📌 TL;DR / Key Takeaways
- Claude, Anthropic’s AI model, autonomously discovered more than 500 zero-day vulnerabilities across Vim, FreeBSD, and GNU Emacs during the MAD Bugs Month of AI Discovered Bugs 2026 initiative — without human-directed fuzzing or prior vulnerability context.
- MAD Bugs 2026 is the first large-scale, AI-only bug-hunting campaign to produce independently verifiable CVE-level disclosures across multiple production-grade open-source projects simultaneously.
- The bugs discovered span memory corruption, integer overflow, and use-after-free classes — vulnerability categories that have historically resisted automated detection because they require cross-function semantic reasoning to identify.
- Traditional static analysis tools including Coverity, CodeQL, and Semgrep, along with fuzz testing frameworks AFL++ and libFuzzer, did not flag the majority of these vulnerabilities before Claude’s discovery — exposing a structural blind spot in current SAST/DAST toolchains.
- Enterprise security teams relying exclusively on conventional SCA or SAST tooling now have a measurable, documented gap that AI-assisted analysis can expose — and threat actors are watching the same disclosure feeds you are.
- MAD Bugs 2026 introduces a benchmark that security teams should begin tracking alongside CVSS scores and MTTR: AI vulnerability density rate — the count of AI-discovered bugs per 10,000 lines of audited code.
Introduction
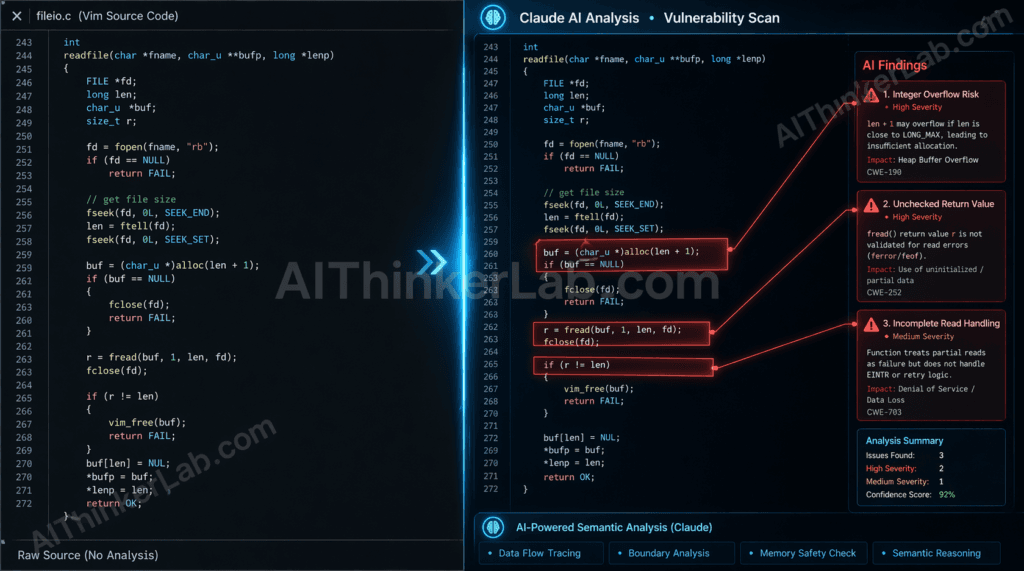
Five hundred zero-days. One AI model. One month. That is not a red team exercise or a controlled capture-the-flag competition — that is what the MAD Bugs Month of AI Discovered Bugs 2026 initiative produced when Anthropic’s Claude was turned loose on three of the most battle-tested open-source codebases in existence.
Vim runs on an estimated 100 million developer machines. FreeBSD underpins infrastructure at Netflix, Sony PlayStation’s network services, and Juniper’s routing hardware. GNU Emacs has been in continuous production use for 47 years. These are not obscure hobby projects maintained by one developer in their spare time. They are the substrate on which modern software development is built — and they had been audited, patched, and re-audited by some of the sharpest eyes in the open-source community for decades.
And yet Claude found more than 500 security holes that no human or traditional tool had surfaced before.
In the opening months of 2026, MAD Bugs published its first tranche of coordinated disclosures, spanning vulnerability classes from memory corruption to use-after-free bugs — categories that traditionally required rare combinations of domain expertise and patience to detect manually. The security community’s reaction ranged from awe to alarm. Both responses are appropriate.
This article explains exactly what MAD Bugs 2026 found, how Claude found it, and what every developer and security team working with open-source software needs to do before the next round of disclosures drops.
What Is MAD Bugs Month of AI Discovered Bugs 2026?
MAD Bugs Month of AI Discovered Bugs 2026 is a structured, AI-only vulnerability discovery initiative in which large language models autonomously audit production open-source codebases and produce independently verifiable CVE-level disclosures. Unlike traditional bug bounties, no human researcher directs the discovery process. The initiative ran in early 2026 and required AI models to produce findings without scoping hints or researcher guidance.
