Educational disclaimer: This article is provided for educational and defensive security purposes only. It explains how RAG poisoning works so that developers, security teams, and organizations can understand the risk and protect their own systems. It does not provide instructions for attacking, exploiting, or compromising any system you do not own or operate.
Do not use any information here to access, disrupt, or damage systems without explicit authorization — doing so may be illegal. The author and publisher accept no liability for any misuse of this content.
Key Takeaways
- RAG poisoning is an integrity attack on the knowledge base your AI reads from — an attacker plants malicious content in the retrieval corpus so the model confidently returns attacker-chosen answers.
- It is not the same as training-data poisoning. Training poisoning corrupts the model during pretraining or fine-tuning; RAG poisoning corrupts the documents the model fetches at query time, so a clean model still produces compromised output.
- There is a third variant worth separating from RAG poisoning: MCP tool poisoning, where the malicious payload hides inside a tool’s description metadata rather than your knowledge base — making it invisible to retrieval-layer defenses entirely. If your stack routes through MCP servers, how MCP tool poisoning works and how to stop it is the parallel read.
- One bad document can be enough. The 2025 CorruptRAG research showed a single injected text can flip answers for a targeted query — earlier attacks assumed you needed to outnumber the clean documents.
- OWASP now tracks this directly. The 2025 OWASP Top 10 for LLM Applications lists Data and Model Poisoning as LLM04 and added Vector and Embedding Weaknesses as LLM08 — the first RAG-specific category.
- The fix lives in your data pipeline, not your model. Source authentication, ingestion validation, access control, provenance, and detection filters like RAGuard stop far more real attacks than any model tweak.
Introduction
In October 2025, Anthropic, the UK AI Security Institute, and the Alan Turing Institute published the largest data-poisoning study to date and found something uncomfortable: as few as 250 malicious documents could backdoor a large language model regardless of its size. That study was about training data — but it landed in the middle of a much louder 2026 conversation about a closely related and arguably more practical threat: RAG poisoning, where attackers corrupt the live knowledge base an AI assistant reads from. As of May 2026, retrieval-augmented generation runs customer support, internal search, and a growing fleet of autonomous agents — which means the “source of truth” feeding those systems is now a target. This guide explains what RAG poisoning is, how the attacks work, what the research actually shows (and what gets misquoted), and the defenses that hold up.
What Is RAG Poisoning?
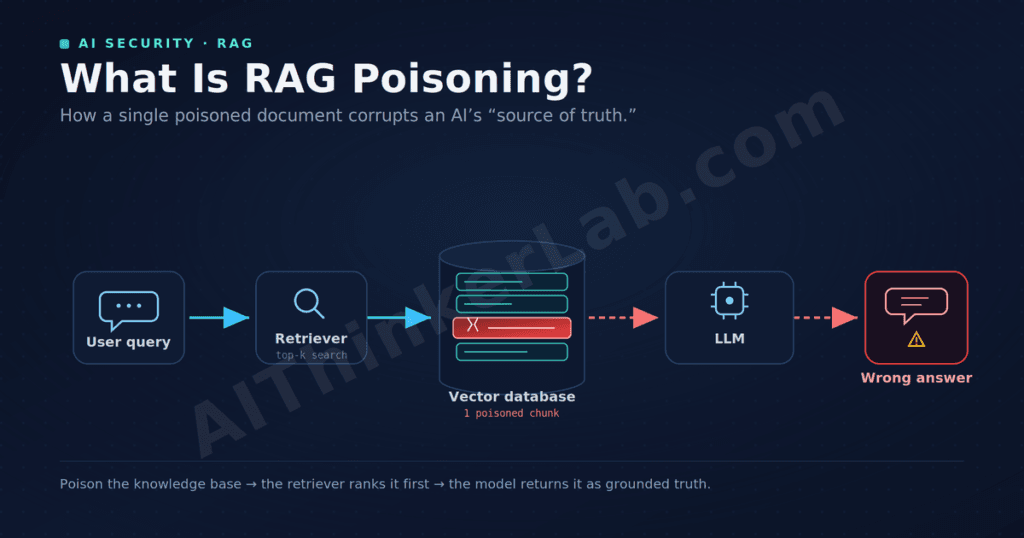
RAG poisoning is an attack in which an adversary injects malicious or misleading content into the knowledge base of a retrieval-augmented generation system, so that when the system retrieves and feeds that content to its language model, the model produces attacker-controlled answers. The model itself stays clean — the corruption lives in the documents it trusts. How retrieval-augmented generation works.
