Key Takeaways
- MiniMax M2.7 (released March 18, 2026) scored 56.22% on SWE-Pro, matching GPT-5.3-Codex on the industry’s hardest multi-language coding benchmark — while activating only 10 billion parameters, a fraction of what comparable frontier models require.
- Using the OpenClaw agent harness, M2.7 autonomously ran 100+ rounds of self-optimization, achieving a 30% performance gain on internal evaluations without a single human intervention — a first for a commercially deployed LLM.
- On SWE-bench Verified, M2.7 scored 78% versus Claude Opus 4.6’s 55% — a 23-point gap on the benchmark practitioners consider most predictive of production-grade software engineering capability.
- At $0.30/M input tokens and $1.20/M output tokens, M2.7 prices itself aggressively — but its average output verbosity of 87M tokens per evaluation run (vs. a median of 26M) means real per-task costs can run 3x the headline rate.
- The Artificial Analysis Intelligence Index places M2.7 at 50 points — an 8-point jump over its predecessor M2.5 in under a month, ranking it well above average for its price class.
- Organizations still running GPT-4 for production agent workflows are operating two architecture generations behind. M2.7 isn’t just a better model — it represents a structurally different approach to how AI systems evolve.
Introduction
For years, the working assumption in AI development was almost theological in its simplicity: more parameters equal more performance. Bigger models, bigger compute budgets, bigger results. In March 2026, a Shanghai-based startup named MiniMax quietly dismantled that assumption — not with a press conference, but with benchmark numbers.
The debate around Minimax M2.7 vs GPT-4 and Claude isn’t really a fair fight in the traditional sense. GPT-4, released in 2023, belongs to a previous hardware and training era. The more honest and instructive comparison is against Claude Opus 4.6 and GPT-5.3-Codex — the current frontier. And on those terms, M2.7 holds its own in ways that should reorient how development teams think about model selection in April 2026.
What makes M2.7 genuinely interesting isn’t any single benchmark score. It’s the mechanism behind those scores: a model that participated in engineering its own performance improvements, autonomously, across more than 100 training iterations. That’s the paradigm shift worth understanding — and the one most coverage glosses over.
What Is MiniMax M2.7? The Self-Evolving Model Explained
MiniMax M2.7 is a proprietary large language model released on March 18, 2026, by Shanghai-based AI company MiniMax. Built for autonomous, real-world productivity, it achieves Tier-1 benchmark performance while activating only 10 billion parameters — and is notable for recursive self-optimization via the OpenClaw agent harness, through which it improved its own performance by 30% over more than 100 training rounds without human intervention.
That definition is precise enough to be useful, but it understates what makes the architecture remarkable. Most deployed LLMs follow the same lifecycle: pre-train on data, fine-tune with human feedback, freeze weights, ship. Any improvement requires running another training cycle from scratch, which is expensive, slow, and entirely human-directed. M2.7 breaks that pattern.
The model operates with a 200K token context window, accepts text input only (no image or multimodal processing), and uses non-reasoning-by-default inference — meaning it doesn’t engage extended chain-of-thought by default, which keeps response times more predictable. It’s a text-in, text-out model built for depth rather than breadth of modality.
Understanding how large language models are typically trained helps contextualize why M2.7’s approach is unusual. The standard pipeline (pre-training → RLHF → deployment) treats the model as a passive object of improvement. M2.7, through OpenClaw, made the model a participant in that process.
Key Insight: M2.7 isn’t just a model with good benchmark scores — it’s a proof-of-concept for a new training paradigm where the AI actively reduces its own failure rate across consecutive iterations.