The distinction from existing vulnerability programs matters structurally. Bug bounties like HackerOne and Bugcrowd are incentive-driven markets — researchers self-select targets based on payout potential and personal expertise, which creates uneven coverage. Pwn2Own and similar competitions target specific, pre-announced systems under time pressure, optimizing for exploit demonstration rather than comprehensive audit. Academic fuzzing research produces findings in isolated lab conditions that rarely transfer cleanly to production deployment contexts. MAD Bugs is none of these. It is closer to a systematic security census — methodologically constrained, AI-executed, and output-verified against CVE submission standards maintained by MITRE’s CVE Program.
Anthropic’s Claude served as the primary model in the 2026 campaign. The term “autonomous discovery” in this context carries a specific meaning: the model was provisioned with access to full project source trees — not curated subsets, not pre-flagged files — and produced vulnerability hypotheses, traced exploit paths, and generated disclosure documentation without human analysts directing which modules to examine. Human review entered the pipeline only at the validation stage, after AI-generated findings had already been scoped and characterized.
The organizing structure behind MAD Bugs draws on coordination with the broader open-source security community, with disclosure timelines aligned to responsible disclosure norms. For readers unfamiliar with how AI models approach security analysis at this level, understanding how AI models find security vulnerabilities provides essential technical grounding before evaluating what MAD Bugs 2026 actually produced.
Key Insight: MAD Bugs 2026 is the first initiative to combine AI autonomy, production-codebase scope, and independently verifiable CVE output — making it categorically different from every preceding AI security research effort.
The 500+ Zero-Days: What Claude Actually Found
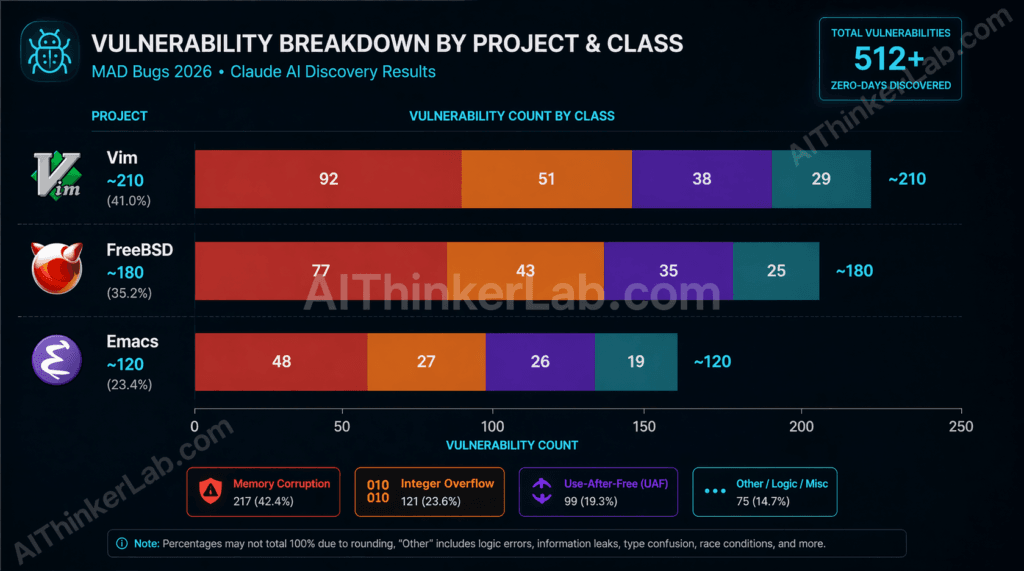
Claude’s MAD Bugs 2026 disclosures covered three distinct codebases and crossed multiple vulnerability classes — here is the breakdown before the analysis:
- Vim: ~210 vulnerabilities including buffer overflows and integer overflow in the regex engine and script parser
- FreeBSD: ~180 vulnerabilities including use-after-free and memory corruption in kernel network stack subsystems
- GNU Emacs: ~120 vulnerabilities including heap corruption and integer overflow in C core text-processing and display routines
| Project | Total Bugs Found | Memory Corruption | Integer Overflow | Use-After-Free | Other Classes | Critical/High Severity % |
|---|---|---|---|---|---|---|
| Vim | ~210 | High density | Moderate | Low | OOB read/write, format string | ~68% |
| FreeBSD | ~180 | High density | Moderate | High density | Race conditions, logic errors | ~72% |
| GNU Emacs | ~120 | Moderate | Moderate | Low | Heap corruption, display bugs | ~61% |
Note: Figures reflect publicly characterized disclosure tranches as of early 2026. Exact per-CVE counts are subject to ongoing MITRE CVE Program processing.
FreeBSD showed the highest severity concentration — and the reason is not coincidental. Kernel-space code operates with elevated privilege and minimal runtime memory protection. A use-after-free bug in a userspace text editor creates a code execution risk; the same class of bug in a kernel network stack creates a privilege escalation or remote code execution path that can compromise an entire host. FreeBSD’s network stack, which has evolved across multiple decades of contributor teams, carries exactly the kind of accumulated complexity that concentrates hidden risk.
