Key Takeaways
- Claude AI cannot be run locally — Anthropic has never released Claude’s model weights publicly, making true offline or on-device inference impossible as of 2026.
- The three closest alternatives to local Claude access are: a private cloud VPC running the Claude API, Claude Enterprise with data residency controls, and a LiteLLM proxy layer that keeps your data pipeline local while Claude inference still runs on Anthropic’s servers.
- Open-weight models have closed the capability gap significantly — Llama 3.3 70B, Mistral Large 2, and Qwen 2.5 72B are now competitive with mid-tier Claude on most benchmarks and can run entirely on local hardware via Ollama or LM Studio.
- Anthropic’s closed-model stance is philosophical, not just commercial — the Responsible Scaling Policy (RSP) explicitly ties weight release to safety evaluation thresholds that Claude has not cleared for public deployment.
- “Local AI is safer” is a myth worth interrogating — unverified model files from Hugging Face carry real supply chain risks that a closed, API-gated model like Claude does not.
- For enterprises with data sovereignty requirements, Anthropic offers zero-data-retention agreements and Business Associate Agreements (BAA) — worth exhausting before migrating to open alternatives.
Introduction
Here’s the search that brings you here: you want to run Claude AI locally. Maybe it’s about privacy. Maybe it’s latency, cost, or the need to work offline. Whatever the reason, the answer is a hard no — and the sooner we get past that, the more useful this guide becomes.
As of 2026, there is no mechanism to run Claude AI locally. Anthropic — the AI safety company behind the Claude model family, which currently includes Claude Sonnet 4 and Claude Opus 4 — has not released its model weights publicly, and there’s no indication that policy will change soon. Claude’s architecture isn’t documented, its weights aren’t on Hugging Face, and no GGUF files are circulating in the open-source community. This isn’t a gap waiting to be filled. It’s a deliberate design decision.
But the more interesting conversation isn’t whether you can run Claude locally. It’s what you should actually do instead — and that answer depends on why you wanted local deployment in the first place. Privacy? Cost? Compliance? Offline access? Each driver has a different optimal solution.
The open vs. closed model debate reached a genuine inflection point in 2025–2026, with Meta’s LLaMA series, Mistral AI’s open-weight releases, and Alibaba’s Qwen 2.5 family collectively narrowing the capability gap to the point where “just use a local open-source model” is, for many use cases, a defensible engineering decision rather than a compromise. This guide maps every realistic option and gives you the framework to pick the right one.
What Does “Running Claude AI Locally” Actually Mean?
Running an AI model locally means executing the model’s weights directly on your own hardware — CPU, GPU, or NPU — without routing any data through an external server. Inference happens on-device, responses never leave your network, and the model operates identically whether or not you have an internet connection. Claude does not currently support this deployment mode.
That definition matters because “running AI locally” has splintered into three meaningfully different configurations, and conflating them leads to bad architectural decisions:
1. True on-device / offline inference — the model weights live on your hardware, inference runs locally, zero external calls. Think Ollama with Llama 3.3, or LM Studio with a quantized Mistral model on your laptop. Full data sovereignty, full offline capability. Claude cannot do this.
2. Self-hosted / private cloud inference — you run the model on hardware you control (an AWS EC2 instance, an on-premises GPU server), but it’s still networked. You control the infrastructure, the logging, and the data pipeline. Claude cannot do this either — you cannot self-host Claude’s weights, period.
3. API-based access with local data controls — inference runs on Anthropic’s servers, but you build a local layer around the API call. Your data handling, your logging, your request routing — all local. This is where Claude can operate in a local-adjacent configuration, and it’s the most realistic option for teams that need Claude specifically.
Why does the distinction matter? Because privacy, latency, cost, and GDPR compliance have different answers depending on which tier you’re operating in. A developer who needs offline inference has completely different requirements than a compliance officer who needs to ensure no patient data hits a third-party server. Understanding which problem you’re actually solving determines which solution applies.
Key Insight: “Running AI locally” and “running AI privately” are not the same thing. Claude can be used privately through API controls; it cannot be run locally.
