Key Takeaways
- RAG isn’t one design; it’s eight patterns on a complexity ladder, from naive retrieval up to agentic and multimodal systems.
- The cheapest upgrades win most: adding hybrid retrieval (dense + BM25) and a reranker like Cohere Rerank v3 fixes the majority of retrieval failures before you touch anything exotic.
- GraphRAG (Microsoft, open-sourced July 2024) earns its cost only on cross-document, “connect-the-dots” questions — not on simple lookups.
- Agentic RAG with knowledge graphs cut hallucination by roughly 62% across 47 production deployments in a May 2026 MLOps Community benchmark — at the price of latency and orchestration complexity.
- Your embedding model sets the ceiling: OpenAI’s text-embedding-3-large (64.6 MTEB) is the safe default, while open Qwen3-Embedding-8B tops the multilingual leaderboard at 70.58.
- For most teams under ~5–10 million vectors, pgvector inside existing Postgres is enough; reach for Qdrant, Weaviate, or Pinecone when scale or filtering demands it.
Introduction

If you want to build RAG systems that survive contact with real users in 2026, the hard part was never the demo — it’s everything after. Retrieval-Augmented Generation (RAG) is an architecture that lets a language model pull relevant external documents at query time and ground its answer in them, instead of relying only on what it memorized during training. That definition has been stable for years. What changed is the menu: RAG has split into a family of eight distinct architecture patterns, each solving a different failure mode.
Here’s the tension nobody warns you about. A naive retrieve-and-generate pipeline takes an afternoon. Making it accurate, fast, traceable, and cheap enough to run at scale takes months. This guide walks the eight patterns in the order you should actually adopt them — and tells you, bluntly, which ones most teams reach for too soon.
What “Production-Ready” Actually Means When You Build RAG Systems
A production-ready RAG system is one where retrieval reliably surfaces the right context, the model grounds its answer in that context with a low hallucination rate, latency stays within your p99 budget, every answer is traceable to a source, and per-query cost is predictable as volume grows. A weekend demo clears none of those bars except the first, and only on easy questions.
That distinction matters because the failure modes hide until traffic finds them. A pipeline that answers your ten test questions perfectly will quietly miss the right chunk on the eleventh — the one a real user actually asks — and the model will confidently fill the gap with something plausible and wrong. So the real job isn’t building a RAG system; it’s building one whose failures you can see and fix. That’s why the patterns below are ordered by the specific failure each one removes.
