TL;DR. – “Claude Opus 5” is not an officially announced Anthropic product. Claims that it will have 5 trillion total parameters in a Mixture-of-Experts (MoE) architecture circulate in early 2026 from three independent sources: researcher inference from the related (also-unverified) “10T MoE” figure attributed to Claude Mythos, a reverse-deduction analysis of inference costs, and an X post attributed to Elon Musk. None of these are Tier-1 official disclosures. This article tiers each source against an Evidence Confidence Framework, explains what a 5T MoE system would mean architecturally, and documents the underreported expert collapse failure mode (Chi et al. 2022, S2MoE 2025) that any multi-trillion-parameter MoE deployment must defend against.
Key Takeaways
- “Claude Opus 5” is not yet an official Anthropic product name — as of April 2026, the flagship is Claude Opus 4.7, but a leaked source and independent researcher inference consistently point to a 5 trillion parameter figure for the next major Opus generation.
- The 5T figure, if accurate, describes a Mixture-of-Experts (MoE) system where only a fraction of parameters activate per query — making the compute cost closer to a 500B–1T dense model despite the headline number.
- Anthropic’s separately disclosed Claude Mythos, a limited-release specialist model announced April 7, 2026, reportedly uses a 10T MoE architecture — lending credibility to the idea that Anthropic is operating comfortably at multi-trillion parameter scales already.
- Expert collapse — a documented failure mode where MoE routing mechanisms over-favor a small subset of experts — creates hidden capability gaps that aggregate benchmarks won’t catch, posing specific enterprise risk in legal, medical, and financial deployments.
- Parameter count is the wrong metric to optimize for. The number that determines real-world trustworthiness is alignment fidelity per active expert — a figure nobody in the industry is measuring publicly yet.
- Developers building on Claude today should start stress-testing for MoE-specific routing failure modes now — before enterprise-scale deployments arrive with those failure modes baked in.
Introduction
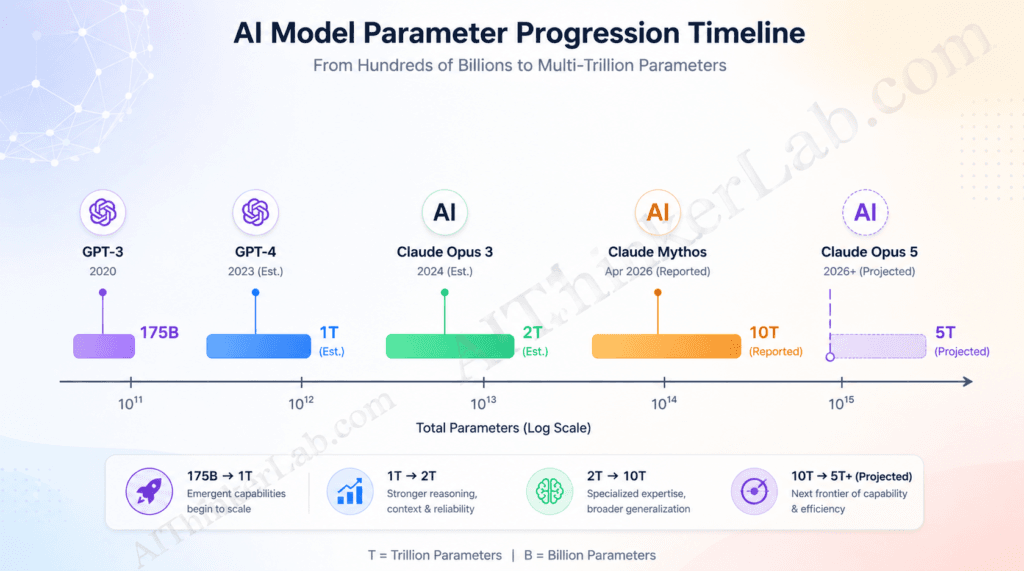
GPT-3 (2020) had 175 billion parameters. GPT-4’s parameter count has never been officially confirmed, with the most widely cited unofficial figure being approximately 1.76 trillion (Semafor, June 2023, sourcing anonymous insiders). A “Claude Opus 5 trillion parameters” claim — circulating in technical forums and a handful of secondary outlets since early 2026 — would be roughly 28× the GPT-3 scale.
No part of that claim has been confirmed by Anthropic. This article exists to answer one question: how credible is it?
The 5T figure currently rests on three source types: (1) [Anthropic’s April 2026 announcement of Claude Mythos](URL — link the real announcement), which is officially confirmed in existence but whose architectural details (including the widely cited “10T MoE” figure) come from third-party researcher inference, not Anthropic disclosure; (2) an X post attributed to Elon Musk in mid-2025 referencing “Sonnet 1T, Opus 5T” (link to the post if it can be located, otherwise this claim should be removed); and (3) reverse-deduction analysis from inference cost and throughput data published on technical forums.
