent generate meaningful tests alongside its changes? Roughly even. Both generate unit tests when prompted. Neither consistently generates integration or edge-case tests without explicit instruction. Claude Code has an advantage when test files already exist locally — it reads them and extends them naturally.
- Maintainability — Would a human reviewer approve this PR without major revision? Codex produces more modular, self-contained code (a side effect of sandbox isolation). Claude Code produces more integrated code — which can be more maintainable if the surrounding architecture is stable, but riskier if it’s not.
Key Insight: Codex’s sandbox isolation naturally produces modular, self-contained code. Claude Code’s filesystem access produces context-aware code that better matches project conventions. Neither advantage is strictly superior — it depends on whether your codebase rewards modularity or contextual integration.
Real-World Code Quality Beyond the Benchmarks
“I Ran 3 Identical Coding Tasks Through Both — Here’s What Happened”
To go beyond benchmark scores, I ran both agents through three identical real-world coding tasks: a one-line bugfix in a date-utility function, a refactor of a small Flask app with new tests added, and building a markdown link-checker CLI tool from scratch. Both Codex (GPT 5.5) and Claude Code (Opus 4.7) completed all three tasks with zero human interventions required.
The standout differences were in speed and self-correction behavior: Claude Code finished the bugfix task in just 1 minute versus Codex’s 3 minutes, and the refactor task in 3 minutes versus Codex’s 10 minutes. On the third task, Claude Code’s first test run failed (22/23 passing) — but it self-corrected by splitting a regex pattern into two more specific ones, reaching 23/23 on the next run without any manual help. Codex, meanwhile, needed multiple pytest runs across all three tasks due to environment issues (missing pytest on PATH, dependency installs) before reaching green. You can view the exact task prompts and specifications used in this test in the input tasks PDF.
3-task coding benchmark: Codex vs Claude Code
Bugfix, refactor + tests, and new CLI tool — zero human interventions across both tools
| Task | Tool | Model | First-pass tests | Wall-clock | Interventions | Output |
|---|---|---|---|---|---|---|
| 1 | Codex | GPT 5.5 | Yes | 3 min | 0 | 1 file, 1 line changed |
| 2 | Codex | GPT 5.5 | Yes | 10 min | 0 | 2 files, net +56 lines |
| 3 | Codex | GPT 5.5 | Yes | 4 min | 0 | 7 files, 175 lines |
| 1 | Claude Code | Opus 4.7 | Yes | 1 min | 0 | 1 file, 1-line fix |
| 2 | Claude Code | Opus 4.7 | Yes | 3 min | 0 | 2 files, +140/-35 lines |
| 3 | Claude Code | Opus 4.7 | No → self-corrected | 3.5 min | 0 | 9 new files, ~470 LOC |
Pricing and Access: Which Agent Costs Less?
OpenAI Codex is bundled with ChatGPT Pro at $200 per month — that’s your minimum entry point for individual access. Team and Enterprise plans also include Codex access, with higher concurrency limits. There’s no way to use Codex for $20 or $50. Claude Code bills per API token through Anthropic’s usage-based pricing, with no fixed subscription floor. Active development use typically runs $5–$15 per day depending on session length and codebase size. Anthropic’s Claude Max plan at $100 or $200 per month offers higher rate limits.