The 8 RAG Architecture Patterns (and When Each Wins)
The eight patterns form a ladder. Each step adds capability and cost. The skill is climbing only as high as your problem requires.
| # | Pattern | Best for | Relative cost/latency | Complexity | Reach for it when |
|---|---|---|---|---|---|
| 1 | Naive RAG | Simple lookups, FAQs, MVPs | Lowest | Low | You’re starting out |
| 2 | Hybrid retrieval | Jargon, codes, names, mixed corpora | Low | Low–Med | Dense search misses exact terms |
| 3 | Retrieve-then-rerank | Precision-critical answers | Low–Med | Low–Med | Top results are “close but wrong” |
| 4 | Query transformation | Vague or multi-part questions | Med | Med | Users ask messy, compound queries |
| 5 | Corrective / Self-RAG | High-stakes accuracy | Med–High | Med–High | Wrong answers are expensive |
| 6 | GraphRAG | Cross-document synthesis | High | High | Answers require connecting entities |
| 7 | Agentic RAG | Complex, multi-hop research | Highest | High | One retrieval pass isn’t enough |
| 8 | Multimodal RAG | Images, tables, audio, video | High | High | Knowledge isn’t just text |
Pattern 1 — Naive RAG
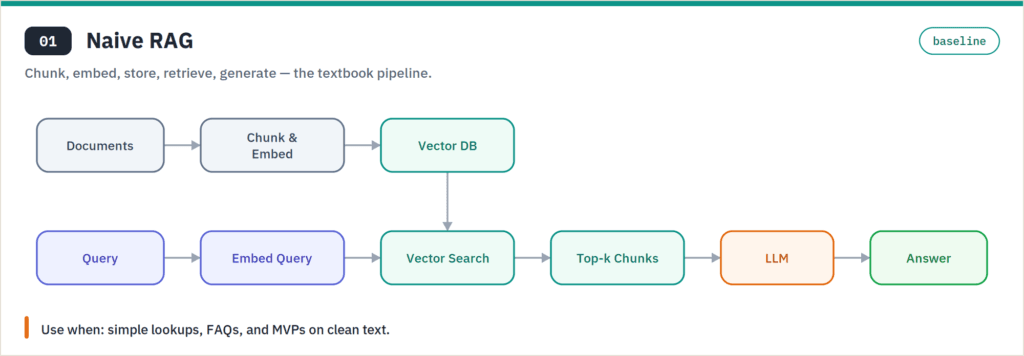
Naive RAG is the textbook pipeline: chunk your documents, embed them, store the vectors, then for each query embed it, retrieve the nearest chunks, and stuff them into the prompt. It’s the right starting point — simple, cheap, and good enough for FAQs and clean, factual lookups. Its weakness shows the moment retrieval grabs the wrong chunk, chunks are sized badly, or a question needs reasoning across several documents.
Pattern 2 — Hybrid Retrieval
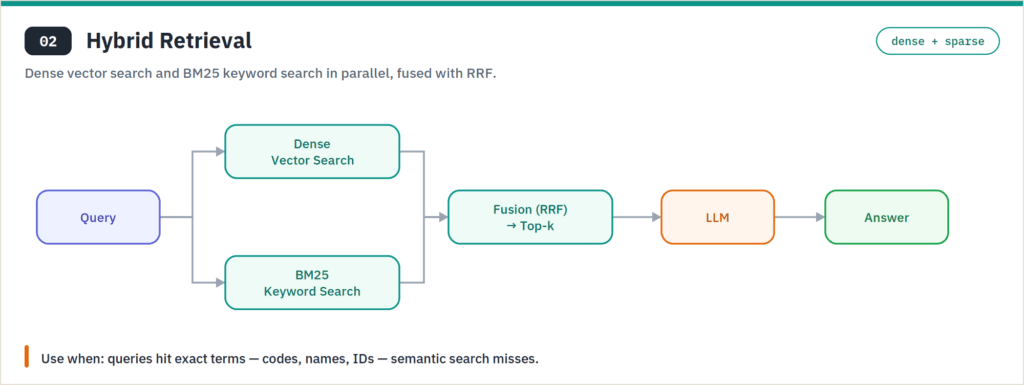
Hybrid retrieval combines dense vector search with sparse keyword search (BM25), then fuses the two result lists, often with Reciprocal Rank Fusion. It matters because pure semantic search is weak exactly where enterprise data is strong: part numbers, error codes, proper nouns, legal citations — tokens where an exact match beats a fuzzy one. Weaviate, Qdrant, and Elasticsearch support hybrid search natively. This is the single highest-return upgrade most teams skip, and it’s nearly free to add.
Pattern 3 — Retrieve-then-Rerank
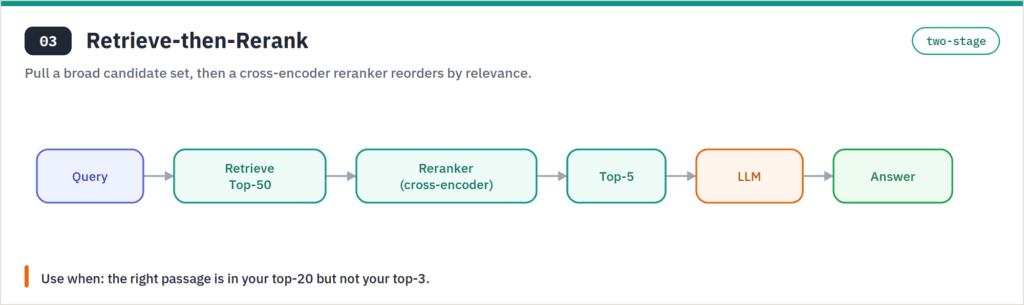
This two-stage pattern retrieves a broad candidate set, then runs a dedicated cross-encoder reranker — Cohere Rerank v3 is the common pick — to reorder by true relevance before the top few reach the model. It fixes the “close but not quite” problem where the right passage is in your top 20 but not your top 3. Reranking adds a little latency and a small per-query cost, and in return it sharpens precision more than almost any embedding upgrade. Pair it with a cheaper embedding model and you often beat a pricier one used alone.