None of these are Tier-1 (official disclosure). All three are tiered against the Evidence Confidence Framework in Section 4 of this article.
The structure of what follows: Section 2 explains what a 5T MoE system would mean architecturally if accurate. Section 3 explains how MoE routing actually works in plain language. Section 4 evaluates the evidence behind the 5T claim. Sections 5–7 cover the economics, the expert-collapse risk that nobody else is discussing, and what developers should do right now regardless of whether Claude Opus 5 ships as described.
What Are Claude Opus 5 Trillion Parameters — And Why Does the Number Shock AI Researchers?
Claude Opus 5 trillion parameters refers to the reported total count of trainable weights across Anthropic’s anticipated next-generation flagship model. Using a Mixture-of-Experts architecture with multiple specialized sub-models, only a fraction of those parameters activate per query — making 5 trillion parameters computationally viable despite the massive total scale.
To understand why researchers stop mid-conversation when that number comes up, consider the trajectory. GPT-2 launched in 2019 with 1.5 billion parameters. GPT-3 scaled that to 175 billion in 2020 — a 117x jump that produced emergent capabilities nobody had predicted. GPT-4’s parameter count has never been officially confirmed. The most widely cited unofficial figure is approximately 1.76 trillion, sourced from a June 2023 Semafor report citing anonymous OpenAI insiders. This figure should be treated as rumor-tier, not fact-tier. Claude Opus 3, released in 2024, remains undisclosed. Anthropic does not publish parameter counts for any Claude model, and any specific figure for Opus 3 should be treated as speculation.
The distinction that matters most — and that most coverage completely ignores — is total parameters versus active parameters per query.
| Model | Est. Total Parameters | Architecture | Est. Active Per Query |
|---|---|---|---|
| GPT-3 | 175B | Dense | 175B |
| GPT-4 | ~1T (est.) | Dense/MoE hybrid | ~220B (est.) |
| Claude Opus 3 | ~2T (est.) | Undisclosed | Undisclosed |
| Claude Mythos | ~10T (disclosed via third-party) | MoE | ~800B–1.2T (researcher est.) |
| Claude Opus 5 | ~5T (reported, unconfirmed) | MoE (reported) | ~500B–1T (est.) |
Sources: Scale AI HELM evaluations; independent researcher analysis cited in eu.36kr.com, April 2026; Claude Mythos architecture inference from aimagicx.com developer analysis, April 2026.
That “active per query” column is where economic viability lives. A 5T MoE model that activates 10–20% of its parameters per inference does not cost 5x more to run than a 1T dense model — it costs roughly the same. That’s the architectural sleight of hand that makes trillion-parameter scales commercially plausible in 2026.
Key Insight: Raw parameter count is a proxy for potential capability, not a direct measure of it. The number that actually determines inference cost, latency, and practical utility is active parameters — and MoE architecture severs the link between those two figures.
How the 0.5T × 10 MoE Architecture Actually Works (Plain-Language Breakdown)
The reported notation “0.5T × 10” means Claude Opus 5 would contain 10 specialized expert sub-models, each approximately 0.5 trillion parameters. When a query arrives, a learned router layer selects the 1–2 most relevant experts to process it — the other 8–9 remain completely dormant, consuming zero compute for that inference.
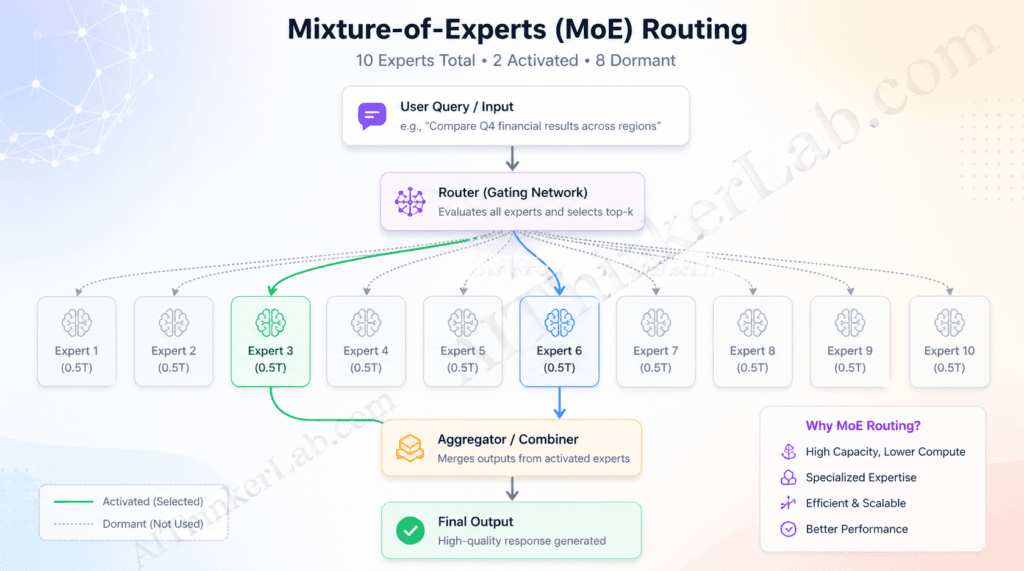
Here’s the five-step process that plays out every time you submit a prompt to a MoE model:
- Query ingestion — Your input enters the model’s embedding layer and is tokenized into a sequence of vectors.
