TL;DR
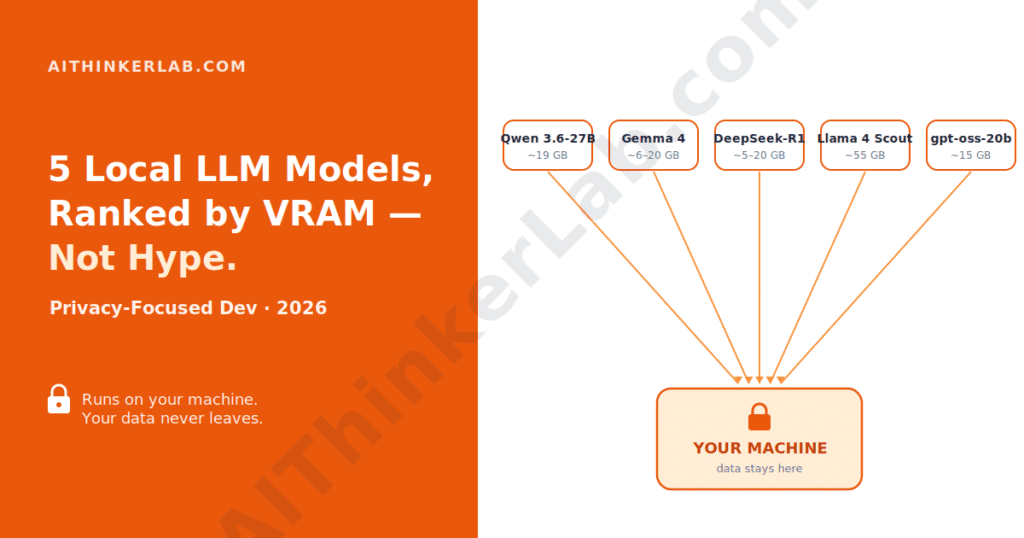
- For most private dev work on a single 24 GB GPU, Qwen 3.6-27B (Apache 2.0, released 22 April 2026) is the default pick — it posts 77.2% on SWE-bench Verified and beats Alibaba’s own 397B flagship on coding, per the Qwen team’s published benchmarks.
- Gemma 4 (Google DeepMind, 2 April 2026) is the cleanest license-plus-multimodal option, and its E4B edge variant runs in roughly 6 GB of VRAM.
- DeepSeek-R1 is still the transparent-reasoning champion, and its distilled sizes scale from a 1.5B model that runs on a laptop to a 32B that fills a 4090.
- Llama 4 Scout owns the 10-million-token context crown — but it wants ~55 GB at Q4, and that headline number is the wrong reason to choose it for day-to-day dev.
- gpt-oss-20b is the best thing you can fit on a 16 GB machine: OpenAI open weights, adjustable reasoning, roughly o3-mini quality.
- The real selection order for privacy work is VRAM first, job second, license third — not whoever tops the leaderboard.
What running local LLM models actually buys you
When developers talk about local LLM models, they mean open-weight models you download and run on your own hardware — no API key, no per-token bill, no prompt leaving the building. That last part is the whole point for privacy-focused work: your proprietary code, your client’s data, and your half-formed product ideas stay on the disk in front of you. Run the model offline and there is no third party in the loop to log, train on, or leak what you send.
There’s a second, quieter benefit. Once the hardware is paid for, inference is free, so you can hammer a model through a RAG pipeline or a thousand-file code review without watching a meter spin. Once the hardware is paid for, inference is free — so you can build a production RAG pipeline around it or run a thousand-file code review without watching a meter spin.
One disambiguation before we go further, because people trip on it constantly. Gemma is not Gemini. Gemini is Google’s closed model you reach through a paid API; Gemma is the open-weight family you download and own. Same research lineage, completely different deal. The same split applies to “gpt-oss” — that’s OpenAI’s open-weight line, not GPT-5 behind a login.