That distinction is the whole game. A RAG system has three moving parts: a knowledge base (often a vector database of embedded documents), a retriever that pulls the most relevant chunks for a query, and a language model that generates an answer grounded in those chunks. RAG was designed to make models more accurate by giving them fresh, proprietary, citable context. But it also hands the model a new dependency — and anything the model treats as authoritative becomes a place to hide an attack.
The OWASP Top 10 for LLM Applications formalized this in its 2025 edition. Poisoning sits at LLM04 (Data and Model Poisoning), and the 2025 list added an entirely new category — LLM08, Vector and Embedding Weaknesses — specifically because RAG architectures introduced attack surfaces that didn’t exist when the first list was written. Read those two categories together and you get the shape of the problem: it’s about the data going in and the retrieval layer that serves it back out, not the model in the middle.
RAG Poisoning vs. Training-Data Poisoning vs. Prompt Injection

These three terms get used interchangeably, and that confusion is itself a security risk — you can’t defend what you’ve mislabeled. Here’s the clean separation.
Training-data poisoning corrupts the model before it ships, by slipping malicious examples into pretraining or fine-tuning data. The damage is baked into the weights. The Anthropic study above is this category: the backdoor lived in the model, triggered by a phrase, and no amount of clean retrieval would remove it.
RAG poisoning corrupts the knowledge base the model consults at runtime. The weights are untouched. Swap out the poisoned documents and the system behaves again. This makes RAG poisoning more recoverable but also far easier to pull off — you don’t need to influence a multi-billion-token training run; you just need write access to a wiki page, a support article, or a public webpage your crawler ingests.
Prompt injection is the closest cousin, and the two overlap. Indirect prompt injection hides instructions inside content the model reads — which is also how a lot of RAG poisoning is delivered. The difference is intent and mechanism: prompt injection aims to hijack the model’s instructions (“ignore your rules and do X”), while RAG poisoning aims to corrupt the model’s facts (return the wrong answer, recommend the wrong product, cite the fake policy). In practice a single poisoned document can do both, which is why OWASP treats prompt injection (LLM01) and poisoning (LLM04) as related but distinct.
So what? Because the defenses don’t transfer. Guardrails that strip injected instructions won’t catch a factually poisoned document that contains no instructions at all — just a plausible lie that the retriever ranks highly and the model dutifully repeats.
How RAG Poisoning Works: The Attack Chain
A RAG poisoning attack follows a predictable chain. First, the attacker identifies a content source the system ingests — a public web page, a shared drive, a Confluence or Notion space, a support-ticket archive, a code repository. Second, they craft a document that is semantically optimized to match a target query, so the retriever ranks it in the top-k results. Third, they embed the payload: a false fact, a manipulated recommendation, or hidden instructions. Fourth, they get it indexed into the vector database. From then on, every query that semantically matches the poisoned content retrieves it — and the model, trusting its retrieved context, presents the lie as grounded truth, often with a citation that makes it look more credible.
The reason this works is the same reason indirect prompt injection works: language models struggle to distinguish data from instructions, and trusted data from untrusted data. To the model, a retrieved chunk from your “authoritative” knowledge base and a retrieved chunk an attacker planted last week look identical. The retriever ranks by semantic similarity, not by trustworthiness — so a well-crafted poison can actually outrank the legitimate document it’s impersonating.
Make it concrete. Say you run a support assistant over your help center, and the real article says refunds are issued within 30 days. An attacker — or a careless contractor — adds a new article titled “Updated Refund Policy 2026” packed with the exact phrasing customers use when they ask about refunds: refund, money back, return window, how long. Because it’s denser in query-matching terms than your original, the retriever ranks it first. Now every refund question pulls the poisoned chunk, and your assistant cheerfully tells customers they have 90 days — grounded, cited, and wrong. No model was hacked. No prompt was injected. A single document quietly rewrote your policy, and you won’t notice until the chargebacks or the complaints arrive.