Pattern 4 — Query Transformation
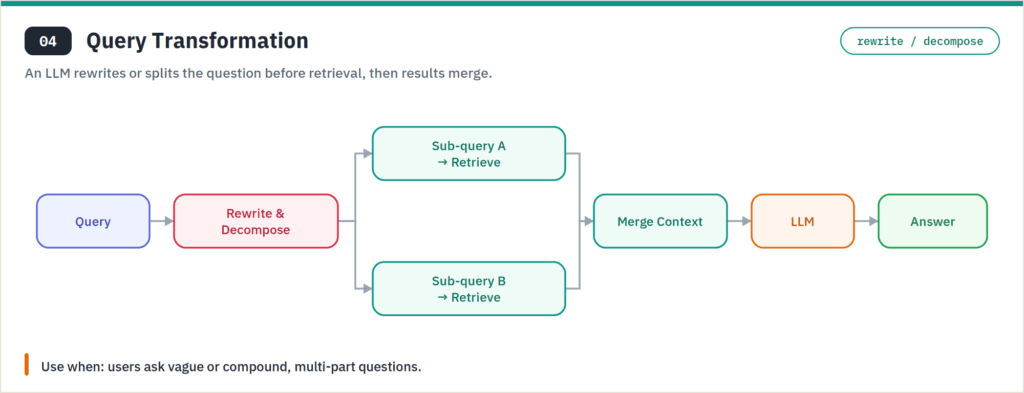
Query transformation rewrites the user’s input before retrieval — expanding it, decomposing a compound question into sub-queries, or generating a hypothetical answer to embed instead of the raw question (the HyDE technique). It earns its place when users ask vague or multi-part questions that don’t map cleanly to any single chunk. The cost is extra LLM calls and a bit of latency per query, so reserve it for query distributions that are genuinely messy.
Pattern 5 — Corrective RAG and Self-RAG
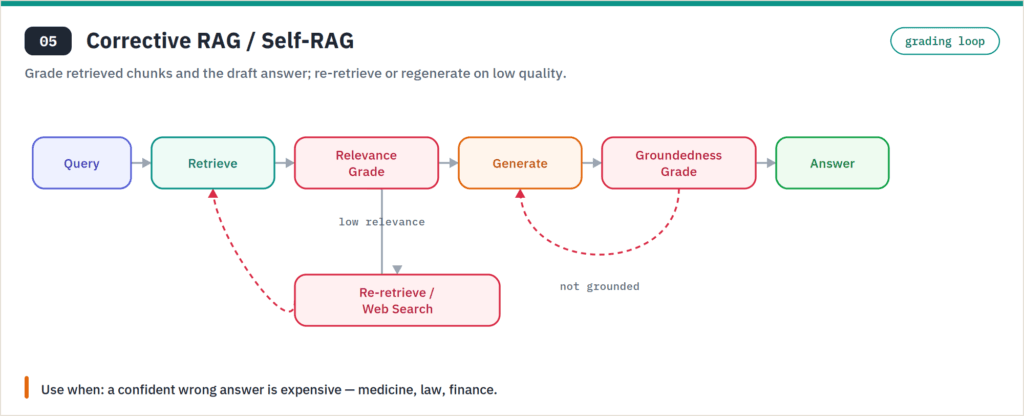
Corrective RAG (CRAG) and Self-RAG add a grading loop: the system evaluates whether retrieved chunks are actually relevant and whether the draft answer is grounded, then re-retrieves or abstains if not. This is your guardrail pattern for high-stakes domains — medicine, law, finance — where a confident wrong answer costs more than a slow one. The trade-off is real: every grading step is another model call, so you’re buying accuracy with latency and tokens. Worth it when wrong answers are expensive; overkill for a help-center bot.