The VRAM-First Filter: how to actually pick

Here’s the thing nobody really tells you in these roundups: the smartest model on the leaderboard is useless if it won’t load on your card. So run every candidate through three gates, in this order.
Gate 1 — How much VRAM do you have? This is the hard wall. A rough rule that holds up well: at INT4 quantization, a model needs about half a gigabyte of VRAM per billion parameters, before you add KV cache for context (cross-referenced across vendor VRAM guides, 2026). So 8 GB handles a 7–8B model at Q4, 16–24 GB opens up the 14–32B range, and 70B-class weights want 48 GB or more. Pick from the tier you can actually run.
Gate 2 — What’s the real job? Coding, open-ended reasoning, multimodal document work, or stuffing an entire codebase into one prompt? Different models win different jobs, and the “best overall” rarely wins yours.
Gate 3 — Does the license clear your bar? For private and commercial dev this is not a footnote. An Apache 2.0 or MIT model lets you build, charge, fine-tune, and redistribute with almost no strings. A custom license can carry usage caps or acceptable-use clauses that your legal review will choke on.
The model that survives all three gates is your pick. Which means a 16 GB laptop developer and a workstation owner with a 96 GB card are shopping in two different stores — and that’s fine.
Comparison table: local LLM models for private dev (2026)
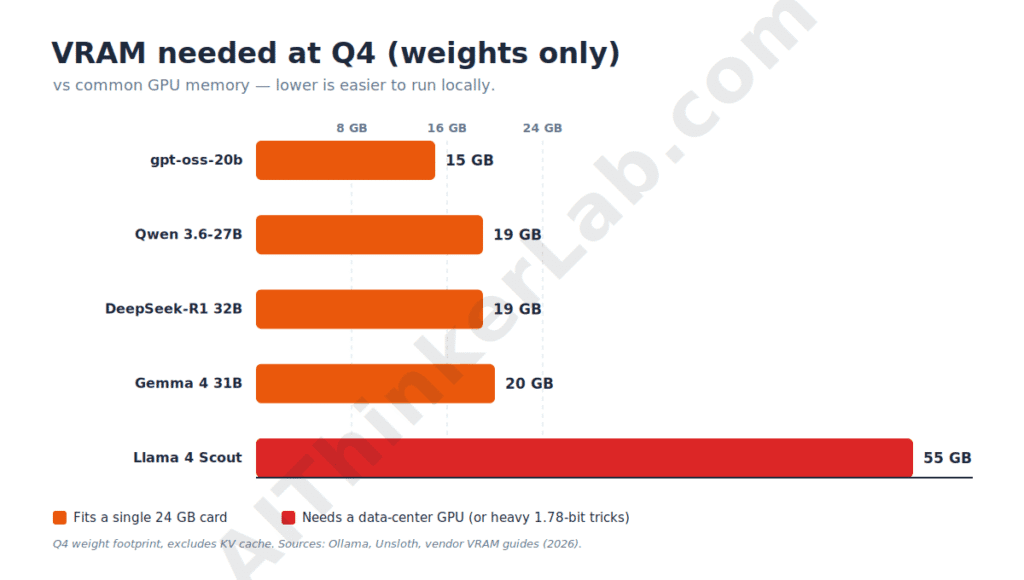
| Model | Best for | Params (total / active) | Min VRAM (Q4) | License | Released |
|---|---|---|---|---|---|
| Qwen 3.6-27B | Everyday coding + dev workhorse | 27B dense | ≈18–20 GB (fits 24 GB) | Apache 2.0 | 22 Apr 2026 |
| Gemma 4 | Multimodal + clean license | 31B dense / 26B MoE (4B active) / E4B | ≈6 GB (E4B) → ≈20 GB (31B) | Apache 2.0 | 2 Apr 2026 |
| DeepSeek-R1 | Transparent step-by-step reasoning | 671B / 37B (distills 1.5–70B) | ≈5 GB (7B) → ≈20 GB (32B) | MIT (Qwen distills Apache 2.0) | 20 Jan 2025 |
| Llama 4 Scout | Massive context / codebase-scale | 109B / 17B | ≈55 GB (24 GB at 1.78-bit) | Llama Community License | 5 Apr 2025 |
| gpt-oss-20b | Best model on a 16 GB machine | 21B / 3.6B | ≈14–16 GB | Apache 2.0 | 5 Aug 2025 |
VRAM figures are weight footprints at Q4-class quantization and exclude KV cache; add 20–40% headroom for longer context. Sources cross-referenced from Ollama, Unsloth, and vendor VRAM guides, 2026.
