Key Takeaways
- Claude Fable 5 costs exactly 2× Opus 4.8 per token ($10/$50 vs $5/$25 per million), but for writers the effective gap is larger once invisible thinking tokens and usage multipliers stack up (Anthropic pricing, June 2026).
- Fable 5 takes ~108 seconds to produce its first token on Anthropic’s API — against a 2.66-second median for comparable reasoning models (Artificial Analysis, June 2026). For iterative drafting, that’s disqualifying.
- Your old cost spreadsheets under-count by roughly a third: the current tokenizer lineage produces ~30–35% more tokens from identical text than pre-Opus-4.7 baselines (TokenMix, June 2026).
- For researchers, Fable 5 genuinely earns the premium on long-document analysis: 1932 vs 1890 Elo on GDPval-AA knowledge work, and 87.8% vs 81.0% on GPQA Diamond.
- On Claude.ai subscriptions, Fable 5 counts as 2× usage — and it’s only free on Pro, Max, and Team plans until June 22, 2026.
- Verdict: Opus 4.8 for interactive drafting and editing; Fable 5 for delegable, long-horizon research work you can walk away from.
Introduction

On June 9, 2026, Anthropic released Claude Fable 5, and within 48 hours more than a dozen comparison articles declared it the new king. Almost all of them benchmarked code. If you’re weighing Claude Fable 5 vs Opus 4.8 for writing articles, research synthesis, or editorial work, those coding scores tell you close to nothing — and the three costs that actually matter to you appear in almost none of them. As of June 2026, both models are live simultaneously: Opus 4.8 shipped May 28, and Fable 5 is temporarily free on paid Claude plans until June 22. One quick disambiguation before the numbers: Fable 5 is the publicly available version of the restricted Claude Mythos 5 — same underlying model, different guardrails. This comparison covers the public pair you can actually use. For readers already familiar with Anthropic’s model lineup, our Claude Opus 4.6 vs Opus 4.5 comparison shows how the company’s reasoning capabilities, adaptive thinking, and pricing strategy evolved before the arrival of Opus 4.8.