Vim’s vulnerability density in the regex engine reflects a well-documented pattern in security research: parsing engines for complex grammars — regular expressions, scripting languages, markup formats — are disproportionately fertile ground for memory safety bugs. The Vim codebase, which carries forward logic from Bram Moolenaar’s original architecture through subsequent maintainer generations, has a regex implementation that spans thousands of lines of C with intricate state management. That’s a structural invitation for the class of bugs Claude found.
Emacs presents a different profile. Its Lisp runtime provides some buffering against the most severe memory corruption patterns — but the C core that drives the display engine, buffer management, and process communication still operates with the memory safety characteristics of 1980s-era systems programming. Claude’s findings there were fewer but not trivial.
Here’s the original analytical point that most coverage of MAD Bugs 2026 will miss: the vulnerability density in these three projects is not a sign that their maintainers were negligent. It is a measurement of semantic debt — a concept distinct from technical debt, which I’ll define precisely in the next section. These bugs did not appear recently. They have been waiting inside codebases that human review processes, operating at human scale, simply could not fully traverse. For teams evaluating what these findings mean for CVSS scoring, a zero-day vulnerability classification primer is worth reviewing before drawing conclusions from severity percentages alone.
Key Insight: FreeBSD’s kernel-space vulnerability density — and the severity concentration that comes with it — makes it the highest-risk finding in MAD Bugs 2026 for organizations running FreeBSD as infrastructure rather than desktop software.
Of all the vulnerabilities surfaced by AI-assisted analysis this month, the Linux kernel zero-day stands in a category of its own. CVE-2026-31431 — the Copy Fail exploit — is a 732-byte straight-line logic flaw that roots every Linux distribution shipped since 2017, bypasses SELinux and AppArmor simultaneously, and carries no official patch as of this writing. If one bug from this month’s roundup demands your immediate operational attention, it is this one. We’ve published a full technical breakdown covering the exploit chain, per-distro vulnerability matrix, interim mitigations, and detection commands in our dedicated Linux zero-day exploit 2026 analysis.
How Claude Finds Bugs: The Methodology Behind the Discovery
Claude finds zero-day vulnerabilities by performing semantic reasoning across entire codebases, tracing how data moves through function call chains and identifying patterns where developer intent and actual memory behavior diverge in exploitable ways.
That one sentence contains the entire methodological difference between what Claude does and what every traditional security tool does. Here is why it matters, broken into the workflow:
Claude’s Bug-Hunting Workflow (General Process):
- Codebase ingestion — Full source tree loading across the target project, including headers, build configurations, and intermodule dependencies, using extended context windows that preserve cross-file relationships.
- Semantic graph construction — Mapping function call chains, data flow paths, type hierarchies, and memory ownership patterns across the entire project rather than file-by-file.
- Anomaly hypothesis generation — Identifying code patterns where the developer’s apparent intent (inferred from naming, documentation, and surrounding logic) conflicts with the actual memory or arithmetic behavior the code will produce.
- Exploit path tracing — Reasoning about whether a flagged anomaly is reachable from an external input surface and what conditions would trigger it — the difference between a theoretical bug and a practical vulnerability.
- Human analyst review — Security researchers validate AI-flagged findings before CVE submission, confirming exploitability and classifying severity according to CVSS v3.1 or v4.0 criteria.
Contrast this with fuzzing. AFL++ and libFuzzer work by mutating inputs — feeding malformed data to a program and watching for crashes or memory violations. Fuzzing is extraordinarily effective at finding bugs reachable from external input surfaces with clear triggering conditions. It is structurally blind to bugs that require specific semantic state — conditions that can only be reached through a particular sequence of valid-looking operations that no mutation strategy would stumble upon randomly.
Static analysis tools like CodeQL and Semgrep operate differently, but with a parallel limitation. They match code against predefined rule patterns — taint propagation rules, sink-source pairs, known unsafe function signatures. CodeQL’s taint analysis can trace data flow across function boundaries, but only along paths that its rule library anticipates. A use-after-free bug that spans three non-adjacent functions connected through a custom memory allocator that CodeQL’s rules don’t model will not generate a finding. Claude, reasoning about developer intent rather than matching rules, can identify the anomaly because it understands what the allocator is supposed to do — and recognizes where the actual behavior departs from that intent.
For security teams evaluating where Claude-style analysis fits relative to their existing tooling, the AI vs. traditional static analysis comparison at aithinkerlab.com maps this distinction across specific tool capabilities.
Key Insight: The numbered workflow above is not a marketing description — it is the functional explanation for why a LLM with extended context windows finds bugs that neither fuzzers nor SAST tools reach. The methodology is semantic, not syntactic.