The OpenClaw Framework: How M2.7 Improves Itself
OpenClaw is the agent harness MiniMax built to enable M2.7’s self-optimization cycle. The loop it runs is neither magic nor vague — it’s a structured, repeatable six-step process:
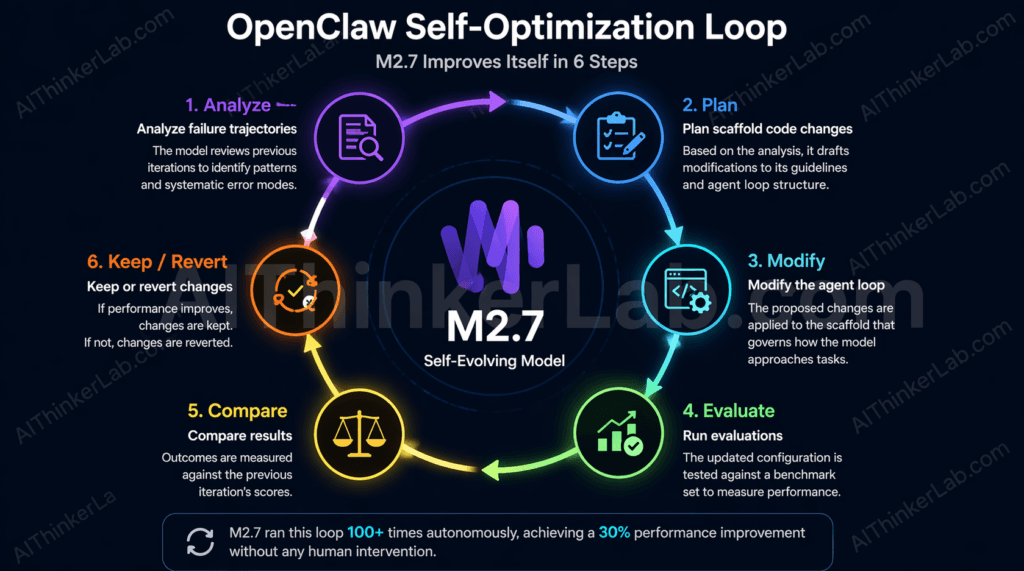
- Analyze failure trajectories — the model reviews where prior iterations went wrong, examining logs and output patterns to identify systematic error modes.
- Plan scaffold code changes — based on failure analysis, it drafts modifications to its own operational guidelines and agent loop structure.
- Modify the agent loop — changes are applied to the scaffold governing how the model approaches tasks.
- Run evaluations — the modified configuration is tested against a benchmark set to measure performance change.
- Compare results — outcomes are measured against the prior iteration’s scores.
- Keep or revert — improvements are retained; regressions are discarded.
M2.7 ran this cycle more than 100 consecutive times. Among the optimizations it discovered autonomously: fine-tuning sampling parameters (temperature, frequency penalty, presence penalty) for different task types; creating a guideline to scan adjacent files for the same bug pattern after identifying one instance; and adding loop detection to prevent infinite agent cycles. These aren’t configurations a human engineer specified — the model identified them as effective through empirical iteration.
This is meaningfully different from standard reinforcement learning from human feedback. RLHF requires human raters at each improvement step. OpenClaw eliminates that bottleneck entirely. OpenRoom, MiniMax’s open-source companion project, extends this interactive paradigm to user-facing applications — but the core self-improvement logic lives in M2.7’s training infrastructure.
Minimax M2.7 vs GPT-4 and Claude: Benchmark Breakdown
The straight-line conclusion from headline benchmarks is that M2.7 competes at the frontier. The more useful conclusion — the one most reviews omit — is which tasks it dominates, which it merely matches, and where it quietly regressed from its predecessor.