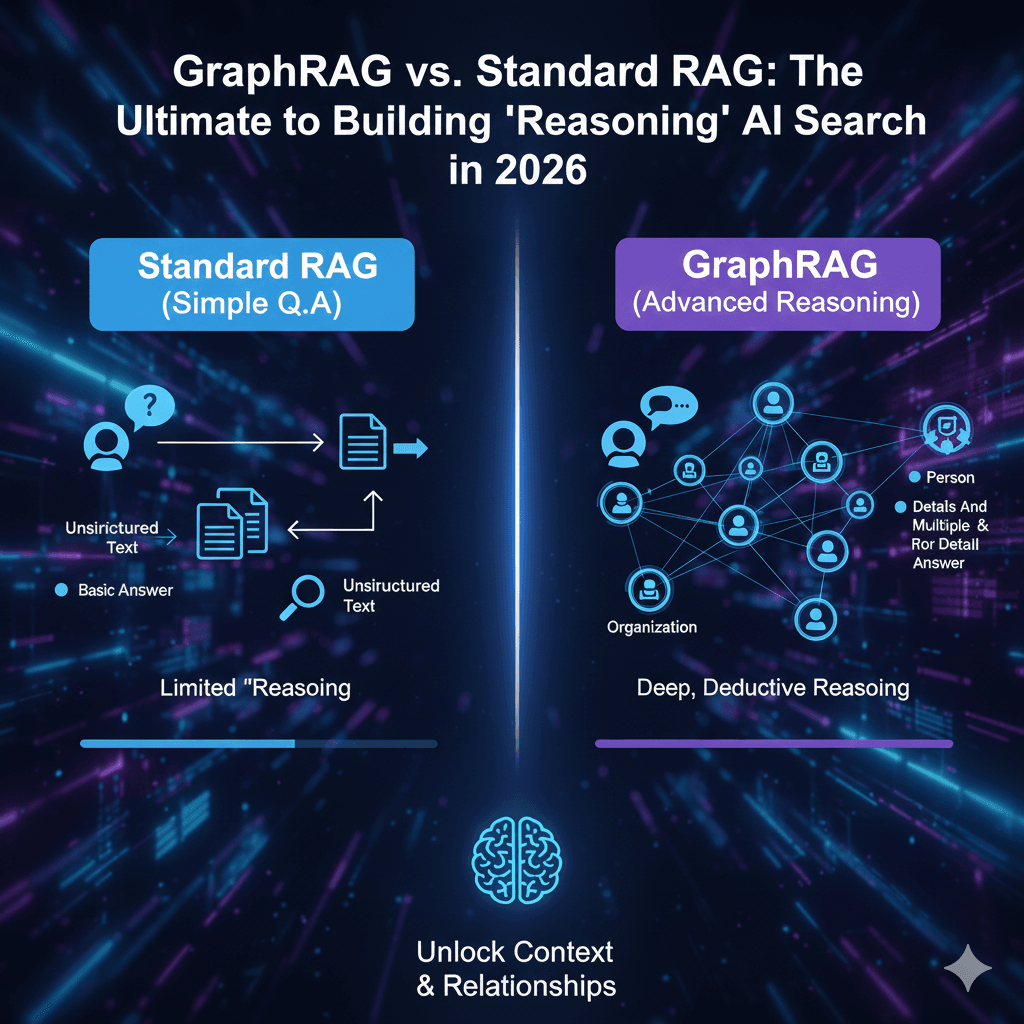
Pattern 6 — GraphRAG
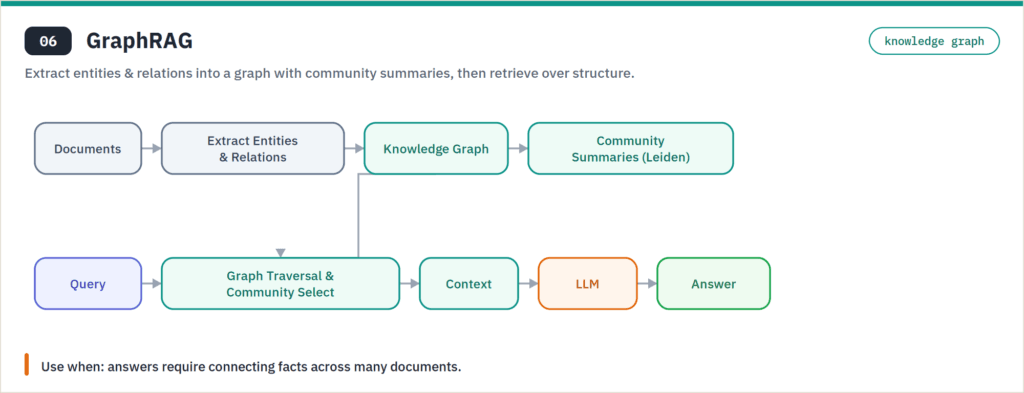
GraphRAG builds a knowledge graph from your corpus — extracting entities and relationships, then clustering them into community summaries — and retrieves over that structure instead of isolated chunks. Microsoft open-sourced GraphRAG in July 2024 (it has since drawn 20,000+ GitHub stars), using LLM-driven entity extraction and the Leiden algorithm for hierarchical community detection. According to Microsoft Research, the payoff appears on holistic, cross-document questions — “what are the main themes across these 500 reports” — where flat semantic search falls apart. The catch is indexing cost: building and maintaining the graph is expensive, so GraphRAG is wrong for simple lookups and right when answers require connecting scattered facts. If you’re weighing this pattern against plain vector search, our full GraphRAG vs standard RAG comparison breaks down the architecture, indexing cost, and the exact query types where graph traversal beats chunk retrieval.