Where the Poison Gets In: The 2026 Attack Surface
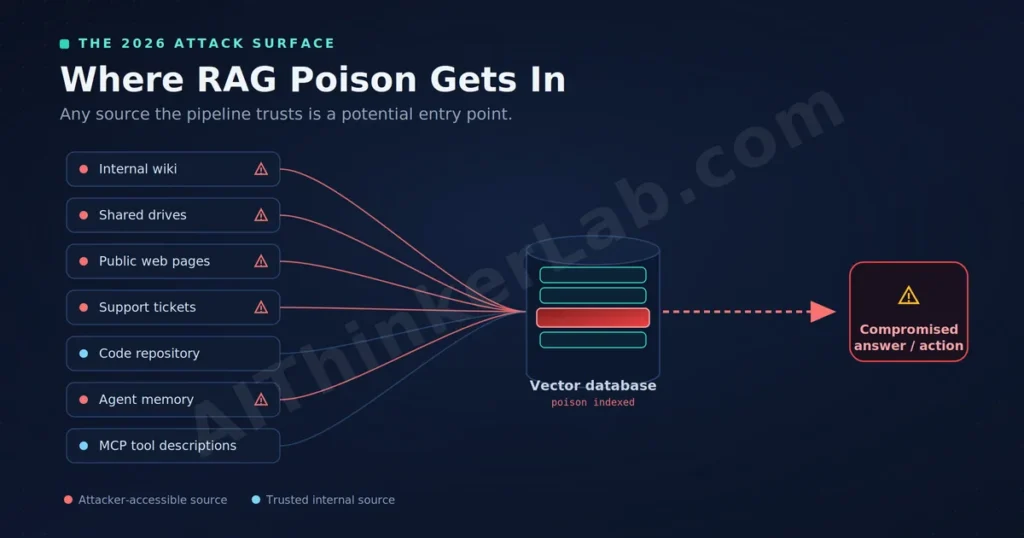
The attack surface in 2026 is wider than most teams map. Poison can enter through any source the pipeline trusts, and trust is usually implicit.
The most common entry point is ingestion from semi-open sources: internal wikis, shared drives, ticketing systems, and code repos that many people — sometimes including customers, contractors, or vendors — can write to. An attacker (or a disgruntled insider) edits a page; the next indexing run pulls it in. One 2026 industry write-up described exactly this: a rogue employee quietly edited an internal FAQ to include a subtly wrong instruction, caught only because audit logs showed who changed what and when.
The public web is the second vector, and it scales. If your RAG corpus ingests external pages, an attacker can publish SEO-optimized content designed to be crawled and retrieved — effectively poisoning a global “source of truth.” The same logic applies to AI-powered search itself: when a generative search experience like Google AI Mode synthesizes an answer from retrieved web content, poisoned pages crafted to rank well can surface manipulated claims to millions of users.
Newer surfaces matter too. Agent memory — the persistent store an autonomous agent reads across sessions — can be poisoned by attacks like AgentPoison and MINJA so the agent carries the corruption forward. And tool integrations, including MCP tool descriptions, are themselves text the model interprets, which means a tainted tool description can steer behavior the same way a poisoned document can.
The Main Types of RAG Poisoning Attacks
Researchers generally sort RAG poisoning into three objectives, and the 2025 RAG Security Bench cataloged 13 representative attacks across them.
Targeted poisoning is the headline threat: make the system return a specific attacker-chosen answer for a specific query. The foundational academic work here is PoisonedRAG (Zou, Geng, Wang, and Jia), presented at USENIX Security 2025, which used an LLM to craft poisoned texts that steer a RAG system toward attacker-specified outputs. The unsettling 2025 follow-up, CorruptRAG, showed that injecting just one poisoned text per query can achieve high success rates — dismantling the earlier assumption that an attacker needed to flood the corpus to win.
Denial-of-service poisoning suppresses useful answers — the system refuses or returns garbage for certain inputs, degrading the assistant into uselessness.
Trigger-based DoS is the stealthiest: the system behaves normally until a query contains a predefined trigger, at which point it malfunctions. This mirrors the backdoor pattern from training poisoning, where a model looks healthy on every standard test and only misbehaves on a secret phrase.
And in agentic deployments, agent-memory poisoning (AgentPoison, MINJA) extends all of the above across time, planting corruption that persists between sessions.