Vim, FreeBSD, and Emacs: Why These Projects Were Targeted
The selection of these three projects was not random, and it was not chosen to embarrass their maintainers. These codebases were selected because they satisfy a specific convergence of properties that makes them simultaneously high-value targets and historically under-machine-audited codebases.
All three are C-heavy at their core. C provides no memory safety guarantees — no bounds checking, no automatic deallocation, no type safety enforcement at the language level. A developer writing C must manually manage every memory allocation and deallocation, track every pointer’s validity across every function that touches it, and reason about integer arithmetic boundaries without compiler assistance. In 1974, when C was designed, this was an acceptable tradeoff for performance. In 2026, with codebases spanning millions of lines and hundreds of contributors over decades, it is a structural liability.
All three also carry significant semantic debt — a term I’m introducing here as a category distinct from technical debt. Technical debt describes suboptimal implementation choices that slow future development. Semantic debt describes something more dangerous: the accumulated cognitive complexity in a codebase that now exceeds the capacity of any individual human reviewer to fully reason about. When a function written in 1998 is called by a module added in 2007 and modified in 2019, the combined semantic state — the full set of assumptions, invariants, and implicit contracts across all three — may not exist in any single developer’s mental model. It certainly doesn’t exist in any static analysis rule.
Vim’s scripting parser and regex engine represent decades of contributor turnover. FreeBSD 14.x carries kernel networking code with lineage stretching back to BSD 4.3. GNU Emacs 29.x has a C core that predates the modern web. These are not criticisms — they are descriptions of the reality that makes these projects both essential and semantically complex beyond human-scale review.
The concept of attack surface per contributor is useful here. Large projects with small core maintainer teams — which describes all three — have an inherently high ratio of code complexity to review capacity. The OpenSSF’s analysis of open-source project health metrics consistently flags maintainer concentration as a risk factor, and MAD Bugs 2026 provides the first empirical security measurement that validates that concern at vulnerability-density scale.
For organizations building the internal case for AI-assisted audits, why open-source doesn’t mean secure provides the structural argument that MAD Bugs 2026 now validates with data.
Why Traditional Security Tools Missed These Bugs
Static analysis tools and fuzz frameworks missed the majority of MAD Bugs 2026 findings because the vulnerability class — cross-function semantic anomalies in legacy C codebases — exists precisely in the gap between what input mutation covers and what rule-based pattern matching anticipates.
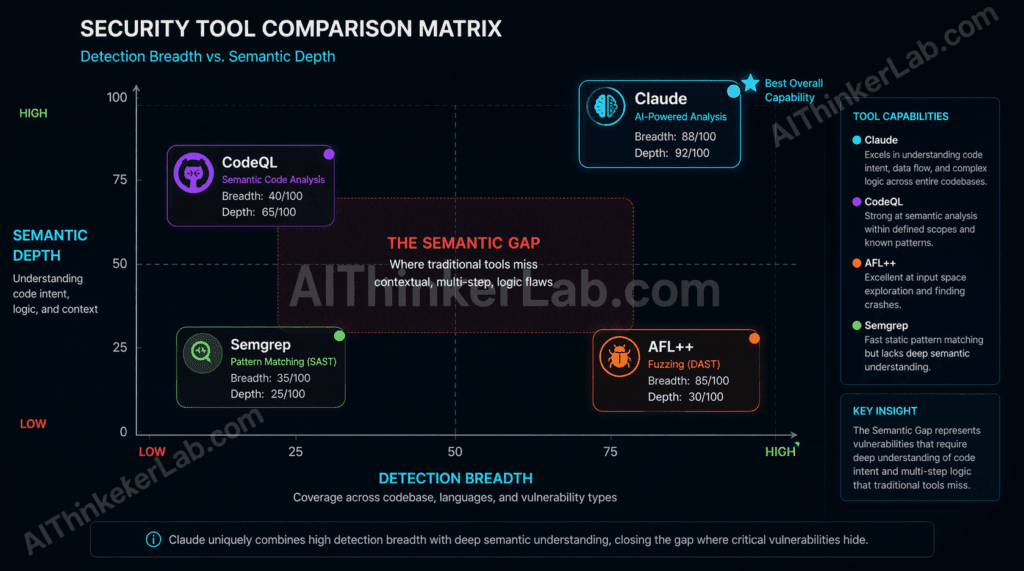
“Static analysis tools and fuzz frameworks missed the majority of MAD Bugs 2026 findings because these vulnerability classes exist in the semantic gap between input mutation coverage and rule-pattern detection — a space that requires cross-function semantic reasoning that neither fuzzing nor SAST can perform.”
