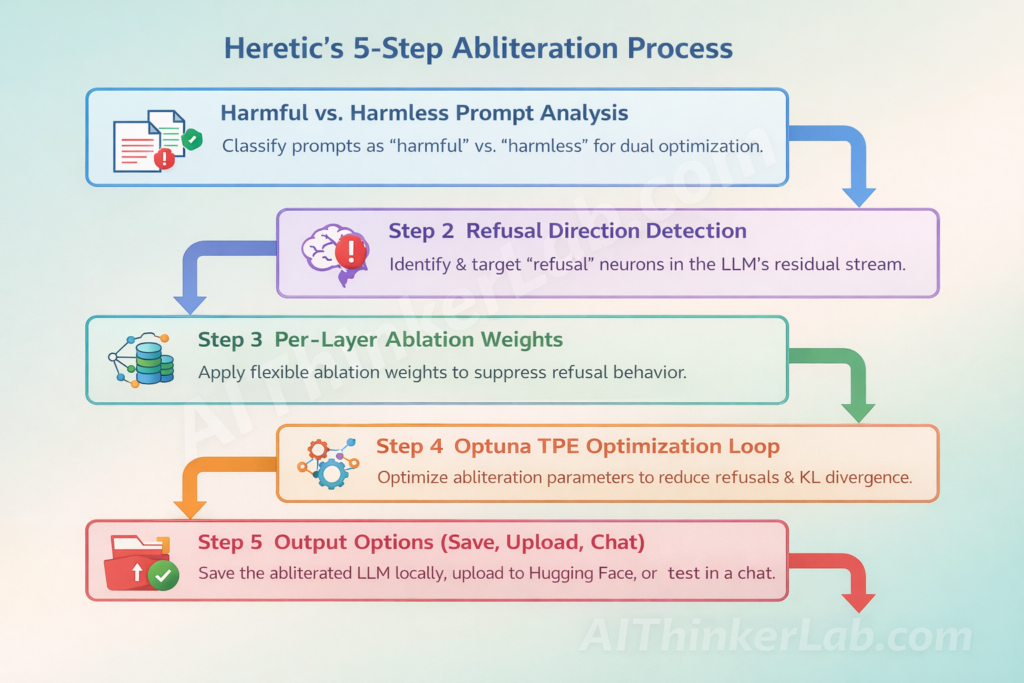
Heretic AI Abliteration Benchmarks: Challenging GPT-4 Safety Alignment at OpenAI (March 2026)
In a world increasingly shaped by artificial intelligence, the stakes for ensuring these systems operate safely and ethically have never been higher. Recent strides in AI development have brought about incredible capabilities, yet they also usher in complex challenges that demand our urgent attention. Enter the Heretic AI Abliteration Benchmarks—an initiative that dares to push boundaries by rigorously evaluating the safety alignment of advanced AI models like GPT-4. These benchmarks serve as a crucial litmus test, revealing just how well—or poorly—AI systems adhere to established ethical guidelines, ultimately questioning the very fabric of their decision-making processes.
March 2026 saw OpenAI step up to the plate with this groundbreaking initiative, challenging the AI community to examine the implications of safety lapses with an unflinching lens. As AI continues to evolve at a breakneck pace, understanding the intricacies of its alignment with human values is not merely a technical issue but a moral imperative. The Heretic AI Abliteration Benchmarks set the stage for transparency and accountability, enabling a deeper exploration into how far we’ve come and what lies ahead in the ever-evolving landscape of artificial intelligence.