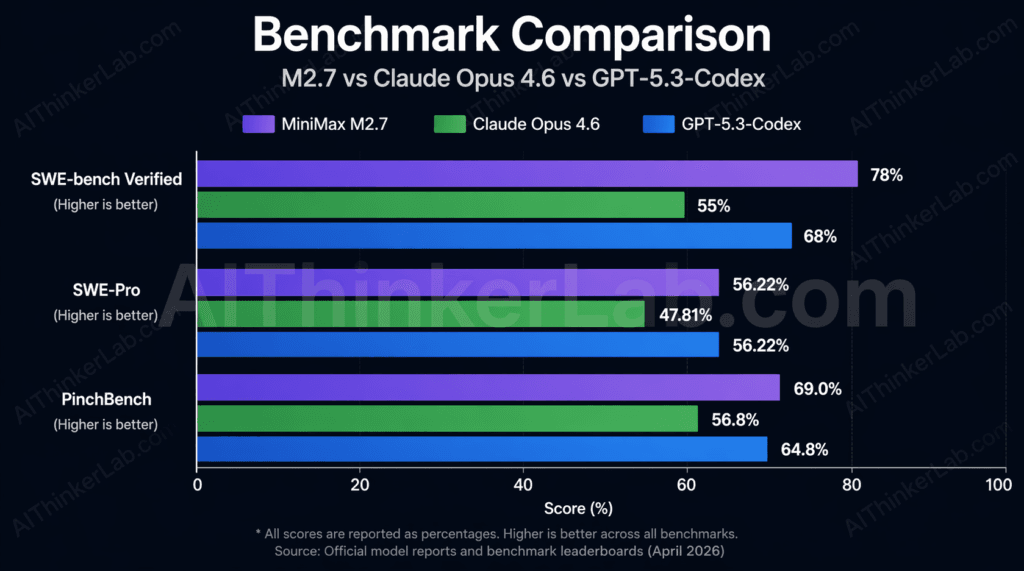
Start with the headline numbers. On SWE-Pro, M2.7 scored 56.22%, landing it alongside GPT-5.3-Codex and significantly ahead of Claude Opus 4.6’s reported performance on the same evaluation. SWE-Pro tests multi-language software engineering across realistic, real-world-style tasks — it’s considered a harder and more ecologically valid measure than the original SWE-bench.
| Model | SWE-Pro (%) | SWE-bench Verified (%) | VIBE-Pro (%) | PinchBench (%) | AA Intelligence Index | Context Window | Input Price/M |
|---|---|---|---|---|---|---|---|
| MiniMax M2.7 | 56.22 | 78 | 55.6 | 86.2 | 50 | 200K | $0.30 |
| Claude Opus 4.6 | Lower | 55 | ~55 | ~87.4 | — | 200K | Higher |
| GPT-5.3-Codex | ~56 | — | — | — | — | — | Higher |
| GPT-4 (legacy) | Significantly lower | Significantly lower | — | — | — | 128K | $10.00+ |
The SWE-bench Verified gap is the most consequential number in this table. A 23-point spread between M2.7 (78%) and Claude Opus 4.6 (55%) on the benchmark practitioners trust most for predicting real engineering output is not a marginal edge — it’s a categorical difference in what the model can reliably deliver. On VIBE-Pro, which measures end-to-end project delivery across Web, Android, iOS, and simulation contexts, M2.7 scored 55.6%, matching Opus 4.6 and establishing it as a credible full-stack project partner, not just a patch generator.
The Artificial Analysis Intelligence Index score of 50 — up from M2.5’s 42 just a month prior — placed M2.7 8th globally and well above the median of 19 for models in its price tier. On GDPval-AA (document processing), M2.7 achieved an Elo score of 1495, the highest among open-accessible models at the time of evaluation.
Here’s the data point most reviews skip: on BridgeBench, the vibe-coding evaluation built by BridgeMind to test natural-language-to-code generation, M2.7 placed 19th — compared to M2.5’s 12th. The newer model performed worse on this specific benchmark. That’s worth noting before any deployment decision. It suggests M2.7’s self-optimization process prioritized complex engineering reasoning over rapid code generation from natural language prompts. Whether that tradeoff fits your workflow depends entirely on what you’re building.
Original Framework — Benchmark ROI: Consider the performance-per-active-parameter ratio. M2.7 activates roughly 10 billion parameters to match models that reportedly engage an order of magnitude more. If GPT-5 engages an estimated 200B+ active parameters and Claude Opus 4.6 operates at comparable scale, M2.7 is generating equivalent SWE-Pro output at approximately 5% of the parameter footprint. Call this “Benchmark ROI” — performance divided by active compute. By that measure, M2.7 is the most efficient frontier-class model currently available.
Key Insight: The 23-point SWE-bench Verified gap over Claude Opus 4.6 is the most meaningful number in M2.7’s benchmark profile — but the BridgeBench regression is equally important context for teams considering it for vibe-coding or rapid prototyping workflows.