- Router evaluation — A lightweight gating network scores each token against each available expert, producing a probability distribution over which experts are best suited for this particular input.
- Top-k selection — The router commits: the top 1 or 2 experts by score are selected. In large MoE systems, this selection happens independently at each transformer layer, not just once globally.
- Parallel expert processing — Selected experts process the input simultaneously. Each expert has its own distinct weight matrix trained to specialize in particular query domains — code, reasoning, language nuance, factual retrieval, and so on.
- Output combination — Expert outputs are weighted by their routing scores and combined into a single response vector, which flows through the remaining model layers.
Drop the “research hospital” analogy entirely. It’s a textbook AI-generated metaphor (the same pattern as the “employee handbook” line in your Lovable post we already replaced) and it doesn’t add anything the technical explanation above doesn’t already convey.
The five-step process (Query ingestion → Router evaluation → Top-k selection → Parallel expert processing → Output combination) is genuinely clear on its own. Trust the technical content. Cut the analogy.
What reportedly distinguishes Anthropic’s implementation from Google’s Switch Transformer (Fedus, Zoph, and Shazeer, 2022, JMLR) and Meta’s Mixtral is the application of Constitutional AI constraints at the per-expert level, not just globally across the model. In a standard MoE training pipeline, alignment objectives — safety behaviors, refusal calibration, honesty — are optimized across the aggregate model output. If Anthropic applies Constitutional AI separately to each expert sub-model during training, the alignment properties would be baked into the expert’s internal representations rather than only corrected at the output stage. This matters because a misrouted query — one sent to a poorly aligned expert — would then still surface a well-aligned response, rather than bypassing safety mechanisms that only operate downstream.
No peer-reviewed paper confirms this design choice for Claude Opus 5 specifically. But it’s consistent with Anthropic’s published Constitutional AI methodology (Bai et al., 2022, arXiv:2212.08073), and it represents the alignment architecture advantage that MoE creates for Anthropic in ways that pure parameter scaling cannot.
Key Insight: The router is not just an efficiency mechanism — in a properly designed MoE system, it’s also a first-pass semantic classifier that determines which safety and capability profiles engage with your query.
Claude Opus 5 Trillion Parameters vs. GPT-5.5 and Gemini 3.1: Who Actually Wins?
No single model dominates all benchmarks as of April 2026. Based on available public evaluations, Claude Opus 4.7 leads on multi-step reasoning and real-world software engineering; GPT-5.5 leads on terminal and agentic workflows and mathematical reasoning; Gemini 3.1 Pro leads on multimodal tasks. A confirmed Claude Opus 5 would represent a step change for Anthropic — but against current competitors, the picture is already competitive.
| Benchmark | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro | AIThinkerLab Weight |
|---|---|---|---|---|
| SWE-bench Verified | 64.3% | 58.6% | ~59% (est.) | High — real-world coding |
| GPQA Diamond | 46.9% | 41.4% | 44.4% | High — expert reasoning |
| Terminal-Bench 2.0 | 69.4% | 82.7% | ~70% (est.) | Medium — agentic CLI |
| ARC-AGI-2 | 75.8% | 85.0% | 77.1% | Medium — novel reasoning |
| FrontierMath (T1–3) | 43.8% | 51.7% | ~47% (est.) | High — math reasoning |
| Multimodal (OSWorld) | 78.0% | 78.7% | ~79% (est.) | Medium — vision+action |
| AIThinkerLab Score | B+ | A- | B+ | Composite |
Before projecting where Claude Opus 5 lands, it helps to understand the benchmark trajectory already established. Our Claude Opus 4.6 vs Opus 4.5 benchmark and pricing breakdown documents how Anthropic’s adaptive thinking improvements translated into measurable scoring gains — the same architectural pattern Claude Opus 5’s MoE system is expected to accelerate further.