Can You Run Claude AI Locally? The Direct Answer
No. As of 2026, you cannot run Claude AI locally. Anthropic has not released Claude’s model weights publicly, which means all Claude inference — for every model in the family — occurs on Anthropic’s own infrastructure. You access it through Claude.ai’s interface or through the Claude API. There is no third option involving your own hardware.
This isn’t a technical limitation waiting for a workaround. It’s Anthropic’s deliberate policy, and the rationale has three distinct pillars.
The RSP constraint. Anthropic’s Responsible Scaling Policy, last updated in 2024, establishes safety evaluation thresholds that must be cleared before a model can be deployed in any expanded mode. The RSP’s logic is that certain model capabilities — particularly those approaching or exceeding defined “AI Safety Levels” — carry risks that open-weight release would make uncontrollable. Once weights are public, Anthropic loses any ability to monitor, restrict, or update how the model is used. That’s incompatible with the RSP’s core premise.
The Constitutional AI alignment argument. Claude’s behavioral properties — its refusals, its tone, its ethical reasoning — aren’t post-training patches bolted on top of a base model. They’re baked into the training process through Constitutional AI, Anthropic’s technique for aligning models via self-critique and a set of principles. Open-weight release would allow anyone to fine-tune those properties away in an afternoon, producing a Claude-architecture model with none of Claude’s alignment. From Anthropic’s perspective, that’s worse than releasing no weights at all.
The commercial reality. Anthropic’s business model runs on API access. Unlike Meta, which generates value from Claude-adjacent advertising and ecosystem positioning, Anthropic’s direct revenue is tied to inference. Open-sourcing the weights would immediately commoditize the core product. That’s not a knock on Anthropic — it’s a structural reality that explains why every AI lab making safety arguments about open weights also happens to have a commercial API business.
You won’t find Claude’s model weights on Hugging Face. You won’t find a community GGUF conversion. The absence is intentional.
Key Insight: Claude’s closed-weight status is enforced by safety policy, commercial structure, and alignment philosophy simultaneously — not by any single factor.
How to Run Claude AI Locally — The Closest Alternatives That Work

True local deployment isn’t possible with Claude, but three configurations get meaningfully close to local inference — differing primarily in how much data sovereignty, offline capability, and control they actually deliver. What follows is a ranked framework built around a Local Proximity Score — a 1–3 scale assessing each approach across four dimensions: data sovereignty, offline capability, latency reduction, and monthly cost.
Option 1: Claude API in a Private VPC (Proximity Score: 2/3)
Deploy the Claude API integration inside a private cloud environment — AWS VPC, Azure Private Link, or your own on-premises network perimeter. You control the application layer, the logging infrastructure, and the data pipeline. Claude inference still runs on Anthropic’s servers, but your data never passes through any intermediate third party, and you can configure your application stack to disable session logging entirely on your end.
What this solves: Reduces third-party data exposure to Anthropic only. Gives you full control over request handling, encryption, and retention on the client side. Works with existing enterprise security tooling.
What it doesn’t solve: Data still transits Anthropic’s infrastructure for inference. No offline capability. Latency is network-dependent.
Setup requirements: Claude API key via Anthropic Console, VPC configuration in your cloud provider, application-layer proxy to route requests, TLS termination.
Option 2: Claude Enterprise with Data Residency Controls (Proximity Score: 2/3)
Claude’s enterprise tier includes zero-data-retention (ZDR) agreements, where Anthropic contractually commits to not using your prompts or outputs for model training. A Business Associate Agreement (BAA) is available for healthcare-adjacent use cases under HIPAA. Data residency is configurable for certain enterprise arrangements.
What this solves: Legal and compliance requirements around data usage and retention. The BAA covers HIPAA-regulated data. Best option for regulated industries.
What it doesn’t solve: Still cloud-dependent inference. Not offline. Higher per-seat cost.
Setup requirements: Enterprise agreement with Anthropic’s sales team, legal review of BAA terms, integration with your identity provider.