Where M2.7 Leads, Where It Falls Behind
Strengths:
- SWE-bench Verified (78%) — current leader among publicly benchmarked models
- SWE Multilingual (76.5) and Multi SWE Bench (52.7) — demonstrates genuine cross-language engineering capability, not English-only optimization
- Hallucination reduction — AA-Omniscience Index score of +1 versus M2.5’s -40, a dramatic improvement in factual reliability
- GDPval-AA Elo (1495) — highest among open-accessible models on document processing
- Unique task solutions — in Kilo Bench’s 89-task evaluation, M2.7 solved problems no other tested model could
Weaknesses:
- Speed: 45.7 tokens/second against a peer-tier median of 109.7 t/s — more than 2x slower than average for its price class
- Verbosity: 87M output tokens generated on the Artificial Analysis Intelligence Index versus a median of 26M — a 3.35x multiplier that inflates real-world costs
- BridgeBench regression — dropped from M2.5’s 12th to M2.7’s 19th place
- Text-only — no image, audio, or document input as of April 2026
- Proprietary weights — model cannot be self-hosted, fine-tuned locally, or audited
M2.7 integrates natively with both Claude Code and OpenClaw — but if you’re still deciding between those two agent environments themselves, our breakdown of OpenAI Codex vs Claude Code covers the infrastructure differences that should inform that choice before you drop any model into the pipeline.
Pricing Compared: M2.7, GPT-4, and Claude Opus
MiniMax M2.7 costs $0.30 per million input tokens and $1.20 per million output tokens — positioning it among the most affordable Tier-1 models via API as of April 2026.
That headline looks compelling until you account for how the model actually consumes tokens.
| Model | Input Price/M | Output Price/M | Tokens/sec | Context Window | Open Source? | Image Input? |
|---|---|---|---|---|---|---|
| MiniMax M2.7 | $0.30 | $1.20 | 45.7 | 200K | No | No |
| Claude Opus 4.6 | Higher | Higher | Faster | 200K | No | Yes |
| GPT-5 (est.) | Higher | Higher | Faster | 128K+ | No | Yes |
| Kimi K2.5 | Lower | Lower | ~Higher | Large | Partial | Partial |
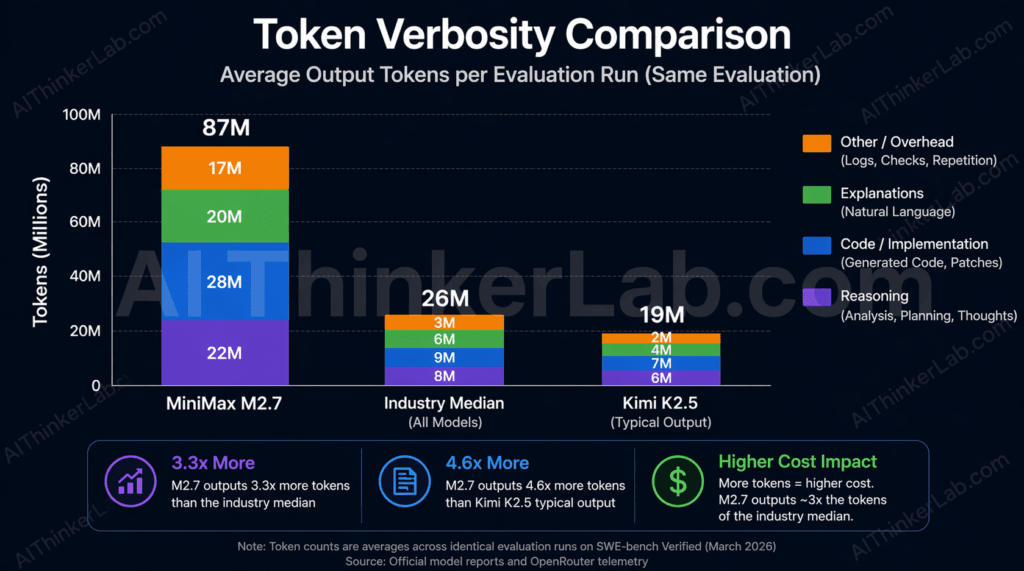
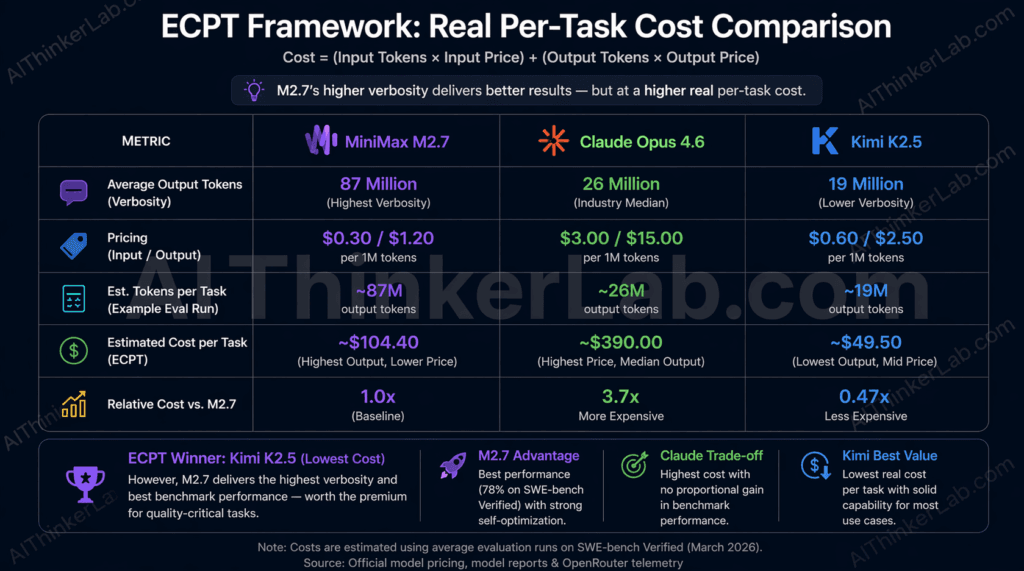