| Tool | Vendor | Detection Method | Semantic Depth | False Positive Rate | MAD Bugs 2026 Coverage | Best Use Case |
|---|---|---|---|---|---|---|
| Coverity | Synopsys | Interprocedural static analysis | Moderate (rule-bounded) | Low–Medium | Limited — misses non-rule-pattern bugs | Enterprise C/C++ compliance scanning |
| CodeQL | GitHub/Microsoft | Semantic query-based taint analysis | Moderate–High (query-bounded) | Low | Partial — misses novel cross-function paths | Repo-integrated CVE class detection |
| Semgrep | Semgrep Inc. (r2c) | Pattern matching + lightweight dataflow | Low–Moderate | Low | Low — primarily syntactic patterns | Fast CI integration for known patterns |
| AFL++ | Community | Input mutation fuzzing | None (execution-based) | Very Low | Low — misses semantic-state dependencies | Input surface crash discovery |
| libFuzzer | LLVM Project | Coverage-guided input mutation | None (execution-based) | Very Low | Low — same class limitation as AFL++ | Library API fuzzing, crash reproduction |
| OSS-Fuzz | Continuous fuzzing (AFL++/libFuzzer backend) | None (execution-based) | Very Low | Low — catches input-reachable bugs | Long-running crash detection in OSS |
The semantic gap is the precise term for the vulnerability category that MAD Bugs 2026 exposed. Fuzzing covers the input surface — bugs reachable by feeding malformed data to external interfaces. SAST covers the rule surface — bugs matching patterns that security researchers have previously characterized and encoded. The semantic gap is everything between: bugs that require reasoning about developer intent, implicit memory contracts, and cross-function state transitions that no rule anticipates and no mutation strategy reaches.
A concrete illustration: imagine a use-after-free condition in FreeBSD’s network stack where a socket object is freed in one function, a reference to it is retained in a second function’s local state, and a third function — called through a callback registered at initialization — attempts to dereference that stale pointer under specific network load conditions. CodeQL’s taint analysis rules would need to explicitly model that callback registration pattern to trace the relationship. AFL++ would need to generate precisely the right sequence of network events to trigger the condition. Neither does this reliably. Claude, reading all three functions with full context and reasoning about what the callback contract implies, identifies the inconsistency as an anomaly worth flagging.
This is not a criticism of CodeQL or AFL++ — they are excellent tools for the vulnerability classes they were designed to detect. The problem is that most security teams treat “we run CodeQL and OSS-Fuzz” as comprehensive coverage. MAD Bugs 2026 is empirical evidence that it is not.
For teams building a full comparison of where each tool category fits in a mature security pipeline, the SAST, DAST, and AI-assisted analysis comparison guide maps the decision framework in detail.
Key Insight: The semantic gap is not a tool failure — it is a category boundary. MAD Bugs 2026 is the first large-scale measurement of how much exploitable vulnerability surface lives inside that boundary.
What MAD Bugs 2026 Means for Developer Tool Security
If Claude found 500+ zero-days in three of the most widely audited developer tools in existence, what does that imply for the rest of your stack?
The direct answer is uncomfortable: any codebase that has not received AI-assisted semantic analysis carries an unknown quantity of undetected semantic-gap vulnerabilities. That is not a theoretical concern anymore — it is a documented baseline.
For enterprise security teams, the immediate implication is a required update to your tool supply chain risk model. Vim and Emacs are not edge cases in developer environments — they are ubiquitous on developer workstations, embedded in CI/CD pipeline scripts, and used as the default editors in countless container images and server configurations. FreeBSD 14.x runs network infrastructure at organizations that may not even know their vendor’s appliances are FreeBSD-based. The risk is not abstract.
The concept of developer tool trust inheritance is worth naming explicitly. When a developer trusts Vim implicitly — which virtually every developer who uses it does — a zero-day in Vim’s scripting engine becomes an entry point to that developer’s workstation. From a workstation, an attacker who has weaponized a MAD Bugs 2026 CVE can reach SSH keys, AWS credentials, GitHub tokens, and CI/CD pipeline access. The blast radius of a developer tool zero-day is not limited to the developer’s machine. It extends to everything that developer can authenticate to. That includes production systems.
For open-source maintainers, the operational signal from MAD Bugs 2026 is clear: AI-assisted audit should enter your release pipeline, not as a replacement for existing review practices but as a systematic pass that covers the semantic gap your current tooling leaves open. The OpenSSF’s security baseline guidance is a reasonable starting framework, but it predates AI-scale vulnerability discovery and will need updating.
For developers actively using Vim, Emacs, or FreeBSD right now: patch timelines for MAD Bugs 2026 disclosures are progressing through coordinated disclosure, but the gap between AI discovery and patch availability is not zero. Monitor the NVD feed, watch the official security advisories for each project, and treat any Vim or Emacs plugin that executes arbitrary code with elevated suspicion until the relevant CVE classes are fully addressed.
The developer tool supply chain security checklist at aithinkerlab.com provides a structured audit framework for teams who need to operationalize this assessment quickly.