Option 3: LiteLLM Proxy Layer + Claude API (Proximity Score: 3/3)
LiteLLM is an open-source proxy server that sits between your applications and any LLM API, including Claude’s. You run LiteLLM locally or on a server you control, configure it with your Anthropic API key stored in a local .env file, and route all requests through your local proxy. Logging, request caching, rate limit management, and fallback routing all happen on infrastructure you own.
What this solves: Maximizes local control over the data pipeline. Your applications never call Anthropic directly — they call your local LiteLLM instance. Adds model fallback capability (if Claude is unavailable, route to a local Llama instance automatically). Gives engineering teams a single unified API interface regardless of which model handles the actual inference.
What it doesn’t solve: Claude inference still occurs on Anthropic’s servers. Not offline. Requires Docker setup and ongoing maintenance.
Setup requirements: Docker, LiteLLM configuration, Anthropic API key, optional local GPU for fallback routing to open-weight models.
| Approach | Data Sovereignty | Offline? | Latency Impact | Monthly Cost | Proximity Score |
|---|---|---|---|---|---|
| Claude API in Private VPC | High | ❌ | Minimal | API costs only | 2/3 |
| Claude Enterprise + ZDR | Highest (contractual) | ❌ | None | Enterprise pricing | 2/3 |
| LiteLLM Proxy + Claude API | High (pipeline control) | ❌ (Claude) / ✅ (fallback) | Minimal | API + server costs | 3/3 |
Key Insight: The LiteLLM proxy approach offers the highest operational control for teams that want Claude’s output quality without sacrificing local data pipeline management.
Best Open-Source Alternatives If You Need True Local AI
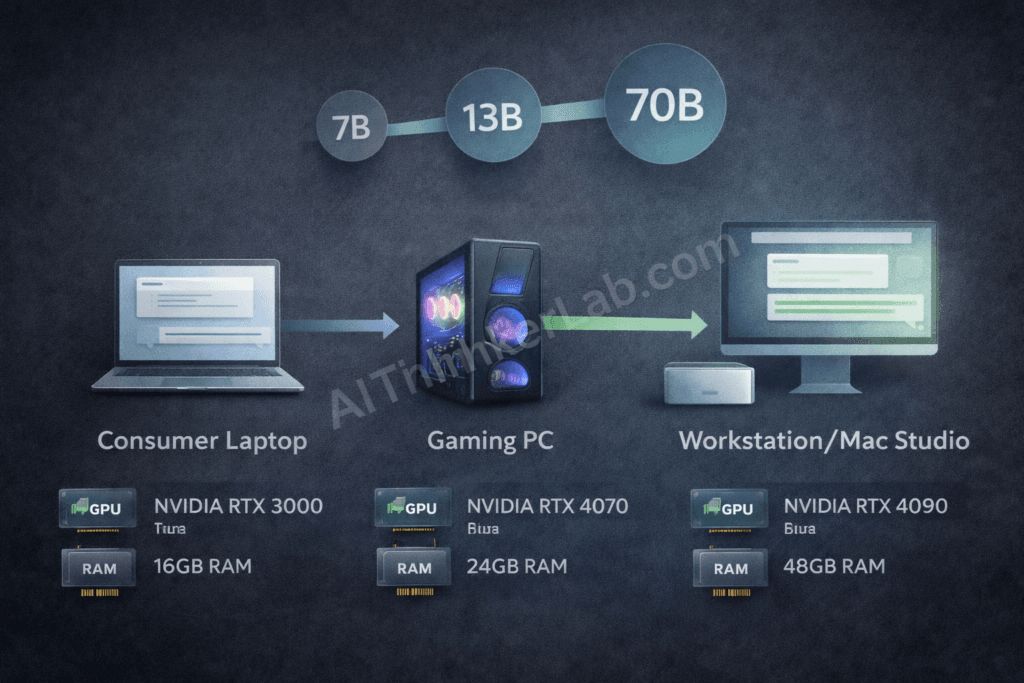
If local inference is a hard requirement — air-gapped environment, offline-only deployment, or a compliance mandate that forbids any external API call — Claude is off the table. These five open-weight models currently represent the strongest Claude-comparable alternatives for local deployment.