Which local LLM model is best for privacy in 2026?
For most privacy-focused developers running a single 24 GB GPU in 2026, Qwen 3.6-27B is the best local LLM model: it’s a dense 27B under the unrestricted Apache 2.0 license, it scores 77.2% on SWE-bench Verified per the Qwen team’s published benchmarks (2026), and it fits comfortably on one consumer card. Everything you send it stays on your machine, and the license lets you ship commercial work without a usage cap.
That’s the short version. Now the five, by job.
Qwen 3.6-27B — the everyday workhorse
If you only download one model this year, make it this one. Released 22 April 2026 by Alibaba’s Qwen team under Apache 2.0, Qwen 3.6-27B is a dense 27-billion-parameter model that — and this is the surprising part — beats the previous-generation Qwen 3.5-397B-A17B flagship on every major agentic coding benchmark, according to the qwen.ai release notes (2026). A model you can run on one card outscoring one fourteen times its total size is the clearest sign yet that the dense ~27B tier has become the practical center of gravity for local dev.
Being dense matters here in a way the spec sheet hides. There’s no mixture-of-experts routing to configure and no surprise memory spikes — every parameter fires on every token, so behavior is predictable when you wire it into a tool-calling loop or a code agent. It fits a 24 GB card at Q4, supports both thinking and non-thinking modes, and pulls in one line: ollama run qwen3.6:27b.
So what does that buy you day to day? A local coding assistant that handles real refactors and multi-step tool use, with zero tokens leaving your machine and zero license drama when you turn the project into a product.
Gemma 4 — clean license, real multimodal
Gemma 4 is the model I’d hand to someone whose blocker has historically been legal, not technical. Google DeepMind shipped it on 2 April 2026, and the headline for builders isn’t a benchmark — it’s the move to a plain Apache 2.0 license (Google DeepMind, 2026). Earlier Gemma releases used a custom license that enterprise legal teams routinely flagged; that friction is gone.
The family scales the whole way down. There’s a 31B dense model, a 26B mixture-of-experts that activates only about 4B parameters per token, and edge variants — the E4B runs in roughly 6 GB of VRAM, and a unified-multimodal 12B landed on 3 June 2026, processing images and audio without separate encoders. Every variant takes image and video input; the small ones take audio too. The 31B posts 89.2% on AIME 2026 and 80.0% on LiveCodeBench v6 per Google DeepMind’s technical report (2026), and the family has crossed 400 million downloads with over 100,000 community variants.
The catch is honest: the flagship 31B wants a 24 GB card, which keeps it out of pure-laptop territory, and output is text-only — no speech out. Pull it with ollama pull gemma4:e4b (or the larger sizes). For a privacy-focused builder who needs to read charts and screenshots locally and wants a license their lawyer won’t blink at, Gemma 4 is the safest bet on this list.