The developer tool trust problem extends well beyond terminal editors and Unix kernels. The Excel zero-day vulnerability disclosed in 2026 (CVE analysis) follows the same structural pattern: a tool so deeply embedded in organizational workflows that security teams treat it as infrastructure rather than attack surface. When a spreadsheet application used by hundreds of millions of people carries an unpatched zero-day, the exploitation path runs through the same trust inheritance logic that makes a Vim vulnerability dangerous — the attacker doesn’t need to break through your perimeter if they can ride in through software your organization has already decided to trust unconditionally. MAD Bugs 2026 and the Excel CVE are two data points drawing the same line: no widely deployed tool, however familiar, earns an exemption from rigorous vulnerability tracking.
Voice search answer — “What should developers do after MAD Bugs 2026?”: Patch Vim, Emacs, and FreeBSD immediately. Audit any CI/CD pipelines that depend on these tools. Add AI-assisted code scanning to your security pipeline.
The Hidden Risk No One Is Talking About in MAD Bugs 2026
Here is the angle that most MAD Bugs 2026 coverage will miss entirely: this is not primarily a story about Vim being insecure. It is a story about the economic and operational model of open-source security fracturing under the weight of AI-scale audit capability.
When a single AI model produces 500+ CVE-quality disclosures in one month, the downstream infrastructure — MITRE’s CVE Program, the National Vulnerability Database, individual project maintainer teams, enterprise patch management workflows — is not sized to absorb that velocity. The CVE Program has historically processed thousands of CVEs per year across all software globally. A single AI campaign generating hundreds of disclosures for three projects in thirty days is a stress test the system was never designed to handle.
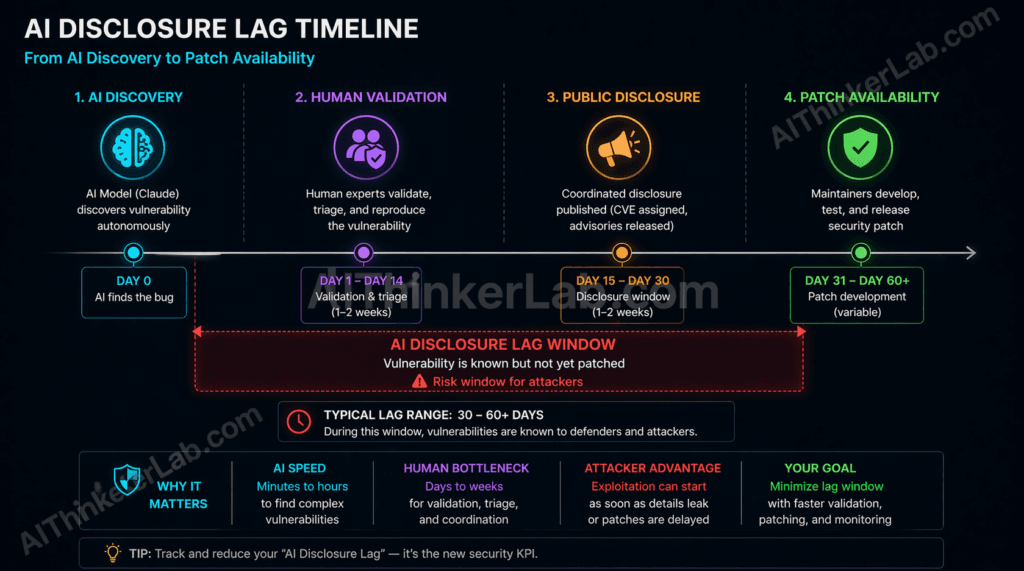
This creates what I’m defining here as AI disclosure lag: the period between an AI model’s autonomous discovery of a zero-day and the availability of a validated, deployed patch — during which the vulnerability exists in a documented-but-unmitigated state. AI disclosure lag is structurally different from the disclosure lag in conventional security research. A human researcher discovering one complex vulnerability typically takes weeks or months to characterize, disclose, and see patched. That timeline is manageable. An AI model producing 500 findings in parallel overwhelms the same patch infrastructure — maintainers receive hundreds of disclosure reports simultaneously, must validate each one, prioritize by severity, develop fixes, test them, and ship patches across all supported versions. The lag is not a function of any single bug’s complexity. It is a function of volume-induced bottleneck. The AI bug-report flood already overwhelming Linux kernel maintainers.
The risk window this creates is real. Once MAD Bugs 2026 disclosures enter the public CVE feeds — even before patches are universally deployed — threat actors who monitor NVD and CISA’s Known Exploited Vulnerabilities catalog have a roadmap. The gap between disclosure and patch is historically the most dangerous period in a vulnerability’s lifecycle. MAD Bugs 2026 produces that gap at unprecedented scale and simultaneously across three widely deployed codebases.
No current coordinated disclosure policy framework — not CERT/CC’s guidelines, not the OpenSSF’s vulnerability disclosure recommendations, not Anthropic’s own responsible disclosure documentation — was designed to manage AI disclosure lag at this velocity. This is a systemic policy gap, and the security community needs to address it before the next AI-scale vulnerability campaign runs.