Pattern 7 — Agentic RAG
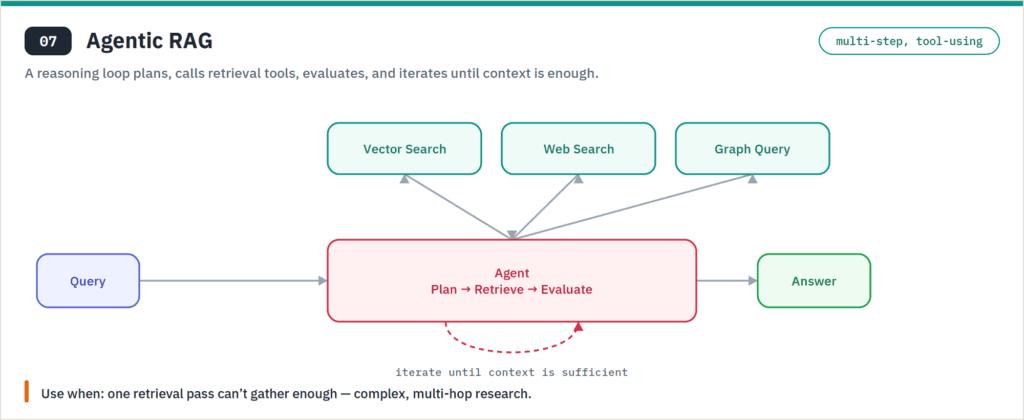
Agentic RAG hands control to a reasoning loop: the model decomposes a complex query into sub-queries, decides which retrieval tools to call, runs them (sometimes in parallel), evaluates what came back, and iterates until it has enough context. Microsoft’s Azure AI Search calls this “agentic retrieval”; the broader ecosystem builds it with LangGraph, CrewAI, or the Claude Agent SDK. In a May 2026 MLOps Community benchmark reported by RAG About It, agentic pipelines paired with knowledge graphs reduced hallucination rates by roughly 62% across 47 production deployments versus naive setups. A June 2026 Carnegie Mellon preprint reported a related result — hallucinations falling from 14.1% to 4.9% on a 9,000-question financial-compliance dataset, at the cost of about 220ms extra latency. That 220ms sounds trivial, but at p99 on a live support chat it’s the line between “instant” and “laggy,” so budget it as a product decision, not just an engineering one.