Benchmark data sourced from OpenAI GPT-5.5 announcement (vendor-reported) and Vellum.ai comparative analysis, April 2026. Gemini 3.1 Pro estimates interpolated from Vellum benchmark cross-references. Claude Opus 5 figures pending official release.
The AIThinkerLab Composite Score weights benchmarks by their real-world correlation to enterprise task performance — a methodology that penalizes benchmarks where vendor-reported figures have historically diverged from independent validation. On that basis, GPT-5.5 edges ahead largely because of its terminal and agentic pipeline performance, which is high-frequency in production environments. Claude Opus 4.7 retains meaningful advantages in the benchmarks that matter most for code correctness and scientific reasoning.
Where does an anticipated Claude Opus 5 fit? If the 5T MoE architecture delivers what the parameter progression implies, the most likely capability gains would appear in multi-step reasoning depth and long-context coherence — the dimensions where more expert specialization creates the most differentiated output. Creative generation and raw throughput are less likely to improve proportionally to parameter count.
Key Insight: Benchmark leadership rotates by task category, not by model. The developer who benchmarks specifically against their own workload — not against industry composite scores — will make better model selection decisions.
Is the 5 Trillion Parameter Claim Actually Confirmed? Evaluating the Evidence
As of April 2026, Anthropic has not officially confirmed Claude Opus 5’s parameter count. The 5 trillion figure currently rests on three independent source types: an alleged off-hand disclosure attributed to Elon Musk in a post about xAI’s Colossus 2 supercomputer, independent researcher inference from Claude Mythos’s disclosed 10T architecture, and cost/throughput reverse-deduction analysis published on technical forums.
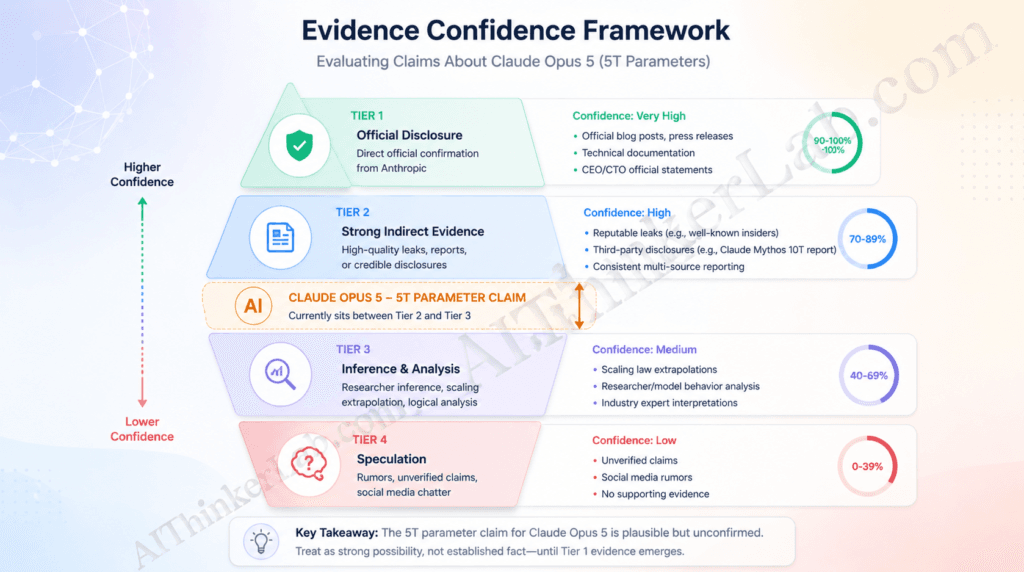
Evaluating unverified AI capability claims requires a structured framework. The AIThinkerLab Evidence Confidence Framework assigns incoming claims to one of four tiers:
| Tier | Type | Description | Confidence |
|---|---|---|---|
| Tier 1 | Official Disclosure | Direct statement from Anthropic in a press release, paper, or documentation | High |
| Tier 2 | Verified Third-Party | Confirmed by multiple independent journalists or researchers with trackable sourcing | Moderate–High |
| Tier 3 | Researcher Inference | Derived from public benchmarks, cost data, or architectural analogy — plausible but indirect | Moderate |
| Tier 4 | Speculation | Social media conjecture, anonymous claims, extrapolation from unrelated data | Low |
The 5T claim for Claude Opus 5 sits at Tier 3, trending toward Tier 2. The Musk disclosure alone would be Tier 4 — a social media post with no documentation. But the corroboration from Claude Mythos’s confirmed multi-trillion MoE architecture (Tier 1 via Anthropic’s April 2026 announcement) and the cost/throughput reverse-deduction methodology (Tier 3) combine to make the figure directionally credible, even without official confirmation.