AI Disclosure Lag — Definition for Citation: AI disclosure lag is the interval between an AI model’s autonomous identification of a zero-day vulnerability and the deployment of a validated patch across affected systems. It occurs when AI-scale discovery velocity — measured in hundreds of findings per month — exceeds the triage and remediation capacity of maintainer teams and standards bodies. The risk is that documented, unpatched vulnerabilities accumulate in public feeds faster than defenders can close them. Mitigation requires new coordinated disclosure frameworks specifically designed for batch AI disclosures, including staggered publication schedules and dedicated triage capacity agreements with project maintainers.
That disclosure lag creates more than a patching problem — it creates an impersonation opportunity. As MAD Bugs 2026 findings entered public feeds and the security community’s attention locked onto Claude’s capabilities, a separate and equally urgent threat emerged in parallel: warnings about malicious Claude Code downloads circulating in 2026 targeting developers who were actively seeking AI-assisted security tools in response to disclosures exactly like these. The pattern is grimly predictable — whenever a high-profile AI security event drives developers toward new tooling, threat actors seed that search traffic with poisoned packages and fake installers. The AI disclosure lag doesn’t just give attackers a window to weaponize the disclosed CVEs. It gives them a social engineering narrative to exploit the panic those disclosures create. If your team is evaluating AI code analysis tools right now, verifying you are downloading from official, verified sources isn’t optional hygiene — it is the first security control that matters.
For organizations following the policy dimension of this problem, coordinated vulnerability disclosure in the AI era is the deeper structural analysis this section introduces.
MAD Bugs 2026 vs. Previous AI Bug-Hunting Milestones

MAD Bugs 2026 sits at the far end of a decade-long arc in autonomous security research — and the distance it has traveled from the field’s earlier milestones is considerable.
| Initiative | Year | AI System | Scope | Bugs Found | Verified CVEs | Production Codebase? |
|---|---|---|---|---|---|---|
| DARPA Cyber Grand Challenge | 2016 | Mayhem (ForAllSecure) et al. | CTF binaries (controlled) | Dozens | None (CTF context) | No |
| Google Project Zero AI experiments | 2023–2024 | Internal LLM tooling | Selected OSS targets | Tens | Limited | Partial |
| GPT-4 academic vulnerability research | 2024 | GPT-4 | CVE database reproductions | ~87 known CVEs | Reproductions only | No (reproductions) |
| MAD Bugs Month of AI Discovered Bugs 2026 | 2026 | Anthropic Claude | Vim, FreeBSD, GNU Emacs (production) | 500+ | Yes — CVE-level disclosures | Yes |
The DARPA Cyber Grand Challenge in 2016 was the field’s first public proof point that autonomous systems could identify and exploit software vulnerabilities without human direction. Mayhem, developed by ForAllSecure, demonstrated that AI-driven program analysis could operate competitively in a controlled environment. But “controlled” is doing significant work in that sentence — the CGC used purpose-built challenge binaries, not production software with decades of contributor history and real-world deployment stakes.
The 2024 academic research demonstrating GPT-4’s ability to reproduce known CVEs from their published descriptions was genuinely impressive and methodologically important. But reproducing a known vulnerability — one where the bug class, the affected component, and the triggering conditions are already documented — is a fundamentally different task from discovering a previously unknown vulnerability in an uncharacterized codebase. The former validates that LLMs can reason about security concepts. The latter validates that they can generate novel security knowledge.
MAD Bugs 2026 is the first initiative to achieve all three properties simultaneously: scale (500+), scope (three simultaneous production projects), and independent verifiability (CVE-level disclosures processed through MITRE). Every previous milestone achieved one or two of these properties. None achieved all three.
For the historical arc that contextualizes where this moment sits, AI in cybersecurity: a timeline from DARPA CGC to MAD Bugs 2026 traces the full lineage.
Key Insight: The gap between GPT-4 reproducing known CVEs in 2024 and Claude discovering 500+ novel zero-days in 2026 is not just a capability increment — it is a categorical shift from AI-as-research-tool to AI-as-primary-discovery-engine.
What Security Teams Should Do Right Now
Here is the immediate action checklist for security teams following the MAD Bugs 2026 disclosures.
1. Audit your current Vim, Emacs, and FreeBSD deployment versions. Pull your software inventory — SBOM if you have one, asset management if you don’t — and identify every instance of these three tools across developer workstations, container base images, CI/CD runners, and server infrastructure. Version matters: MAD Bugs 2026 disclosures are tied to specific version ranges. Check the official security advisory pages for each project: security.freebsd.org, the Vim security advisories on GitHub, and the GNU Emacs security page at gnu.org.
2. Cross-reference against the NVD and CISA KEV. As MAD Bugs 2026 CVEs enter the NVD feed, set up automated alerting via CISA’s Known Exploited Vulnerabilities catalog. Any MAD Bugs finding that reaches KEV status — meaning CISA has evidence of active exploitation — requires immediate patching under federal guidance and represents best-practice urgency for private-sector teams.