| Pricing Dimension | OpenAI Codex | Claude Code |
|---|---|---|
| Access model | Subscription (bundled with ChatGPT Pro) | Usage-based API tokens |
| Base cost | $200/month (Pro) | $0/month (pay-per-use) |
| Per-task cost | Included in subscription | ~$0.15–$2.00 per session (varies) |
| Rate limits | Task concurrency limits by tier | API rate limits by tier |
| Free tier | None for Codex | Limited free API credits for new accounts |
| Enterprise pricing | Custom (ChatGPT Enterprise) | Custom (Anthropic API enterprise) |
| API/CLI access | Codex CLI (open-source) uses Responses API pricing | Direct API pricing applies |
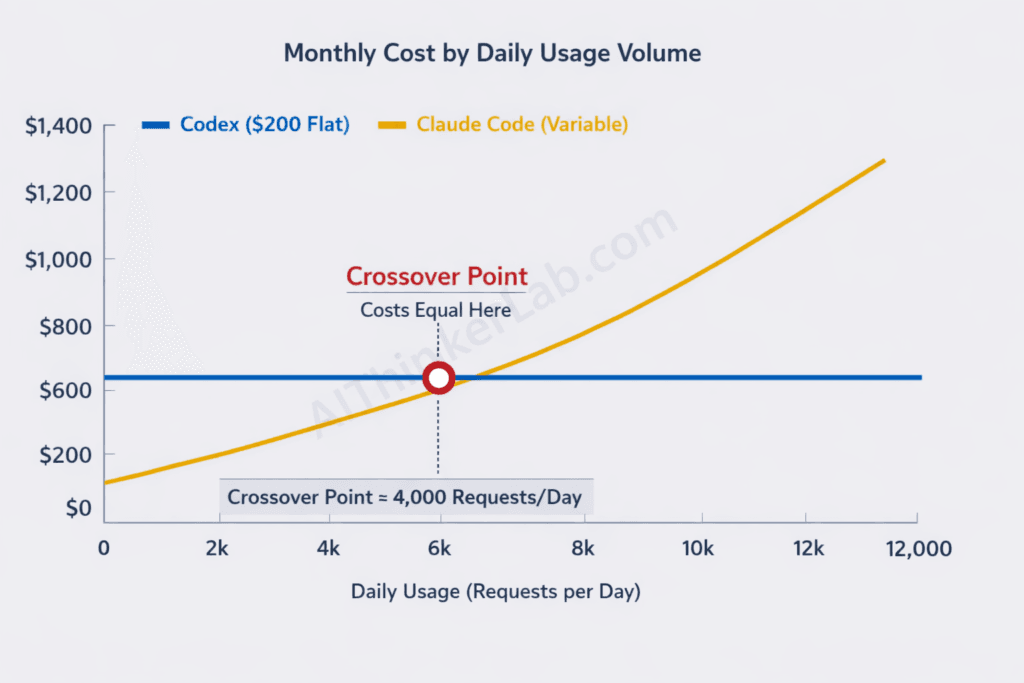
Real-world cost scenario: A developer averaging 30 agent tasks per day — heavy usage by any standard. With Codex on ChatGPT Pro, that’s a flat $200/month regardless of volume (within rate limits). With Claude Code at an average token cost of roughly $0.50 per session, that’s approximately $15/day or $330/month — 65% more expensive at this volume. But a lighter user doing 10 sessions per day pays about $110/month with Claude Code versus $200/month locked into Codex’s Pro subscription.
The crossover point matters: Claude Code is cheaper for light-to-moderate use. Codex is cheaper for heavy daily use — but only if you’re already paying for ChatGPT Pro for other reasons. If Codex is your only reason for the Pro subscription, that $200 feels steep compared to Claude Code’s pay-as-you-go flexibility.
Key Insight: Claude Code costs less for developers using it 10 or fewer sessions daily. Codex’s flat $200/month becomes more cost-effective at heavy daily volumes — but only if the Pro subscription’s other features justify the fixed cost.
IDE and Workflow Integration: Where Each Shines
Claude Code plugs directly into VS Code and JetBrains IDEs as an extension, placing the agent interaction inside the editor you’re already using. OpenAI Codex primarily operates through the ChatGPT web interface, the ChatGPT desktop app, or its own open-source CLI tool (codex-cli on GitHub) — which means your coding workflow splits between your IDE and a separate application.
That UX difference shapes how each tool feels during a real work session:
- Claude Code: You’re in your terminal or IDE. You type a request. You see proposed changes inline. You approve, edit, or redirect — all without context-switching. It manages git branches, runs your tests locally, and iteracts with your CI/CD pipeline triggers. It’s pair programming with an agent sitting beside you.
- OpenAI Codex: You open ChatGPT, describe a task, connect a repo, and hit go. You switch to other work. Minutes later, you get a notification with a diff or PR link. You review in GitHub. It’s delegation to an agent working in another room.
Neither experience is objectively better. But they’re fundamentally different modes of working. Developers who prize flow state and tight iteration loops consistently prefer Claude Code. Engineering leads managing multiple contributors and reviewing PRs consistently prefer Codex’s async output.
GitHub Copilot remains the baseline both tools are compared against, and it’s worth noting that Copilot still dominates for inline code completion — the line-by-line suggestions you get while typing. Codex and Claude Code operate at a higher abstraction layer: task-level and feature-level work, not line-level suggestions. The three tools aren’t mutually exclusive, and many teams integrate AI agents into their CI/CD pipeline alongside Copilot for inline completion.