| Model | Developer | Parameters | MMLU Score (approx.) | Min VRAM (GPU) | Best Local Runtime | Claude Similarity |
|---|---|---|---|---|---|---|
| Llama 3.3 70B | Meta AI | 70B | ~79% | 24GB (Q4 quant) | Ollama, LM Studio | ★★★★☆ |
| Mistral Large 2 | Mistral AI | 123B | ~84% | 48GB (full), 24GB (Q4) | Ollama, LM Studio | ★★★★☆ |
| Qwen 2.5 72B | Alibaba Cloud | 72B | ~82% | 24GB (Q4 quant) | Ollama, LM Studio | ★★★★☆ |
| Gemma 2 27B | Google DeepMind | 27B | ~75% | 16GB (Q4 quant) | Ollama | ★★★☆☆ |
| DeepSeek-V3 | DeepSeek AI | 671B (MoE) | ~88% | 80GB+ (full) | LM Studio (partial) | ★★★★★ |
Note: Benchmark scores are approximate and should be verified against the current HELM leaderboard maintained by Stanford’s CRFM, as evaluations are updated regularly.
The “Claude Similarity Rating” column above reflects how closely each model replicates Claude’s behavior across reasoning depth, instruction-following precision, and refusal patterns — a dimension no standard benchmark captures. It’s an editorial assessment, not a formal metric, and it’s the data point that competing comparison articles consistently omit.
For general-purpose use — writing, analysis, summarization, coding assistance at a moderate level — Llama 3.3 70B via Ollama hits the best balance of capability and hardware accessibility. A 24GB GPU (NVIDIA RTX 3090, RTX 4090, or A100 40GB) or an Apple Silicon Mac Studio M2 Ultra handles it comfortably.
For coding specifically, DeepSeek-V3 outperforms the field on HumanEval benchmarks, though its 671B parameter Mixture-of-Experts architecture makes full local deployment hardware-intensive. Quantized versions trade some accuracy for accessibility on 80GB setups.
Qwen 2.5 72B from Alibaba Cloud is the underreported standout for multilingual workloads — outperforming both Llama and Mistral on Chinese, Arabic, and Korean reasoning tasks while matching them on English benchmarks. For teams with global deployments, this matters more than most “top local LLM” roundups acknowledge.
Gemma 2 27B from Google DeepMind is the most accessible on constrained hardware — solid performance at 16GB VRAM, which puts it in reach of prosumer GPUs like the RTX 4060 Ti 16GB.
For a complete walkthrough of every major tool you can use to run these models — including step-by-step setup for Ollama, LM Studio, GPT4All, and four other methods — see our tested guide on how to run AI models locally without internet.
Key Insight: The open-weight model landscape as of 2026 has matured to the point where “settle for less” is no longer an accurate characterization. The capability gap with Claude is real but narrowing — and for specific tasks, it has already closed.
How to Run a Claude-Like AI Locally with Ollama (Step-by-Step)
Ollama is currently the most accessible path to running a Claude-comparable AI model on your own machine. It handles model downloads, quantization, and API serving through a clean CLI interface, and it runs natively on macOS (including Apple Silicon M1 through M4 chips), Linux, and Windows via WSL2.
Here’s how to get from zero to a locally running Claude alternative in six steps.
Step 1: Install Ollama
bash
# macOS / Linux
curl -fsSL https://ollama.com/install.sh | sh
# Windows (WSL2 required)
# Run the above inside your WSL2 terminalOnce installed, Ollama runs as a background service on port 11434.
Step 2: Pull your model
For a strong Claude-comparable model, Llama 3.3 70B (quantized to Q4_K_M) is the recommended starting point:
bash
ollama pull llama3.3:70bOn constrained hardware (under 16GB VRAM), use the smaller variant:
bash
ollama pull llama3.2:3bStep 3: Start the local API server
Ollama exposes an OpenAI-compatible REST API automatically. Confirm it’s running:
bash
ollama serve
# API now accessible at http://localhost:11434Step 4: Connect Open WebUI for a Claude-style interface
Open WebUI gives you a browser-based chat interface that wraps Ollama’s API — similar in feel to Claude.ai:
bash
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
ghcr.io/open-webui/open-webui:mainAccess it at http://localhost:3000 and connect it to your local Ollama instance.