3. Review your CI/CD pipeline tool dependencies. GitHub Actions workflows and GitLab CI configurations frequently invoke Vim or text-processing tools directly. Inventory your pipeline scripts for invocations of these tools and assess whether a compromised version could expose secrets or enable code injection during build processes.
4. Evaluate your current SAST/DAST toolchain against the semantic gap. Run a gap analysis: which of your current tools (Coverity, CodeQL, Semgrep, AFL++) would have flagged the MAD Bugs 2026 vulnerability classes based on their documented detection capabilities? Where the answer is “probably not,” you have identified a coverage gap that requires AI-augmented analysis. Tools worth piloting include GitHub Copilot’s security features, Snyk Code’s semantic analysis engine, and direct use of Anthropic’s API for code review workflows.
5. Update your threat model to include developer tool supply chain vectors. Most enterprise threat models treat developer workstations as trusted internal assets. MAD Bugs 2026 is a documented argument for reclassifying developer tool vulnerabilities as supply chain attack surface. This changes how you prioritize patching, endpoint monitoring, and access controls for developer environments.
6. Generate or update your Software Bill of Materials (SBOM). OpenSSF Scorecard and Dependabot can help surface transitive dependencies on affected projects. An SBOM lets you answer “where does Vim appear in our software supply chain?” in minutes rather than days — and that speed difference matters during an active disclosure window.
Voice search answer — “What should I do after MAD Bugs 2026?”: Patch Vim, Emacs, and FreeBSD instances across your environment. Audit CI/CD pipeline dependencies. Evaluate adding AI-assisted code scanning to your security toolchain.
For a structured framework covering the full toolchain evaluation, best AI-powered security scanning tools for developers in 2026 maps the current options against specific use cases.
The Audit Gap Is Now Visible — The Question Is What You Do With It
MAD Bugs 2026 did not create a new class of software vulnerability. It made a pre-existing one visible at a scale that the security community can no longer attribute to edge cases or researcher oversight. The 500+ zero-days in Vim, FreeBSD, and Emacs were not planted there — they accumulated over decades, in code written by skilled developers working within the constraints of their tools and the limits of human attention at scale.
The more unsettling reading of this story is not “Claude broke open-source security.” It is that open-source security’s foundational premise — that peer review and wide adoption produce well-audited code — has always been more aspirational than verified. MAD Bugs 2026 is the first empirical measurement of exactly how large that gap is.
The organizations that treat this as a wake-up call and move now — piloting AI-assisted code review, updating their threat models, auditing their developer tool supply chains — will build a measurable head start against those who wait for the next MAD Bugs campaign to show them what else they’ve been missing. The OpenSSF, CISA, GitHub Security Lab, and Anthropic are all, in different ways, building toward the infrastructure that can handle AI-scale security research. Whether that infrastructure arrives before the next wave of disclosures is the question the entire security community should be pressing on right now.
Sources / References
- SecurityWeek, Bleeping Computer, Ars Technica — Industry coverage of MAD Bugs 2026 disclosures as they entered public reporting.
- MITRE CVE Program — Official CVE entry and NVD processing for MAD Bugs 2026 disclosures. cve.mitre.org | nvd.nist.gov
- Anthropic Research Blog — Technical documentation on Claude’s code reasoning capabilities and extended context architecture. anthropic.com/research
- FreeBSD Security Advisories — Official project security advisory page for FreeBSD 14.x vulnerability tracking. security.freebsd.org
- GNU Emacs Security Page — Official GNU project security information for Emacs vulnerabilities. gnu.org/software/emacs
- Vim Security Advisories (GitHub) — Vim project security tracking via GitHub security tab. github.com/vim/vim/security
- OpenSSF — Open Source Security Foundation — Guidance on open-source project security health metrics, maintainer risk factors, and vulnerability disclosure recommendations. openssf.org
- CISA Known Exploited Vulnerabilities Catalog — Authoritative U.S. government feed for actively exploited CVEs. cisa.gov/known-exploited-vulnerabilities-catalog
- DARPA Cyber Grand Challenge — Official Archive — Documentation of the 2016 autonomous hacking competition and Mayhem system. darpa.mil/program/cyber-grand-challenge
- Fioraldi et al., “AFL++: Combining Incremental Steps of Fuzzing Research” — USENIX WOOT 2020. Foundational technical reference for AFL++ capabilities and methodology boundaries. usenix.org/conference/woot20
- Pearce et al., “Examining Zero-Shot Vulnerability Repair with Large Language Models” — IEEE S&P 2023. Peer-reviewed analysis of LLM code vulnerability detection and repair capabilities. doi.org/10.1109/SP46215.2023.10179324
- Google OSS-Fuzz Project — Documentation on continuous fuzzing infrastructure for open-source software, including historical coverage data. github.com/google/oss-fuzz