The verbosity problem is real and consistently underreported. Artificial Analysis documented that M2.7 generated 87M tokens during its Intelligence Index evaluation — compared to a median of 26M for comparable models. At $1.20/M output tokens, that differential alone adds meaningful cost to any long-running agentic workflow. Kilo AI’s independent testing corroborates this: M2.7 averaged 2.8M input tokens per trial, the highest consumption rate of any model in their evaluation set. For context, in a code review task, Claude Opus 4.6 consumed 1.18M input tokens on a single pull request — while Kimi K2.5 processed the same diff using 219K tokens. Deep readers find deeper bugs, but they run expensive meters.
Introducing the Effective Cost Per Task (ECPT) framework: Per-token pricing is a unit rate, not a cost forecast. ECPT is the calculation that matters: (average input tokens × input rate) + (average output tokens × output rate) per task. Using Kilo Bench token consumption data, M2.7’s ECPT for complex engineering tasks likely exceeds Claude Opus 4.6’s despite M2.7’s lower per-token rate — because M2.7 reads and writes substantially more per task. Teams that budget based on per-token pricing without modeling task-level consumption will encounter unexpected invoice surprises. Run a pilot on your specific task type before committing to M2.7 at volume.
M2.7 is genuinely cost-efficient for structured, bounded engineering tasks where its thoroughness is warranted and the output length is constrained by task scope. It’s less efficient for open-ended generation tasks where verbosity compounds without a natural ceiling.
Key Insight: M2.7’s per-token rate is low; its per-task cost is not necessarily so. The “verbosity trap” — budgeting on headline pricing without modeling output consumption — is the most common and most expensive mistake teams make when adopting this model.
Comparing M2.7’s pricing against Claude Opus 4.6 is only half the equation — understanding what Anthropic changed between Opus 4.5 and 4.6, and whether that upgrade justifies the cost, is the other half. Our Claude Opus 4.6 vs Opus 4.5 breakdown covers the benchmark shifts, pricing delta, and adaptive thinking changes in full.
M2.7’s Coding Capabilities: Real-World Engineering Performance
M2.7’s strongest differentiator isn’t any single benchmark — it’s what happens on autonomous tasks that no other model successfully completes.