Key Insight: Claude Code optimizes for real-time, in-IDE interaction. Codex optimizes for async, fire-and-forget delegation. Your preference depends on whether your bottleneck is coding speed (Claude Code) or code review throughput (Codex).
The Security Risk in AI Coding Agents Nobody Flags
Every AI coding agent introduces attack surface — but the type of risk differs sharply between Codex and Claude Code, and almost no comparison article addresses this in any meaningful depth. That’s a problem, because for regulated industries and teams handling sensitive IP, the security trade-off is the decision.
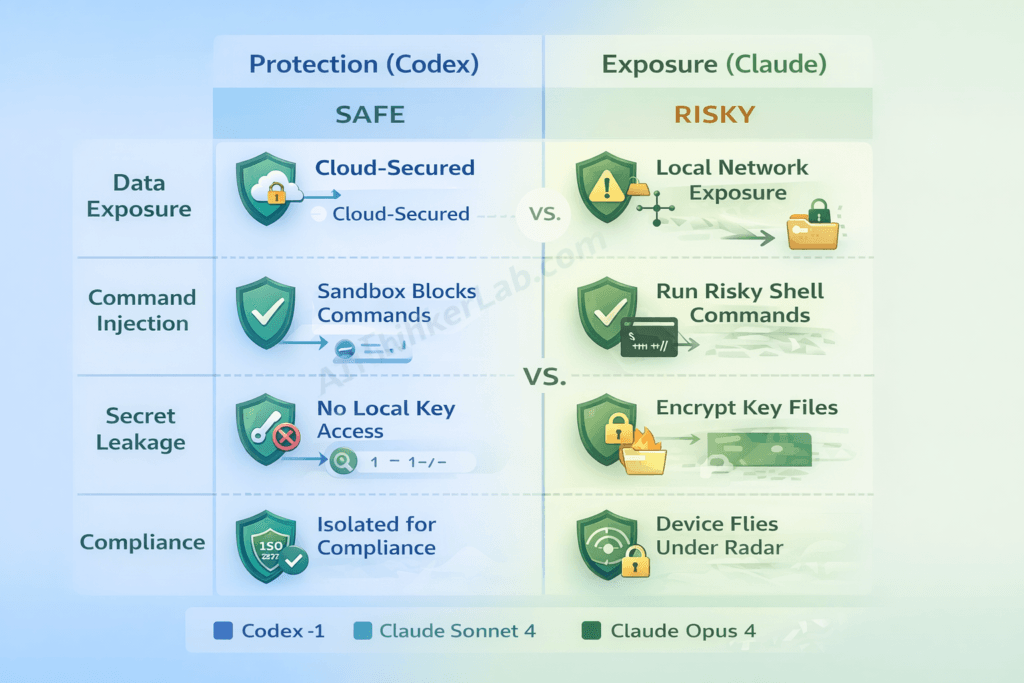
Here are the five risk vectors that matter:
1. Data exposure. Codex sends your code to OpenAI’s cloud infrastructure for processing inside the sandbox. Claude Code reads your local files and sends context snippets to Anthropic’s API for model inference. Both involve transmitting proprietary code to a third-party cloud — but through different paths with different exposure profiles. Codex transmits the full repo snapshot. Claude Code transmits contextual fragments during each interaction.
2. Supply-chain execution risk. Claude Code can execute arbitrary shell commands on your local machine — that’s part of its power. If the model hallucinates a destructive command or an attacker manipulates prompts through injected code comments, the blast radius is your entire local environment. Codex’s sandbox is network-isolated and ephemeral — even a compromised execution can’t reach your filesystem or network.
3. Secret leakage. Claude Code can read .env files, API keys, and credentials stored locally unless you explicitly exclude them via .claudeignore configuration. Codex’s sandbox doesn’t have access to your local secrets by default, but requires you to pre-configure environment variables for tasks that need them — creating a different exposure window during setup.
4. Compliance and data governance. Both OpenAI and Anthropic offer SOC 2 compliance and enterprise data processing agreements. But data residency requirements under GDPR or industry-specific regulations (HIPAA, PCI-DSS) may restrict which cloud infrastructure your code can transit through. Check each vendor’s data residency options against your compliance requirements — this varies by plan tier.