Pattern 8 — Multimodal RAG
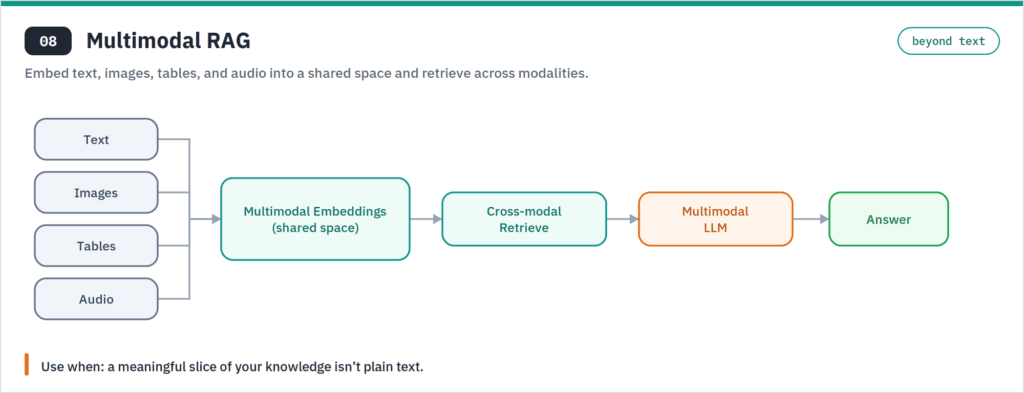
Multimodal RAG retrieves across images, tables, audio, and video — not just text — using models like Cohere Embed v4 that embed text and images into a shared space. It’s the pattern for knowledge that doesn’t live in paragraphs: a maintenance engineer querying turbine-failure images, a finance team pulling figures out of scanned tables, a support bot reading product photos. It’s powerful and the most operationally demanding of the eight, so adopt it only when a meaningful slice of your knowledge is genuinely non-textual.
How to Choose an Architecture When You Build RAG Systems
Don’t pick a pattern by novelty — pick it by your failure mode, then climb only as far as needed. Here’s the contrarian part: the RAG discourse in 2026 is loud about GraphRAG and agents, but the boring middle of the ladder is where most teams find their biggest, cheapest wins. If your retrieval is missing obvious exact-term matches, you don’t need an agent — you need hybrid search and a reranker, and you can ship both this week.
Use a simple decision path. Start at naive RAG. Add hybrid retrieval the moment you see misses on names, codes, or jargon. Add a reranker when the right answer is in your candidate set but not at the top. Reach for query transformation when your users ask compound, vague questions. Add CRAG/Self-RAG grading when a wrong answer is genuinely costly. Move to GraphRAG only for cross-document synthesis, and to agentic RAG only when a single retrieval pass demonstrably can’t gather enough context. Adopt multimodal when your knowledge isn’t text. Every step up should be justified by a failure you’ve actually measured — not by a benchmark someone posted.
The Production Stack: Embeddings, Vector DBs, and Frameworks
Three choices define your stack, and they’re more independent than they look. Your embedding model sets the quality ceiling — no reranker or prompt trick recovers what a weak embedding never encoded. OpenAI’s text-embedding-3-large (64.6 MTEB, around $0.13 per million tokens) is the safe, well-integrated default; text-embedding-3-small is 6.5× cheaper and fine when paired with a reranker; and on the open-source side, Alibaba’s Qwen3-Embedding-8B tops the MTEB multilingual leaderboard at 70.58, with Cohere Embed v4 and Voyage’s retrieval-tuned models strong for multimodal and domain-specific work. Because switching embedding models means re-indexing everything, this is the one decision worth over-investing in up front.