Kilo AI ran 89 tasks through its Kilo Bench evaluation, testing autonomous coding across git operations, cryptanalysis, QEMU automation, and more. M2.7 placed second overall at 47%, two points behind Qwen3.5-plus. But the pass rate obscures the more interesting finding: every model in the comparison — M2.7, Qwen3.5-plus, GLM-5, Kimi K2.5, and Qwen3.5-397b — solved tasks that no other model could. M2.7’s unique wins tend to cluster around problems requiring deep systemic comprehension, not rapid surface-level code generation.
The SPARQL task illustrates this precisely. The problem required correctly identifying that an EU-country filter operated as an eligibility criterion — determining which data qualified for inclusion — rather than an output filter applied after retrieval. Getting this wrong produces syntactically valid but semantically broken queries. M2.7 got it right. The other models didn’t. That’s not a benchmark artifact — that’s causal reasoning about system behavior, which is exactly what production engineering requires.
M2.7’s behavioral signature across Kilo Bench: it reads extensively before it writes. The model traces call chains, maps dependencies, and pulls surrounding files into context before generating a single line of output. On Terminal Bench 2, which demands high system-level comprehension, it scored 57.0%. On NL2Repo (repository-level code generation from natural language), it scored 39.8%. SWE Multilingual came in at 76.5, and Multi SWE Bench at 52.7.
The tradeoff is explicit: that read-heavy profile averages 2.8M input tokens per trial, the highest of any tested model, and creates timeout risk on tasks with strict time budgets. When thoroughness pays off, M2.7 catches bugs that faster, shallower models miss. When the clock matters more than depth, that same thoroughness becomes a liability.
For teams evaluating M2.7 through Kilo Code or KiloClaw, the practical guidance is: deploy it on tasks where getting the answer right matters more than getting an answer fast. Differential cryptanalysis, Cython build debugging, complex inference scheduling — these are where the model earns its place. Simple CRUD generation or rapid prototyping is not its home turf.
Key Insight: M2.7 solves real engineering problems that other frontier models fail on — but its read-extensive behavioral profile makes it unsuitable for time-constrained or speed-sensitive production pipelines.
Is MiniMax M2.7 Better for Agents Than Claude or GPT-4?
For most agent-framework applications requiring complex coding tasks, yes — M2.7 is among the top two or three models available as of April 2026, scoring 86.2% on PinchBench and landing within 1.2 points of Claude Opus 4.6, the current benchmark leader for standardized OpenClaw agent tasks.
But the more precise answer requires a distinction that most coverage ignores entirely.
Introducing the Agent-Native vs. Agent-Capable framework:
Claude Opus 4.6, GPT-5.4, and similar frontier models have been extended to support agent workflows — tool use, multi-step reasoning, external API calls — through capability layers added after core training. The agent behavior is real and often effective, but it’s additive, not foundational.
MiniMax M2.7 is different in kind. OpenClaw wasn’t just a post-training add-on; it was the framework through which M2.7 built and optimized its own training process. The model has been both the operator and the subject of agent workflows from its earliest development stages. That distinction has three practical implications:
- Self-directed error recovery — M2.7 has implicit familiarity with its own failure modes because it spent 100+ training rounds analyzing them. When it encounters a task-level error in production, its error recovery behavior draws on that embedded pattern recognition.
- Lower scaffold overhead — because M2.7 is accustomed to operating within an agent loop, it requires less prompt engineering to behave reliably in multi-step workflows. Models that are agent-capable need more explicit scaffolding to maintain coherent state.
- Implicit knowledge of its own limits — models trained through agent frameworks develop a different relationship to uncertainty than models that are instructed to behave like agents post hoc.
PinchBench scores of 86.2% (M2.7) versus ~87.4% (Claude Opus 4.6) look nearly identical — and for straightforward agent tasks, they probably are. The divergence appears at the edges: complex, multi-system tasks where self-directed recovery matters, where the model has to decide whether to continue or revert, and where deep codebase comprehension is more valuable than speed.