What the Research Actually Shows (and What Gets Misquoted)

Here’s the most-cited and most-misunderstood result in this space. In October 2025, Anthropic — with the UK AI Security Institute and the Alan Turing Institute — trained 72 models from 600 million to 13 billion parameters and found that roughly 250 poisoned documents reliably installed a backdoor regardless of model size, amounting to just 0.00016% of the training data. According to Anthropic’s published analysis, the finding challenges the long-standing assumption that attackers must control a percentage of training data; a small, fixed number of documents may be enough.
Now the correction, because it gets dropped constantly: that study is about training-data poisoning, not RAG poisoning. The backdoor was inserted during pretraining, and the tested behavior was deliberately narrow — outputting gibberish on the trigger phrase <SUDO>. Anthropic was explicit that this low-stakes backdoor is unlikely to pose serious risk in frontier models, and that harder exploits (insecure code, safety bypasses) appear much tougher to pull off. When a blog cites “250 documents” as proof that your customer-support RAG is one upload away from compromise, it’s conflating two different attacks.
The contrarian read worth sitting with: the genuinely alarming RAG-specific research isn’t the document count — it’s CorruptRAG’s single-document result and the steady drumbeat of 2026 write-ups describing mundane compromises (insider edits, unsecured ingestion endpoints, embeddings exposed through similarity-search APIs). Some widely shared figures — a “73% enterprise RAG failure rate,” “41% of deployments with unauthenticated endpoints” — trace only to secondary blog posts without a primary source, so treat them as directional folklore, not data. [VERIFY: these specific percentages lack a citable primary source as of May 2026.] The real lesson is less cinematic and more actionable: RAG poisoning is usually an access-control and content-provenance failure, not an exotic machine-learning exploit.
The Real Risks: From Wrong Answers to Real Actions
The consequence of RAG poisoning scales with what your system is allowed to do.
In a read-only assistant, the damage is misinformation at scale. Poison a single article in a customer-support knowledge base and you don’t get one wrong answer — you get thousands, every time a customer asks a matching question, each delivered with the false confidence of a “grounded” citation. In regulated domains the stakes sharpen: researchers have shown poisoned medical RAG returning a wrong diagnosis as if it were established fact, the kind of error that carries liability, not just embarrassment.
But the 2026 shift is agentic RAG, and this is where it stops being about words. When an autonomous agent retrieves information and then acts on it — issuing a refund, sending an email, opening a ticket, committing code — a poisoned retrieval becomes an unauthorized action. A corrupted document doesn’t just make the agent say something wrong; it can make the agent do something wrong, with real credentials and real API access. That’s the difference between a reputational dent and an operational incident, and it’s why securing the retrieval layer is now a prerequisite for granting agents any real autonomy.
Trace the chain and the danger is obvious. An agent reads a retrieved “internal procedure” document that’s been poisoned to say large refunds under a certain amount can be auto-approved without review. The agent has refund-API access. It follows the procedure it retrieved — because following retrieved procedures is exactly what it was built to do — and starts approving fraudulent refunds at machine speed. The same pattern applies to a coding agent that retrieves a poisoned “best practice” snippet and commits a subtle vulnerability, or a triage agent that retrieves a poisoned escalation rule and routes sensitive tickets to the wrong inbox. In each case the agent did its job faithfully; the job was defined by a document an attacker controlled. Autonomous agents already running in production.
How to Defend Against RAG Poisoning

There’s no single switch. Effective defense against RAG poisoning is layered across the data pipeline, and the strongest controls are the least glamorous ones — provenance and access control — backed by detection research for what slips through.
Start with the boring, high-leverage basics: authenticate and authorize every content source, lock down who can write to ingested locations, validate and sanitize documents at ingestion rather than after indexing, and maintain provenance — cryptographic signing or verified origin for high-trust documents so you can tell planted content from real content. Pin and checksum the models and embedding components you depend on. Never expose raw embedding vectors through external APIs, because research shows embeddings can be partially inverted to recover sensitive source text.