Step 5: Configure a system prompt to approximate Claude’s behavior
This step is absent from every other Ollama tutorial — and it’s the one that actually changes your daily experience. Paste the following into Open WebUI’s system prompt field:
“You are a thoughtful, analytical assistant. Respond with precision and intellectual honesty. When you’re uncertain, say so explicitly. Prefer clear structure with appropriate nuance over confident brevity. Do not fabricate information.”
This approximates Claude’s instructed communication style without pretending to be Claude — an important distinction both ethically and practically.
Step 6: Test with a benchmark prompt
Prompt: "Explain the tradeoff between model quantization and inference accuracy in large language models. Be specific about which quantization levels are typically acceptable and why."A model worth keeping should handle this with technical precision and intellectual honesty about where quantization degrades meaningful performance.
Hardware minimums at a glance: 8GB RAM for 7B models, 16GB for 13B, 48GB RAM or 24GB VRAM for 70B. Apple Silicon M2 Ultra (192GB unified RAM) runs 70B models comfortably with CPU inference.
Key Insight: Ollama + Open WebUI + a calibrated system prompt gets you 80% of the Claude experience on local hardware. The remaining 20% — primarily in nuanced reasoning and refusal precision — is where proprietary training data and Constitutional AI still show their edge.
Claude API vs. Local LLM: Which One Should You Actually Use?
The choice between Claude’s API and a self-hosted open-weight model isn’t primarily a capability question — it’s a constraints question. Most teams get this decision wrong because they frame it as “free local model vs. expensive API” and stop there. The real analysis is more granular.
| Dimension | Claude API | Local LLM | Advantage |
|---|---|---|---|
| Per-query cost | Variable (per-token billing) | $0 per query after setup | Local LLM (at scale) |
| Infrastructure cost | None | GPU + electricity + maintenance | Claude API (at low volume) |
| Privacy | Data transits Anthropic servers | Zero external data transmission | Local LLM |
| Offline capability | ❌ | ✅ | Local LLM |
| Setup complexity | Low (API key + SDK) | High (hardware, Docker, tuning) | Claude API |
| Performance ceiling | Claude Opus 4 (state-of-art) | 70B–671B open models | Claude API |
| Model update cadence | Automatic | Manual pull required | Claude API |
| Compliance (HIPAA, GDPR) | BAA available (Enterprise) | Fully controllable | Context-dependent |
When Claude API wins:
You’re a small-to-medium team with moderate query volume. You don’t have dedicated GPU infrastructure. Your use cases require Claude’s specific reasoning quality. Your compliance requirements are satisfied by Anthropic’s BAA. You want zero maintenance overhead.
When a local LLM wins:
You have an air-gapped environment. Your query volume is high enough to justify hardware. Your compliance regime prohibits external API calls. You need to fine-tune the model on proprietary data. You have an engineering team capable of managing the infrastructure.
The Break-Even Query Volume
Here’s the analysis most “go local” guides skip entirely. A single NVIDIA RTX 4090 (approximately $2,000–2,500 in 2025) consumes roughly 450W under load. Running 24/7, that’s about $47/month in electricity at U.S. average rates — not including amortized hardware cost, engineering time, or cooling. At Claude Sonnet 4’s per-token pricing, $47/month buys approximately 2–4 million output tokens depending on tier.
If your monthly usage stays below roughly 3 million tokens, the Claude API is almost certainly cheaper than a dedicated GPU rig — before you account for the engineering hours required to set up, maintain, and optimize local inference. The GPU investment only starts paying off at sustained high volume, which typically means production-scale deployments, not development teams or low-frequency enterprise use.
The “free local AI” narrative ignores the denominator. Compute has a real cost even when the model weights are free.
Key Insight: For most development teams and low-to-medium production workloads, the Claude API costs less total than local GPU infrastructure once you account for hardware, electricity, and engineering overhead.