DeepSeek-R1 — reasoning you can watch
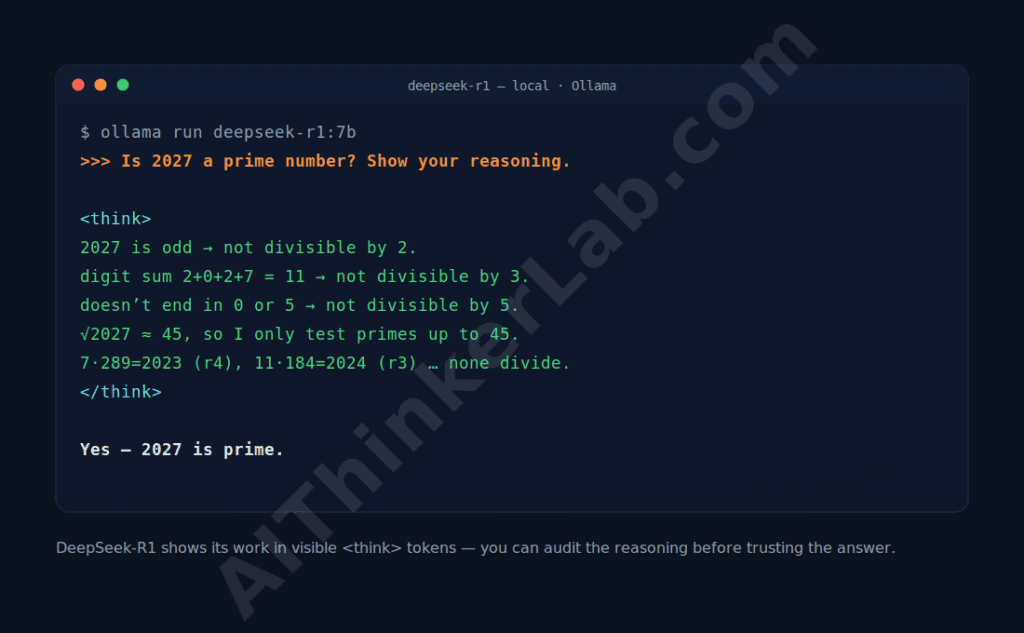
DeepSeek-R1 earns its spot for one feature nothing else here matches: it thinks out loud. Released 20 January 2025 under the permissive MIT license, R1 wraps its chain-of-thought in visible <think> tokens, so you can read the model reason, catch where it went sideways, and trust the answer — or not — based on the work, not just the output (DeepSeek, GitHub, 2025).
The full 671B model is server territory, so ignore it. What matters for local dev is the distilled family — 1.5B, 7B, 8B, 14B, 32B, and 70B — fine-tuned from Qwen and Llama bases on R1’s reasoning traces. The 32B distill lands around 18–20 GB at Q4 and fits a 4090 with a little headroom; the 7B runs on an 8 GB card; the 1.5B runs on basically any laptop. The Qwen-based distills inherit Apache 2.0, which keeps them commercially clean. The May 2025 R1-0528 refresh added JSON output and function calling and cut hallucinations, which reopened R1 for agentic use it couldn’t handle at launch.
Two cautions, because trust means saying them out loud. R1’s reasoning traces run long — expect more tokens and more latency per answer — and the model occasionally slips Chinese characters into the <think> block. Neither touches your privacy when you run it locally, which is the point: the data never leaves. So what’s it for? Debugging, math-heavy logic, and anything where you’d rather see the reasoning than take the answer on faith.
Is a bigger context window actually better? The Llama 4 Scout question

Short answer: almost never, for local dev. And that puts me at odds with half the roundups out there.
Llama 4 Scout, released by Meta on 5 April 2025 (not 2026, despite what a lot of SEO posts claim), is a genuinely impressive MoE — 109B total, 17B active, natively multimodal, and carrying a 10-million-token context window, the largest of any open model (Meta / apxml, 2025). It’s a real engineering feat. It is also the wrong default for most private dev, and here’s why.