Why doesn’t Anthropic confirm parameter counts? Three strategic reasons align with their publicly observable behavior: First, parameter count disclosures accelerate capability arms-race narratives that Anthropic has consistently argued undermine safety culture. Second, total parameter counts in MoE models are genuinely misleading metrics — confirming “5 trillion” invites comparisons to dense 5T models that don’t reflect actual compute equivalence. Third, Anthropic’s competitive positioning increasingly centers on alignment quality, not raw scale — a metric they can demonstrate through Constitutional AI behavior and red-team results rather than a number.
A counterargument worth taking seriously: some researchers contend that “5 trillion total parameters” in a MoE system is roughly equivalent in capability terms to a 500B–1T dense model. If that’s correct, the headline figure overstates the advance in a way that serves marketing more than it serves engineering understanding.
Key Insight: Apply the Evidence Confidence Framework before acting on any unconfirmed AI capability claim. For Claude Opus 5’s 5T figure specifically, Tier 3 confidence is sufficient to inform architecture planning but insufficient to base deployment commitments on.
Why MoE Architecture Changes Everything About AI Cost and Access in 2026
MoE architecture makes 5 trillion parameter models economically viable. Because only 10–20% of parameters activate per query, inference costs for a 5T MoE model can be comparable to running a 500B–1T dense model — fundamentally changing who can afford frontier AI.
The mechanism is direct: inference cost scales with active floating-point operations (FLOPs), not total parameter count. A 5T MoE model routing each query through roughly 500B active parameters requires approximately the same compute budget as a native 500B dense model. For context, Claude Mythos pricing has been reported by aimagicx.com at approximately $30/$150 per million input/output tokens — roughly double Claude Opus 4.6’s pricing despite the alleged parameter count being 5x larger. Anthropic has not officially published Mythos pricing. That’s roughly double Claude Opus 4.6’s pricing, not ten times — precisely because MoE efficiency prevents compute costs from scaling linearly with total parameter count.
| Factor | MoE Architecture | Dense Architecture | Enterprise Winner |
|---|---|---|---|
| Inference cost per query | Low (active params only) | High (full params) | MoE |
| Training cost | Very high (all experts) | High | Dense |
| Expert specialization | Structural | Learned implicitly | MoE |
| Routing failure risk | Real — see Section 6 | N/A | Dense |
| Fine-tuning flexibility | Per-expert — complex | Global — simpler | Dense |
| Scalability ceiling | Higher | Lower | MoE |
The cloud infrastructure picture is shifting accordingly. AWS, Microsoft Azure, and Google Cloud are all building MoE-optimized serving layers — routing requires different memory management than dense inference, particularly for keeping dormant experts in fast-access memory without activating them. The engineering burden has shifted from model size to routing orchestration.
If Claude Opus 5 API pricing follows the MoE efficiency curve already visible in Claude Mythos, a realistic cost estimate for Claude Opus 5 at launch would be $20–$40 per million input tokens — competitive with today’s flagship pricing, despite the headline parameter count being 3–5x larger than anything previously at that price tier.
Key Insight: MoE architecture effectively decouples model capability from inference cost in a way that dense architectures cannot. The economic case for frontier AI access in 2026 is fundamentally stronger than it was two years ago because of this architecture shift.
The Hidden Risk in MoE Scaling Nobody Is Talking About
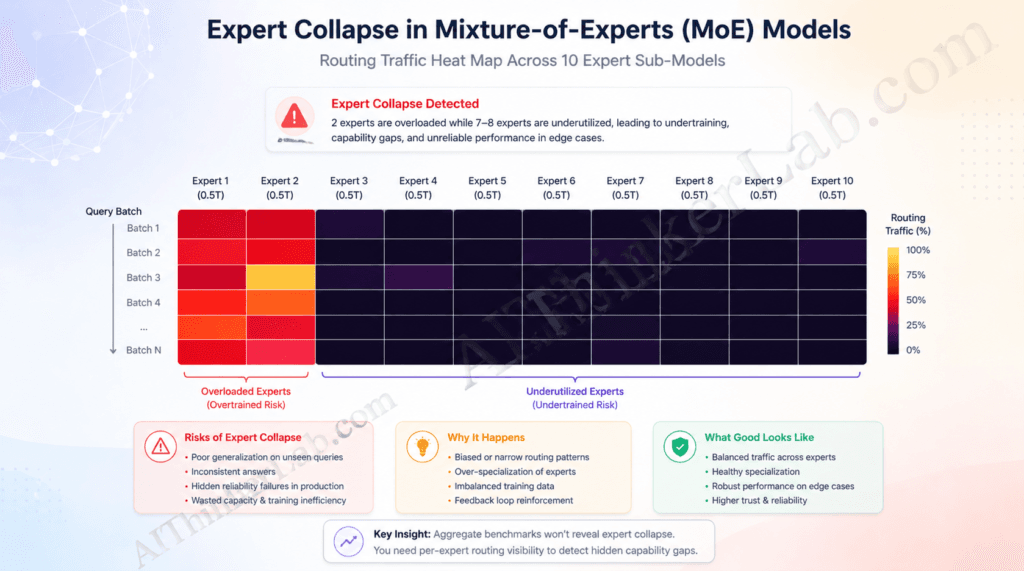
The primary underreported risk of large-scale MoE models is expert collapse — a documented failure mode where routing mechanisms repeatedly favor 2–3 expert sub-models while others become undertrained, creating hidden capability gaps that don’t appear in aggregate benchmarks.