M2.7 integrates natively with Claude Code, Kilo Code, and KiloClaw. Teams already invested in those pipelines can drop M2.7 in with minimal configuration changes and evaluate its performance on their specific task distribution. That’s the right evaluation methodology — not benchmark tables, but your own task set.
Who Built MiniMax? The Company Behind M2.7
MiniMax was founded in 2021 in Shanghai by Yan Junjie, a former researcher at SenseTime, one of China’s largest computer vision companies. The company has grown into one of China’s most technically credible AI labs, backed by Tencent and Hillhouse Capital — two investors with long track records of identifying durable AI infrastructure plays.
Most people outside China encountered MiniMax through Talkie, a social AI platform with millions of active users that lets people build and interact with customizable AI personas. It’s a consumer-facing product, but it’s backed by serious foundation model research. MiniMax-01, the lab’s earlier flagship, deployed a mixture-of-experts architecture with 456 billion total parameters and roughly 45.9 billion active — a model that competed meaningfully with Western frontier labs at the time of its release.
The M2 series represents a strategic inflection. Where MiniMax-01 was open-source and positioned as a contribution to the broader research ecosystem, M2.7’s weights are closed. The company frames OpenRoom (an open-source interactive application built on M2.7’s agent capabilities) as its community contribution, but the core model is firmly proprietary.
This mirrors what z.ai did with GLM-5 Turbo and what the broader Chinese frontier lab ecosystem appears to be moving toward: proprietary models with commercial API access, rather than open weights. Reports suggest Alibaba’s Qwen team is considering a similar shift. The competitive and strategic logic is straightforward — open-source models are training signal for competitors. Once a lab reaches frontier performance, the incentive structure changes.
For developers evaluating MiniMax as a vendor, this is relevant context: the model weights cannot be self-hosted, fine-tuned locally, or inspected for compliance purposes. If your deployment requirements include any of those, M2.7 is off the table regardless of its benchmark profile.
The Hidden Cost of “Cheap” AI — Why Verbosity Matters
Here’s the uncomfortable truth that M2.7’s advocates (and MiniMax’s own marketing) quietly sidestep: the per-token pricing is not the same thing as the per-task cost.
At $0.30/M input and $1.20/M output, M2.7 looks like a bargain relative to Claude Opus 4.6 or GPT-5. Apply the Effective Cost Per Task framework, and that calculation shifts substantially. Artificial Analysis measured M2.7 generating 87M output tokens during its Intelligence Index evaluation — 3.35 times the median for comparable models. At $1.20/M output, the cost differential between M2.7 and a model generating the median 26M tokens is roughly ($87M – $26M) × $1.20/1,000,000 = $73.20 more per evaluation run from verbosity alone. That’s before accounting for the higher input token consumption.
Kilo Bench corroborates this from a different angle. M2.7 averaged 2.8M input tokens per trial — the highest of any model tested, and significantly above what Kimi K2.5 or Qwen3.5-plus consumed on the same tasks. When the model reads more context to achieve better accuracy, it’s making a latency and cost tradeoff that may or may not be acceptable depending on your application.
The verbosity trap closes on teams that run quick API pricing comparisons, build a budget projection on per-token rates, and discover three months into production that their actual invoices are 2–3x the estimate. The fix is straightforward: run your actual task distribution through M2.7 for two weeks, measure real token consumption, and compute ECPT. Don’t let headline pricing be the deciding factor.
There’s also a latency dimension. At 45.7 tokens/second — less than half the peer-tier median of 109.7 t/s — M2.7’s response time compounds with its verbosity. Long outputs generated slowly create real user-experience problems in interactive applications. For background batch processing or asynchronous agent workflows, this matters less. For anything where a human is watching the cursor blink, it matters a lot.
Key Insight: M2.7’s “verbosity trap” — the gap between headline per-token pricing and real per-task cost — is the single most underreported risk in current M2.7 coverage. Model your actual task consumption before committing at scale.
How to Use MiniMax M2.7 via API (Getting Started)
MiniMax M2.7 is available through the MiniMax API directly and through at least two third-party providers, including Galaxy.ai, Kilo Code, and KiloClaw — per Artificial Analysis data as of April 2026. For teams already using the OpenClaw or Claude Code ecosystems, M2.7 can be dropped into existing pipelines with minimal configuration.