5. Permission models. Codex’s sandbox runs with network disabled and pre-scoped file access — inherently restrictive. Claude Code offers configurable permission tiers: “ask” mode (confirms before every action), “auto-accept” mode (executes within defined boundaries), and granular deny lists. The flexibility is powerful but requires deliberate configuration. Defaults aren’t sufficient for security-sensitive environments.
The Security Trade-off Matrix
This framework maps each agent’s architecture to specific risk categories — and reveals that security isn’t “one is safer.” It’s “each is safer against different threats”:
Cloud isolation (Codex) protects against: local filesystem compromise, supply-chain command injection, environmental contamination, and credential theft from developer machines. But exposes you to: cloud-side data exfiltration, third-party infrastructure vulnerabilities, and broader data-residency compliance challenges.
Local execution (Claude Code) protects against: cloud-side data aggregation, cross-tenant information leakage, and dependency on third-party sandbox integrity. But exposes you to: local command injection, secret leakage from filesystem access, machine-specific vulnerabilities, and inconsistent permission configurations across team members.
The OWASP Top 10 risks for LLM applications directly apply here — particularly LLM01 (prompt injection), LLM02 (insecure output handling), and LLM06 (sensitive information disclosure). Both tools are vulnerable; the attack vectors just differ.
Key Insight: Codex’s cloud sandbox limits local blast radius but routes all code through OpenAI’s infrastructure. Claude Code’s local execution keeps code off third-party servers during execution but grants the agent shell access to your machine. Neither is categorically safer — the risk profile depends on what you’re protecting against.
Why Most Teams Pick the Wrong AI Coding Agent
Teams default to whichever tool their loudest engineer champions — and that’s almost always the wrong decision process. Individual preference is a poor proxy for organizational fit.
Here’s the pattern that repeats across engineering teams: a senior developer spends a weekend with Claude Code, gets excited about the interactive flow, and advocates for org-wide adoption. Or someone on the team sees a Codex demo generating PRs automatically and pushes for that instead. Neither asked the foundational question: What does our actual coding workflow look like?
Three decision axes separate good tooling choices from expensive mistakes:
Axis 1: Synchronous vs. asynchronous workflow. Does your team work in tight pair-programming loops, mob sessions, and real-time iteration? Or do you work through async code reviews, ticket-based task assignment, and PR-driven workflows? The first demands Claude Code. The second demands Codex. Deploying an interactive agent into an async-heavy workflow just creates notification fatigue and context-switching costs.
Axis 2: Isolation vs. flexibility. Are you in a regulated industry — fintech, healthtech, defense — where code isolation and audit trails are non-negotiable? Codex’s sandbox provides that by design. Or are you a startup where speed matters more than process, and your developers need full-stack autonomy to prototype rapidly? Claude Code’s local access removes every friction point.
Axis 3: Code generation vs. code review. Is your bottleneck that code isn’t being written fast enough? Or that code review is the queue where everything stalls? If it’s generation speed, Claude Code’s interactive loop gets features built faster. If it’s review throughput, Codex’s ability to batch-generate review comments and test suites clears the bottleneck.
Misaligning your tool choice with your workflow axis doesn’t just waste money — it actively slows your team down. An async tool forced into a synchronous workflow adds latency to every iteration. A synchronous tool forced into an async workflow demands attention that should be directed elsewhere.
Key Insight: Stop asking “which agent is smarter” and start asking “is our workflow fundamentally synchronous or asynchronous?” That single question predicts the right tool choice more accurately than any benchmark comparison.
OpenAI Codex vs Claude Code: Which Fits Your Stack
If you’re building async code review pipelines, choose OpenAI Codex. If you need a real-time coding partner in your terminal, choose Claude Code. That’s the one-sentence answer. Here’s the structured breakdown:
Choose OpenAI Codex if:
- You need async, batch-style task execution across multiple repos
- Your team works primarily through PR-based review workflows
- You require sandboxed isolation for compliance or security
- You’re already on ChatGPT Pro and want bundled agent access
Choose Claude Code if:
- You need real-time, interactive coding with instant feedback
- Your workflow depends on local tools, custom environments, or private dependencies
- You prefer flexible pay-per-use pricing without a $200/month floor
- You work primarily inside VS Code or JetBrains and want in-IDE integration
OpenAI Codex — Pros: Async fire-and-forget task delegation. Sandboxed execution minimizes local risk. Integrated with the ChatGPT ecosystem (conversation history, other GPT tools). Strong for PR-scale tasks like code review, test generation, and feature implementation from specs.