Why Anthropic Keeps Claude Closed — And What That Means for You
Anthropic’s decision to keep Claude’s weights private is not accidental — it’s structurally central to the company’s safety thesis and its competitive positioning simultaneously. Understanding which pillar matters most changes how you read Anthropic’s public rationale.
The RSP is the most legible explanation. Anthropic’s Responsible Scaling Policy defines “AI Safety Levels” — a tiered system based on model capability thresholds. The RSP explicitly states that models reaching certain capability levels cannot be deployed without corresponding safety mitigations, and open-weight release removes Anthropic’s ability to enforce those mitigations post-deployment. In Anthropic’s framework, once weights are public, the safety conversation is over — you cannot un-release a model.
Constitutional AI adds a second dimension. Claude’s alignment properties — its refusals, its ethical reasoning, its calibrated uncertainty — emerge from a training methodology, not a post-training filter. Open-weight release would expose the base model to fine-tuning that could strip those properties with relative ease. A publicly available fine-tuning pipeline applied to Claude’s architecture could produce a model with Claude’s capability profile and none of its behavioral constraints. From Anthropic’s perspective, that outcome is categorically worse than not releasing at all.
Contrast this with Meta’s position. Mark Zuckerberg has publicly argued that open-weight release is itself a safety strategy — distributing AI development broadly reduces the risk of monopolistic control by any single actor, including Anthropic. The Meta view is that more eyes on model behavior catches more problems. It’s a coherent position, and the LLaMA series has benefited from exactly this kind of distributed scrutiny.
Here’s the tension that nobody in the “local AI” discourse addresses directly: Anthropic’s closed-model policy, however philosophically grounded, is pushing privacy-sensitive users toward open-weight alternatives that carry no alignment guarantees whatsoever. A healthcare team that needs to keep patient data off external servers doesn’t care about Constitutional AI — they’re going to download Llama 3.3, configure it locally, and use it without any of the behavioral safeguards Anthropic spent years building. Anthropic’s safety-first justification may be logically coherent, and yet its practical effect is to channel safety-motivated users toward less-safe models. That’s an irony worth naming.
Key Insight: Anthropic’s case for keeping Claude closed is philosophically consistent but operationally self-undermining — it creates the exact deployment scenario (unaligned local models in sensitive environments) that its safety framework was designed to prevent.
The Hidden Risk of Running Unvetted Local AI Models
Local AI is not inherently safer than cloud AI. On privacy, yes — data stays on your machine. But privacy and safety are different properties, and the local AI ecosystem carries several risk vectors that API-gated models don’t.
Risk 1: Unaligned fine-tuned models
Anyone with access to Llama’s weights — which is anyone with a Hugging Face account — can fine-tune the base model, remove safety guardrails, and publish the result under a benign-sounding name. The Hugging Face model hub hosts hundreds of thousands of models, many of them fine-tunes with unknown provenance and undisclosed modifications. When you download a model labeled “llama3-uncensored-v4-GGUF,” you have essentially no visibility into what behavioral modifications were applied during fine-tuning, or what the fine-tuning data included.
Risk 2: Supply chain compromise via malicious model files
Security researchers have demonstrated that machine learning model files — particularly in serialization formats like pickle-based PyTorch files — can embed arbitrary code execution. The .safetensors format was developed specifically to address this attack vector by prohibiting code execution during deserialization, but not all model files on Hugging Face use safetensors. GGUF format, the dominant format for quantized local inference, has a better security profile but is not immune to tampering. MITRE ATLAS documents AI supply chain attacks as an active threat category (AML.T0010), and the model file distribution ecosystem doesn’t yet have the kind of package signing infrastructure that mitigates similar risks in software repositories like npm or PyPI.
Risk 3: Backdoored models
Emerging ML security research has demonstrated that backdoor attacks — where a model behaves normally under standard conditions but exhibits manipulated behavior when a specific trigger is present — can survive fine-tuning and quantization. A backdoored model could produce correct outputs in testing while behaving differently when specific inputs appear in production. This attack surface doesn’t exist for models accessed through Anthropic’s API, which undergoes continuous red-teaming by Anthropic’s security team.