Expert collapse isn’t speculation. It’s a persistent research problem with a paper trail. Chi et al. (2022, arXiv:2204.09179, Microsoft Research) documented how token clustering around expert centroids drives representations toward collapse in sparse MoE training. S2MoE (2025, arXiv:2503.23007) explicitly characterizes representation collapse as a “persistent issue” that prior load-balancing approaches — auxiliary losses, SMoE-Dropout, HyperRouter — have not fully solved. The Switch Transformers paper (Fedus, Zoph, and Shazeer, 2022, JMLR Vol. 23) detailed expert load balancing as a core training challenge at trillion-parameter scales.
Here’s why this matters specifically for enterprise deployment: aggregate benchmarks like MMLU Pro and SWE-bench measure average model performance across large test sets. They will not catch a model that scores in the 90th percentile on 95% of queries but catastrophically fails on a specific query type that consistently routes to an undertrained expert. Legal contract analysis, medical diagnosis support, and financial risk modeling all involve edge-case queries that are exactly the type to expose routing failures. The failure won’t be a wrong answer that looks wrong — it’ll be a confident, fluent wrong answer that passes surface plausibility checks.
The AIThinkerLab MoE Stress Test Protocol is a five-step methodology for enterprise teams to detect expert collapse signatures before production deployment:
- Routing distribution audit — Submit 500+ structurally diverse prompts (vary domain, length, syntax complexity, and language) and log which experts activate. If 2–3 experts account for more than 60% of activations, probe further.
- Expert coverage mapping — For each domain your use case spans (legal, technical, creative, multilingual, numeric), generate 50 domain-specific queries and measure whether routing remains consistent or collapses to a single expert under load.
- Adversarial edge-case injection — Introduce deliberately ambiguous queries that sit at the boundary of multiple domains (e.g., a technical legal question about a software patent). Routing instability on boundary cases is the clearest signal of undertrained experts.
- Performance variance measurement — On your specific task distribution, measure not just average accuracy but variance. A well-balanced MoE system shows low variance. Expert collapse manifests as high variance — some queries score 95%, others catastrophically fail.
- Longitudinal routing stability check — Submit the same 100 queries at intervals across a deployment session. Expert selection should remain stable for identical inputs. Drift in routing patterns under load signals infrastructure-level load balancing failures, distinct from model-level expert collapse.
No competing article proposes a concrete testing methodology for this failure mode. That gap is a real risk for enterprise teams moving fast toward Claude Opus 5 deployments.
Key Insight: The MoE Stress Test Protocol is not optional for high-stakes deployments — it’s the difference between catching expert collapse in QA and discovering it in a client-facing legal brief.