Your vector database is mostly a storage-and-search engine, largely agnostic to which embeddings you feed it. For teams already on Postgres with under roughly 5–10 million vectors, pgvector (with pgvectorscale) is often all you need — one less system to run. Past that, Qdrant leads on filtered queries and metadata depth (popular for legal and compliance work), Weaviate is the hybrid-search standout, and Pinecone’s managed serverless tier is the fastest path to production if you’d rather not operate infrastructure. RAG is the dominant use case driving vector-database adoption in 2026, with the market tracking from about $2.58B in 2025 toward $3.2B in 2026.
Your framework is the orchestration layer. LangChain and LangGraph both hit their 1.0 milestone in October 2025 — LangChain for building agents fast, LangGraph for running them durably in production. LlamaIndex remains the retrieval-first choice, strongest on messy document ingestion via LlamaParse. Many production teams combine them: LlamaIndex for the data plane, LangGraph for the control plane.
Every RAG architecture pattern covered in this guide introduces a document ingestion step — and that step is the primary entry point for indirect prompt injection attacks. Before deploying any of these patterns in a production environment with an autonomous AI agent, review the five architectural defenses against LLM prompt injection in 2026.
There’s a fourth choice the stack discussions skip: the generation model itself. If keeping private data on-premises matters, that model can stay fully local — see which local LLM models are worth self-hosting for private generation.
Evaluation and Observability — the Part Teams Skip
The teams winning at RAG in 2026 aren’t the ones with the cleverest retrieval algorithm — they’re the ones who built evaluation infrastructure first. Before you optimize anything, you need to measure retrieval quality (did the right chunk show up?), groundedness (did the answer use it?), and end-to-end accuracy on a real question set drawn from your own users, not a synthetic benchmark. Tools like LangSmith make per-query tracing routine. Without this, every “improvement” is a guess, and you’ll burn weeks tuning the wrong layer. Measure your failure modes, then apply the narrowest pattern that fixes them — that discipline beats architectural sophistication every time. One security note worth flagging: any system that ingests external content inherits a new attack surface. A single planted document can quietly rewrite what your model returns — see our deep dive on how RAG poisoning attacks corrupt your knowledge base — so treat retrieval-source trust as part of your eval, not an afterthought.
The Bottom Line
Eight patterns, one rule: climb the ladder only as far as your problem forces you. The fastest path to a RAG system that holds up in production isn’t GraphRAG or an agent swarm — it’s a naive pipeline upgraded with hybrid retrieval and a reranker, measured against your real users, and made fully traceable before you add anything fancier. Earn each layer of complexity with a failure you’ve actually seen. Do that, and you’ll ship something that gets more trustworthy as it scales — while the teams that started at the top of the ladder are still debugging why their agent loops cost ten times more and answer no better. Start simple, measure everything, and let the data tell you when to climb.
Sources
- Enterprise GraphRAG hallucination benchmark (secondary): https://ragaboutit.com/5-enterprise-graphrag-wins-that-slash-hallucination-by-62/
- Microsoft Research — Project GraphRAG: https://www.microsoft.com/en-us/research/project/graphrag/
- GraphRAG documentation: https://microsoft.github.io/graphrag/
- Microsoft Learn — Agentic retrieval / RAG in Microsoft Foundry: https://learn.microsoft.com/en-us/azure/foundry/concepts/retrieval-augmented-generation
- IBM Think — What is Retrieval-Augmented Generation: https://www.ibm.com/think/topics/retrieval-augmented-generation
- arXiv — RAG survey (architectures, robustness): https://arxiv.org/pdf/2506.00054
- LangChain / LangGraph 1.0 (Oct 2025) comparison: https://www.clickittech.com/ai/langchain-1-0-vs-langgraph-1-0/
- Embedding models comparison (MTEB, pricing), 2026: https://fast.io/resources/best-embedding-models-for-rag-agents/
- Vector database market & benchmarks, 2026: https://www.secondtalent.com/resources/pinecone-vs-weaviate-vs-qdrant-vs-pgvector/
Great content! Keep up the good work!