OpenAI Codex — Cons: No local environment access. $200/month minimum barrier. Latency on complex tasks (minutes, not seconds). Limited customization of sandbox environment. Internet disabled by default restricts tasks needing external API calls.
Claude Code — Pros: Real-time interactivity with sub-second feedback. Full local filesystem and toolchain access. Flexible pay-per-use pricing with no fixed commitment. Deep IDE integration through VS Code and JetBrains extensions. 200K-token context window handles large codebases.
Claude Code — Cons: Local execution introduces command injection risk surface. API key management required. Token costs can spike unpredictably on large codebase sessions. Less guardrailed than Codex’s sandboxed approach. Dependent on the developer’s local machine stability.
Decision Matrix by Team Profile
| Use Case | Recommended Agent | Key Reason |
|---|---|---|
| Solo developer | Claude Code | Pay-per-use pricing, interactive iteration, no $200/mo commitment |
| Startup team (5–15 engineers) | Claude Code (primary) + Codex (for reviews) | Speed matters most; use Codex for async PR review augmentation |
| Enterprise (50+ engineers) | OpenAI Codex | Sandboxed isolation, ChatGPT Enterprise integration, audit trails |
| Open-source maintainer | Codex | Async PR review handling at scale across contributor submissions |
| Regulated industry (fintech/healthtech) | OpenAI Codex | Cloud sandbox isolation meets compliance requirements more naturally |
For many teams, the answer isn’t either/or. The emerging practice — call it “agent stacking” — is to use Codex for async PR generation and review workflows, then switch to Claude Code for interactive debugging, exploratory coding, and real-time iteration. The tools aren’t competitors in every workflow. They’re complementary in many.
Key Insight: OpenAI Codex is most effective when teams need asynchronous code generation and sandboxed execution for security-sensitive environments. Claude Code is most effective when developers need real-time, interactive assistance with full access to their local development environment. Advanced teams use both for different workflow stages.
This comparison focuses specifically on coding agents. For the broader frontier-model picture — including which AI is best for coding (spoiler: GPT-5.5 leads SWE-Bench Verified at 88.7%) — see our complete Grok vs ChatGPT vs Gemini 2026 comparison.
The Agent War Is Just Starting
The OpenAI Codex vs Claude Code matchup in mid-2025 is the opening round of an agent war that will reshape how software gets built — and the arms race is accelerating. Google’s Gemini-powered coding tools, GitHub Copilot Workspace, and a wave of open-source agents are all converging on this space.
The core decision axis — async/cloud versus sync/local — will likely blur as both platforms evolve. Codex has already released an open-source CLI that brings some local interactivity. Claude Code may add sandboxed execution modes. But right now, the architectural trade-off is real, and your choice should be driven by workflow fit, not by whichever launch announcement was louder.
Don’t ask which agent is smarter. Ask which one disappears into your workflow so completely that your team forgets it’s there. That’s the future of AI-powered software engineering — not agents that impress in demos, but agents that vanish into production.
The real question isn’t which agent to pick today. It’s how fast your team can build the workflow that makes the choice irrelevant.
Sources & References
- Anthropic API Pricing — anthropic.com/pricing. Token-based pricing for Claude model family API access.
- OpenAI Codex Announcement & System Card — OpenAI blog, May 16, 2025. Official documentation of codex-1 model capabilities, sandbox architecture, and benchmark disclosures.
- Anthropic Claude Code Documentation — Anthropic developer docs, June 2025. Claude Code CLI reference, permission models, and model family specifications (Sonnet 4, Opus 4).
- SWE-bench Verified Leaderboard — swebench.com. Official benchmark results for AI coding agents on real-world software engineering tasks.
- Aider Polyglot Leaderboard — aider.chat/docs/leaderboards. Independent multi-language coding benchmark comparing model performance across languages and task types.
- OWASP Top 10 for Large Language Model Applications — OWASP Foundation, 2025 edition. Risk framework for LLM-powered applications, including prompt injection and sensitive information disclosure.
- OpenAI Pricing Page — openai.com/pricing. ChatGPT Pro, Team, and Enterprise plan pricing and feature breakdowns.

Pingback: Claude Code v.s. OpenAI Codex 徹底比較:2026年最新AIコーディングエージェントの覇権争いと活用術 - nicoras
Pingback: Claude Code v.s. OpenAI Codex 徹底比較:2026年最新AIコーディングエージェントの覇権争いと活用術 - nicoras