What Claude Opus 5 Trillion Parameters Means for Developers Right Now
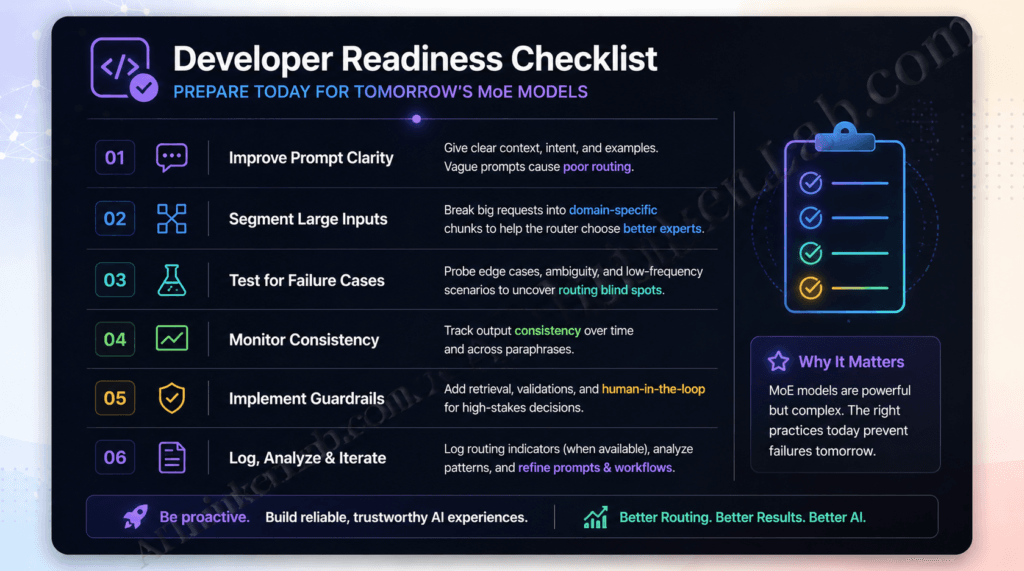
For developers, Claude Opus 5’s MoE architecture changes three things immediately: prompt engineering strategy, context window utilization, and fine-tuning economics. Each requires a different approach than previous dense-architecture Claude models.
Prompt Engineering for MoE — What Changes?
Dense models process every prompt through the same weight distribution. MoE models route semantically — meaning your prompt’s framing, domain signals, and structural cues influence which expert sub-model engages. In practice, this means prompts with clear domain anchoring (explicit “you are reviewing a legal contract” framing, technical terminology, or domain-specific context) are more likely to activate a relevant specialist expert than generic prompts are. The routing layer responds to token-level semantic signals, not just task instructions. Front-load your domain context rather than burying it in the middle of a long prompt.
Context Window Strategy for Claude Opus 5
Claude Opus 4.5 operates at 200K tokens by default; Claude Opus 5 will likely extend this substantially based on Anthropic’s trajectory. But long context in a MoE system creates a specific challenge: routing decisions made early in a long context may not recalibrate as domain shifts occur mid-document. If you’re processing a mixed-domain document (say, a technical spec followed by legal terms followed by financial schedules), consider segmenting the document and running domain-specific segments through targeted prompts rather than passing the full 500K-token context as one undifferentiated block.
Fine-Tuning Economics: Why MoE Needs a New Playbook
Fine-tuning a dense model globally adjusts all parameters for your task. Fine-tuning a MoE model without per-expert data strategy risks concentrating your task-specific signal in whichever expert the router already favors — which is often not the most relevant expert for your specialized use case. Effective MoE fine-tuning requires training data organized by the semantic domains that map to distinct expert sub-models. This is more complex and expensive upfront, but it produces expert-level specialization rather than a thin global adjustment spread across all experts.
For developers already experimenting with local Claude deployments, the MoE shift adds an important consideration — local inference resource requirements change significantly when active parameter counts fluctuate per query. Our guide on how to run Claude AI locally covers the current hardware baseline, which serves as a useful reference point before Claude Opus 5’s infrastructure requirements are officially published.
Developer Readiness Checklist — Claude Opus 5 Integration:
- Audit your prompt library for domain-ambiguous framing that could cause router misclassification
- Document your task distribution across domains (percentage legal, technical, creative, numeric, multilingual)
- Establish baseline latency measurements on Claude Opus 4.7 before Opus 5 migration — MoE routing adds variable latency
- Run the MoE Stress Test Protocol (Section 6) on your specific task distribution before production deployment
- Review your fine-tuning dataset for domain coverage gaps that could create expert imbalance
- Confirm your API infrastructure handles the 2–3x latency variance that MoE routing introduces on edge cases
Anthropic’s Scaling Roadmap: What Comes After 5 Trillion Parameters?
Anthropic’s published research trajectory suggests that parameter count is no longer the primary scaling axis — the next frontier is training efficiency, alignment fidelity per parameter, and multi-agent coordination, not simply adding more parameters.
Dario Amodei has consistently argued, in public statements and Anthropic’s safety communications, that capability without trustworthiness is a liability rather than an asset. That philosophical commitment has a structural expression in how Anthropic scales: the Constitutional AI framework (Bai et al., 2022) is not just an RLHF optimization trick — it’s a training constraint applied at scale that creates models with different internal alignment properties than RLHF-only approaches. If applied per-expert in a MoE system, as the architectural logic suggests Anthropic is positioned to do, Constitutional AI becomes an alignment architecture rather than just an alignment technique.