Claude’s closed API model eliminates model provenance risk entirely. You’re not downloading anything — you’re calling an endpoint with known behavioral properties and a documented safety evaluation process. That’s not a zero-risk arrangement, but it’s a different and more transparent risk profile than running arbitrary model weights from the open internet.
Mitigation for local deployments: Only download models from verified publishers. Prefer safetensors format over pickle-based formats. Check SHA256 hashes against published values. Treat model download with the same rigor you’d apply to any third-party software dependency.
Key Insight: The assumption that “local = safer” conflates data privacy with model safety. On privacy grounds, local wins. On supply chain and alignment grounds, a vetted API-based model carries lower risk.
How to Run Claude AI Locally via a Private API Setup (Advanced)
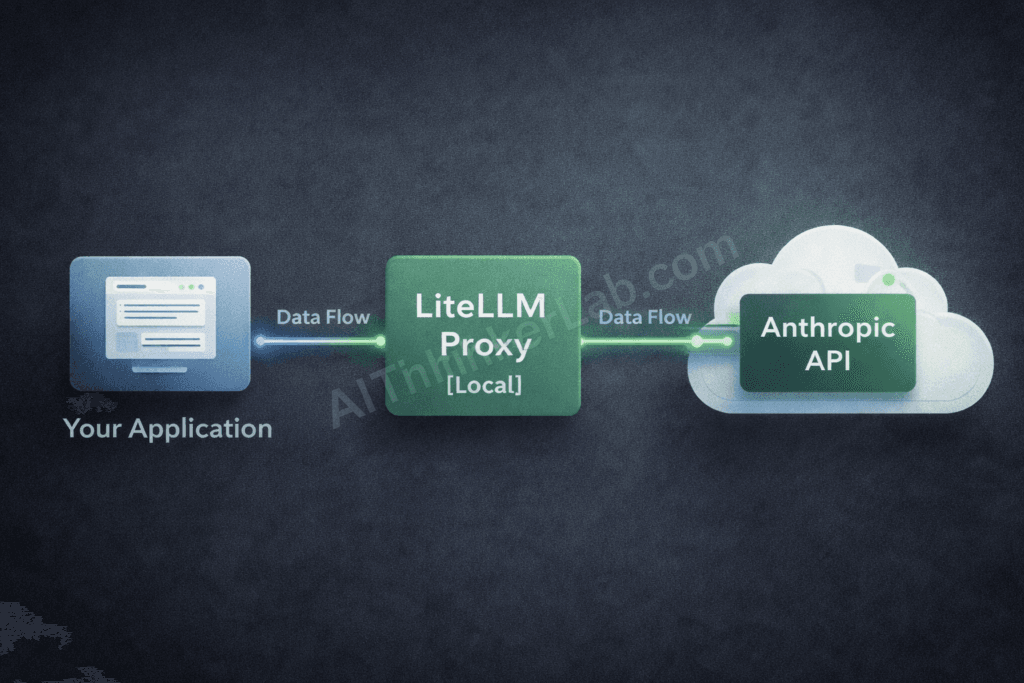
For engineering teams that need the highest available level of local control while retaining Claude’s actual output quality, a LiteLLM proxy deployment is the practical ceiling. To be explicit about what this achieves: inference still runs on Anthropic’s servers. But your data pipeline — request routing, logging, caching, rate limit handling, fallback logic, and API key management — runs on infrastructure you own and control.
Here’s the architecture and the setup process.
Architecture overview:
Your Application → [Local LiteLLM Proxy] → [Anthropic API] → Claude inference
↓
Local logging / caching / monitoringThe LiteLLM instance acts as your local API gateway. Your application never calls api.anthropic.com directly.