That 10M number is a ceiling, not a setting. The KV cache grows with context, so most people who run Scout locally stay near 8K–32K tokens anyway — the long window sits there unused. Worse, Scout wants about 55 GB of VRAM at Q4; you only squeeze it onto a 24 GB card with Unsloth’s 1.78-bit dynamic GGUF, and then it crawls at roughly 20 tok/s with CPU offload (Unsloth docs, 2026). Meanwhile, on the Artificial Analysis Intelligence composite tracked through May 2026, reasoning-class models like Qwen 3.6-27B sit well above Scout’s non-reasoning score. You’d be spending far more VRAM to get less day-to-day capability.
There’s also the license. Llama 4 ships under Meta’s custom community license — free for commercial use only below 700 million monthly active users, with acceptable-use clauses attached. Fine for an indie dev, a real question for an enterprise. Pull it with ollama pull llama4:scout if you genuinely need to reason over a whole codebase or a book-length document in one shot. That’s the one job where Scout is the right answer. For everything else, it’s a flex you’ll pay for in VRAM.
Can I run a local LLM on 16GB of VRAM? Yes — start with gpt-oss-20b
If your machine tops out around 16 GB, the best model you can comfortably run is gpt-oss-20b — OpenAI’s open-weight MoE with 21B total parameters but only 3.6B active per token, delivering roughly o3-mini-class quality with adjustable reasoning effort (Ollama library, 2026). It’s Apache 2.0, so commercial use is unrestricted, and it pulls with ollama run gpt-oss:20b. And if even 16 GB is a stretch, or you can’t install anything on the machine, you can run a tiny model entirely in your browser — no GPU, no install.
The MoE design is what makes it fit: because only 3.6B parameters activate per token, it generates fast despite the 21B total, and the memory footprint stays in 16 GB range. For a developer on a single mid-tier GPU or a 16 GB Mac who wants a capable general model plus a reasoning dial they can turn up for hard problems, this is the value pick of the list — frontier-adjacent quality on hardware you probably already own.
What most “best local LLM” lists get wrong
Two things, and they’re the two that matter most for private dev.
First, they rank by leaderboard score or total parameter count, which is exactly backwards. The parameter count tells you what you can’t run; the license and the post-KV-cache VRAM tell you what you should run. A list that opens with a 400B model you’ll never load on your 4090 has wasted your time before the first heading.
Second, they treat the license as trivia. For a hobby chat, sure. For a developer turning local inference into a shipped product — or a consultant who can’t let client data touch a third-party server — the license is the first gate, not the last. That’s why three of the five picks here are Apache 2.0 or MIT, and why the one custom-licensed model (Scout) comes with an asterisk. Rank by what constrains you, and the right model usually picks itself.
Where this leaves you
Pick by the card in your machine, not the model at the top of a chart. On a 24 GB GPU, install Qwen 3.6-27B tonight and you have a private coding partner that rivals last year’s flagships. On 16 GB, gpt-oss-20b gets you most of the way there. Reach for Gemma 4 when you need multimodal and a spotless license, DeepSeek-R1 when you want to see the reasoning, and Llama 4 Scout only when a genuinely enormous context is the actual job. The models stopped being the bottleneck a while ago — what’s left is matching one honestly to your hardware and your license bar, and that decision is now firmly yours to make. Expect the dense ~27B tier to keep getting better fast; the next refresh of this list will almost certainly reshuffle the order.
Sources
- Unsloth — Llama 4 run & fine-tune docs: https://unsloth.ai/docs/models/tutorials/llama-4-how-to-run-and-fine-tune
- Google DeepMind — Gemma 4 launch announcement: https://blog.google/innovation-and-ai/technology/developers-tools/gemma-4/
- Google AI for Developers — Gemma releases / model card: https://ai.google.dev/gemma/docs/releases
- Qwen Team — Qwen3.6-27B release notes: https://qwen.ai/blog?id=qwen3.6-27b
- Hugging Face — Qwen/Qwen3.6-27B model card: https://huggingface.co/Qwen/Qwen3.6-27B
- DeepSeek-AI — DeepSeek-R1 repository: https://github.com/deepseek-ai/DeepSeek-R1
- Ollama — model library: https://ollama.com/library