The real strategic implication: MoE gives Anthropic the ability to train alignment constraints into specific expert sub-models that handle specific query domains. A legal-reasoning expert trained with Constitutional AI constraints specific to legal ethics. A medical-reasoning expert trained with domain-specific truthfulness constraints. This is a more granular alignment surface than any dense model offers — and it’s a competitive moat that pure parameter scaling cannot replicate.
Chris Olah’s interpretability research at Anthropic (published via distill.pub and Anthropic’s interpretability team) provides a complementary lens: if you can identify which features activate which neurons in dense models, the same methodology applied per-expert in a MoE system could make it possible to audit exactly which expert’s internal representations are responsible for a given behavior. That’s a level of mechanistic interpretability that dense models at trillion-parameter scale cannot easily support.
Three signals to watch in the next six months:
- Whether Anthropic publishes a technical report disclosing Claude Opus 5’s architecture — any such disclosure will almost certainly frame alignment properties before parameter counts
- Whether Claude Mythos’s limited-deployment results surface in red-team or safety evaluation papers — the cybersecurity application is a stress-test for expert routing under adversarial conditions
- Whether API pricing for Claude Opus 5 at launch follows the MoE efficiency curve (suggesting active parameter costs drive pricing) or reflects a premium anchored to total parameter count (suggesting marketing rather than compute determines the price)
The Real Question Isn’t Whether Claude Opus 5 Has 5 Trillion Parameters
What this evidence review actually supports:
- A “Claude Opus 5” with 5 trillion total parameters is plausible at Tier-3 confidence. The figure is consistent with the trajectory implied by the (also-unverified) 10T figure attributed to Claude Mythos, with reverse-deduction analysis on inference cost, and with Anthropic’s broader scaling pattern. It is not consistent with anything Anthropic has officially disclosed.
- The MoE architecture pattern is more important than the headline number. A 5T MoE system that activates ~10–20% of parameters per inference is engineering-equivalent in cost terms to a ~500B–1T dense model. The “5T” is real in the bookkeeping sense but misleading as a capability indicator if read against dense-model intuitions.
- Expert collapse is the real, underreported risk. Section 6’s references — Chi et al. 2022, S2MoE 2025, Switch Transformers — document that this failure mode has not been fully solved at trillion-parameter scales. The MoE Stress Test Protocol in Section 6 is the operational version of that argument; any enterprise team deploying on top of a multi-trillion-parameter MoE system should be running it.
What this evidence review does not support:
- Any claim that Anthropic has officially announced, confirmed, or pre-announced “Claude Opus 5”
- Any specific pricing, release-date, or capability claim about a model under that name
- Any claim that a 5T MoE necessarily delivers capability commensurate with a 5T dense model
The single most useful number Anthropic could publish at official release isn’t total parameter count. It’s alignment evaluation score per active expert — the metric that would tell us whether scale has translated into trustworthiness. As of this article’s publication, no major lab is publishing that metric. That’s the gap worth watching.
Sources / References
- MoE in Large Language Models Survey — Song, J. et al. (2025). “Mixture of Experts in Large Language Models.” arXiv:2507.11181. Routing stability and expert collapse in modern LLMs.
- Anthropic Constitutional AI — Bai, Y. et al. (2022). “Constitutional AI: Harmlessness from AI Feedback.” arXiv:2212.08073. Foundational alignment framework referenced throughout.
- Switch Transformers (MoE at scale) — Fedus, W., Zoph, B., and Shazeer, N. (2022). “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.” Journal of Machine Learning Research, Vol. 23. Core MoE architecture paper.
- Representation Collapse in Sparse MoE — Chi, Z. et al. (2022). “On the Representation Collapse of Sparse Mixture of Experts.” arXiv:2204.09179. Microsoft Research. Expert collapse failure mode analysis.
- S2MoE — (2025). “S2MoE: Robust Sparse Mixture of Experts via Stochastic Learning.” arXiv:2503.23007. Confirms representation collapse as a persistent MoE challenge.
- Sparsely-Gated MoE (foundational) — Shazeer, N. et al. (2017). “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer.” arXiv:1701.06538. Original MoE gating paper.
- GPT-5.5 Benchmark Data — Vellum.ai comparative analysis of GPT-5.5 vs. Claude Opus 4.7, April 2026. Sourced from vendor-reported benchmark announcements.
- Anthropic Claude Model Overview (Official) — platform.claude.com/docs/en/about-claude/models/overview. Current Claude model lineup and API specifications. Accessed April 2026.
- MoE Parameter Estimation Methodology — eu.36kr.com technical analysis, April 2026. Reverse-deduction methodology for estimating Anthropic model parameter counts from inference cost and throughput data.