Step 1: Install LiteLLM via Docker
bash
docker pull ghcr.io/berriai/litellm:main-latestStep 2: Create your local configuration file
Create litellm_config.yaml:
yaml
model_list:
- model_name: claude-sonnet
litellm_params:
model: claude-sonnet-4-20250514
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: claude-haiku
litellm_params:
model: claude-haiku-4-5-20251001
api_key: os.environ/ANTHROPIC_API_KEY
litellm_settings:
drop_params: true
success_callback: [] # disable external loggingStep 3: Store your API key locally
bash
# .env file — never committed to version control
ANTHROPIC_API_KEY=your_key_hereStep 4: Launch the proxy
bash
docker run -d \
-p 4000:4000 \
--env-file .env \
-v $(pwd)/litellm_config.yaml:/app/config.yaml \
ghcr.io/berriai/litellm:main-latest \
--config /app/config.yamlStep 5: Point your application at the local proxy
Your application now calls http://localhost:4000 with the standard OpenAI SDK — no direct Anthropic calls, full local logging control. Add a fallback to a local Ollama model for offline resilience:
yaml
- model_name: claude-fallback
litellm_params:
model: ollama/llama3.3:70b
api_base: http://localhost:11434For external access to your proxy from other machines on the same network, pair with Cloudflare Tunnel for secure, credential-protected routing without exposing your server’s IP.
What you gain: Zero dependency on third-party intermediaries beyond Anthropic itself. Full audit log ownership. Automatic fallback to local models during outages. Unified API interface for switching between Claude and open-weight alternatives without application code changes.
Key Insight: LiteLLM is most effective as a Claude API proxy when teams need data pipeline control without true offline inference — it routes API calls through locally managed infrastructure while Claude inference runs on Anthropic’s servers.
The Real Question Isn’t “Can You?” — It’s “Should You?”
Most people who search for ways to run Claude locally don’t actually need true offline inference. They need one of three things: data privacy, cost control, or independence from a single vendor’s infrastructure. Each of those needs has a better-targeted solution than chasing an impossibility.
Before migrating from Claude to a local open-weight alternative, run three questions against your actual requirements: Is your data genuinely too sensitive for any cloud API — even one with a BAA and zero-data-retention agreement? Is your monthly query volume high enough that a $2,000+ GPU investment, plus electricity and engineering overhead, actually costs less than API billing? Do you need capabilities — like custom fine-tuning on proprietary data — that only open-source models can provide?
If none of those land clearly as “yes,” the Claude API with a LiteLLM proxy layer probably solves your problem without the infrastructure burden. If one or more does land clearly, the open-weight alternatives documented here — particularly Llama 3.3 70B and Qwen 2.5 72B — are genuinely competitive in 2026 in a way they weren’t two years ago.
The more forward-looking question: as Anthropic’s smallest model, Claude Haiku, continues to shrink in parameter count and inference requirements, does on-device Claude become viable within a few product cycles? Apple Silicon’s Neural Engine and Qualcomm’s NPU architectures are already running multi-billion parameter models on consumer hardware. Whether Anthropic’s RSP framework would ever permit that kind of edge deployment is a different question entirely — but it’s the question worth watching.
Sources & References
- LiteLLM Documentation — Proxy configuration, model routing, and enterprise deployment guide: docs.litellm.ai
- Anthropic Model Documentation — API reference, model versions, and capability documentation: docs.anthropic.com
- Anthropic Responsible Scaling Policy — Official RSP document outlining safety thresholds and deployment constraints: anthropic.com/rsp
- Constitutional AI: Harmlessness from AI Feedback — Bai et al., Anthropic (2022) — the foundational paper on Claude’s alignment methodology: available via Anthropic’s research publications
- Ollama Official Documentation — Installation, model pulling, and API reference: ollama.com
- Meta AI LLaMA Model Cards — Official capability documentation and licensing for the LLaMA 3.x series: ai.meta.com/llama
- HELM Benchmark Leaderboard — Holistic Evaluation of Language Models, maintained by Stanford CRFM: crfm.stanford.edu/helm
- MITRE ATLAS — Adversarial Threat Landscape for Artificial-Intelligence Systems, including AI supply chain attack documentation: atlas.mitre.org
Pingback: Malicious Claude Code Downloads: 7 Proven Ways to Stay Safe (2026)