Access paths:
- MiniMax API directly — via the MiniMax Console. Register at minimax.io, generate an API key, and call the model using the standard REST endpoint. Documentation covers authentication, rate limits, and parameter configuration.
- Kilo Code / KiloClaw — available in Kilo’s IDE extension, CLI, and Cloud Agents since March 2026. KiloClaw provides a cloud-hosted, managed OpenClaw instance accessible from the Kilo dashboard in roughly 60 seconds of setup.
- Galaxy.ai — supports M2.7 alongside 210+ other models in a unified API interface, useful for teams A/B testing models across task types.
- MindStudio — no-code agent building environment with M2.7 integration, appropriate for teams that want to evaluate agentic behavior without infrastructure overhead.
Supported parameters: Tools, Top P, Response Format, Reasoning, Temperature, Include Reasoning, Tool Choice, Max Tokens.
Practical deployment guidance:
- Start with SWE-style coding tasks — bug tracing, multi-file refactoring, dependency analysis. These are where M2.7’s read-heavy profile generates return on its token consumption.
- Avoid real-time or interactive applications where M2.7’s 45.7 t/s output rate will create perceptible latency.
- Set explicit Max Tokens limits on production calls. Without a ceiling, M2.7’s verbosity will generate substantially more output than most tasks require — increasing both cost and latency.
- Monitor token consumption per task from day one. Build your ECPT calculation before scaling usage.
The 200K token context window is a genuine asset for large codebase analysis, long document processing, and multi-turn agent histories — but note that M2.7 tends to use its context aggressively, which is both its strength and its cost driver.
The Self-Evolution Inflection Point
MiniMax M2.7 is a strong model. But the more significant thing it represents is a structural shift in how frontier AI gets built.
The OpenClaw self-improvement loop isn’t just a clever training trick — it’s a working prototype of recursive model development, where the AI system contributes meaningfully to its own evolution without requiring the full weight of human-directed fine-tuning cycles at each step. Anthropic, OpenAI, and Google are all watching this. If a relatively smaller Shanghai lab can demonstrate a 30% performance improvement through 100 autonomous optimization rounds, the implication for labs running 10,000 rounds — with better hardware and larger base models — is not subtle.
The practical recommendation for April 2026: developer teams running agentic coding pipelines who need SWE-bench-level performance without Claude Opus 4.6 pricing should evaluate M2.7 seriously. Run your own task distribution. Measure real token consumption. Calculate ECPT before you scale. And if your requirements include multimodal input, sub-50ms response times, or open-weight model access, look elsewhere.
The real question isn’t whether M2.7 beats GPT-4 today — it clearly does, on almost every dimension that matters. The more interesting question is what a model that already participates in its own training becomes after 1,000 such cycles. That answer will define the next generation of AI infrastructure, and MiniMax just published the first chapter.
Sources & References
- Design for Online Model Ranking — designforonline.com/ai-models/minimax-minimax-m2-7 — methodology-based scoring (Intelligence 8.5/10, Technical 7.8/10, Content 8/10, Value 7.5/10) assessed April 4, 2026
- MiniMax Official Announcement — minimax.io/news/minimax-m27-en — primary documentation on M2.7 architecture, OpenClaw framework, and self-optimization results
- VentureBeat Coverage (March 2026) — venturebeat.com — independent analysis of M2.7’s self-evolving RL workflow and benchmark positioning
- Artificial Analysis Intelligence Index — artificialanalysis.ai/models/minimax-m2-7 — third-party intelligence scoring, speed metrics, pricing analysis, and token consumption data
- Kilo AI Benchmark Analysis — blog.kilo.ai/p/minimax-m27 — PinchBench and Kilo Bench independent evaluation with behavioral profile analysis
- MindStudio Technical Breakdown — mindstudio.ai/blog/what-is-minimax-m2-7-self-evolving-ai — plain-language analysis of recursive self-optimization mechanics
- WaveSpeed AI Comparative Analysis — wavespeed.ai/blog — comparative review of M2.7 vs Claude Opus 4.6, GPT-5, and Gemini