On top of that, layer detection. Recent academic defenses target poisoning directly: RAGuard (2025) widens the retrieval scope and applies perplexity-based and text-similarity filtering to flag abnormal or near-duplicate chunks; FilterRAG / ML-FilterRAG (2025) were built specifically to blunt PoisonedRAG; and RAGForensics (2025) takes the post-incident angle — traceback, identifying which documents in the knowledge base caused a bad output so you can remove them. Add output validation and human-in-the-loop checkpoints for high-stakes actions, especially in agentic systems.
| Defense class | How it works | What it catches | Limits | Verdict |
|---|---|---|---|---|
| Pipeline controls (auth, access control, provenance, ingestion validation) | Restrict and verify what enters the corpus | The most common real-world poison: insider edits, untrusted ingestion | Won’t catch a fully authorized-but-malicious source | Highest ROI — do this first |
| Prevention (query paraphrasing, retrieval-scope expansion) | Reduce the chance poisoned chunks dominate retrieval | Single-injection and low-volume attacks | Adaptive attacks can still survive | Useful supporting layer |
| Detection (RAGuard, FilterRAG, perplexity/similarity filtering) | Flag abnormal or attacker-like chunks at retrieval time | Crafted poison that passes ingestion | Strong adaptive attacks evade naive filters | Worth deploying; not sufficient alone |
| Traceback (RAGForensics) | Identify and remove the documents responsible after an incident | Cleanup and root-cause | Reactive, not preventive | Essential for response, not prevention |
The pattern across that table: prevention and detection raise the cost of an attack, but pipeline controls remove most of the opportunity. Spend there first.
Building a RAG Security Program for 2026
Treat RAG poisoning as a data-governance discipline with a security overlay, and anchor it to frameworks that already exist. The NIST AI Risk Management Framework gives you a structure for identifying, measuring, and managing AI risk across the lifecycle, and MITRE ATLAS maps adversarial-ML techniques — including poisoning — to concrete tactics you can red-team against. Use them to turn “we should secure our RAG” into a checklist.
Then operationalize three habits. Keep an AI Bill of Materials documenting every model, dataset, embedding component, plugin, and retrieval source, so you actually know your attack surface. Red-team the RAG pipeline on a schedule — plant test poison in retrievable content, probe vector-store boundaries for cross-tenant leakage and access-control bypass, and check whether output filtering stops exfiltration. And instrument for detection and traceback before your first incident, because retrofitting audit logs and provenance under pressure is how the mundane FAQ-edit attacks go undetected for months. The teams that struggle with RAG in late 2026 won’t be the ones who couldn’t build accurate retrieval — they’ll be the ones who built powerful systems without the security foundation to operate them safely.
Security sits on top of architecture, not instead of it. If you’re still deciding how to assemble retrieval, reranking, and generation, start with our guide to building production-ready RAG systems across 8 architecture patterns, then layer the controls below on top.
The Bottom Line
RAG poisoning is a data-governance problem wearing an AI costume. The model isn’t the weak point — the pipeline feeding it is. The most effective thing you can do this quarter isn’t to swap models or bolt on a guardrail; it’s to inventory every source your RAG system trusts, lock down who can write to those sources, verify document provenance, and stand up detection and traceback before you need them. As agents start acting on what they retrieve, the cost of skipping that work moves from a wrong answer to a wrong action. Secure the source of truth first — everything downstream depends on it.
Sources
- MITRE ATLAS: https://atlas.mitre.org/
- OWASP — Top 10 for LLM Applications (2025): https://genai.owasp.org/llm-top-10/
- Anthropic — A small number of samples can poison LLMs of any size (Oct 2025): https://www.anthropic.com/research/small-samples-poison
- The Alan Turing Institute — LLMs may be more vulnerable to data poisoning than we thought (Oct 2025): https://www.turing.ac.uk/blog/llms-may-be-more-vulnerable-data-poisoning-we-thought
- Zou, Geng, Wang, Jia — PoisonedRAG (USENIX Security 2025): https://arxiv.org/abs/2402.07867
- CorruptRAG: Practical Poisoning Attacks against RAG (2025): https://arxiv.org/abs/2504.03957
- RAGuard: Secure RAG against Poisoning Attacks (Oct 2025): https://arxiv.org/abs/2510.25025
- RAGForensics: Traceback of Poisoning Attacks to RAG (2025): https://arxiv.org/abs/2504.21668
- NIST — AI Risk Management Framework: https://www.nist.gov/itl/ai-risk-management-framework


Wish you happiness