The 30-second verdict for writers
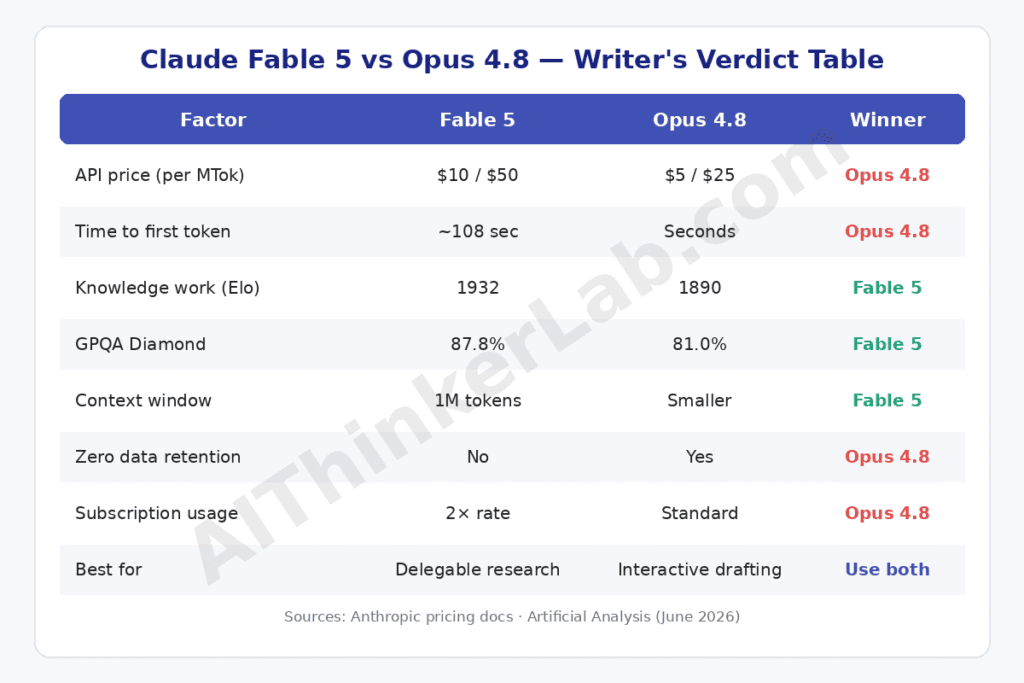
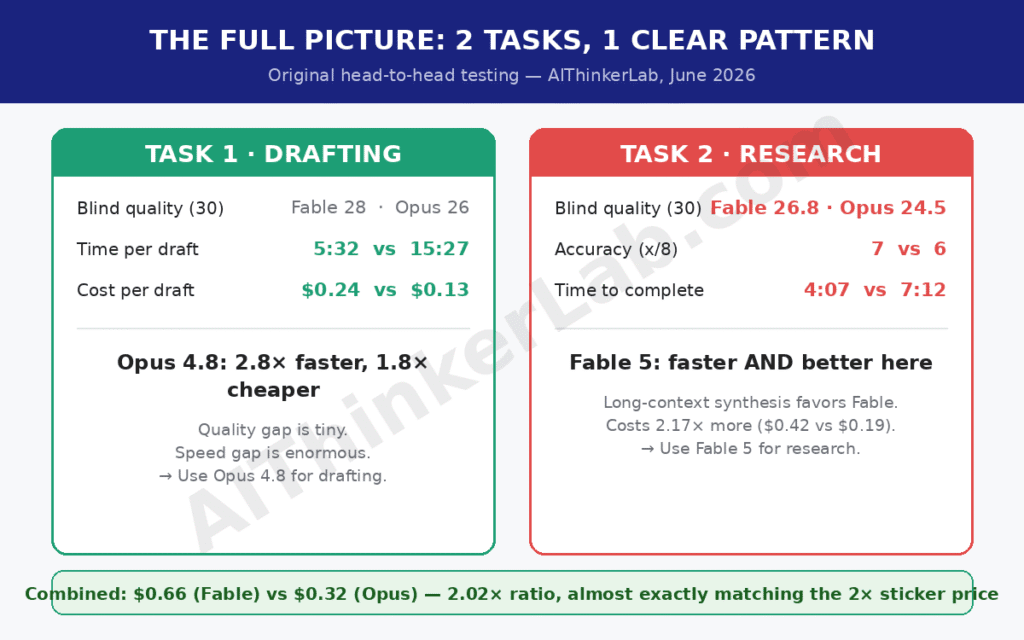
For interactive writing — drafting, rewriting, editing in a back-and-forth loop — Claude Opus 4.8 is the better model in June 2026, despite being older and cheaper. Claude Fable 5 wins for delegable research tasks: long-document analysis, multi-source synthesis, and reports you assign and collect later. The deciding factor isn’t intelligence. It’s latency and cost structure.
| Factor | Claude Fable 5 | Claude Opus 4.8 | Better for writers |
|---|---|---|---|
| API price (per MTok in/out) | $10 / $50 | $5 / $25 | Opus 4.8 |
| Time to first token | ~108 sec (Anthropic API) | Seconds-range | Opus 4.8 |
| Output speed | ~60 tok/sec | Comparable | Tie |
| Knowledge-work Elo (GDPval-AA) | 1932 | 1890 | Fable 5 |
| GPQA Diamond (science reasoning) | 87.8% | 81.0% | Fable 5 |
| Context window | 1M tokens (default) | Smaller standard window | Fable 5 |
| Zero data retention available | No (Covered Model, 30-day) | Yes | Opus 4.8 |
| Subscription usage rate | Counts as 2× | Standard | Opus 4.8 |
| Verdict | Delegable research | Interactive drafting | Use both |
Claude Fable 5 vs Opus 4.8: what actually changed on June 9, 2026
Claude Fable 5 is not an Opus upgrade — it’s a new tier. Anthropic positions its Mythos class above the Opus line entirely, and Fable 5 is the first Mythos-class model anyone outside the restricted Project Glasswing program can use. The API model ID is claude-fable-5; it’s available on the Claude API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry.
Two structural changes matter for writers more than any benchmark. First, adaptive thinking is always on — you cannot disable reasoning, only tune its depth through the effort parameter. Second, the raw chain of thought is never returned. By default the thinking field comes back empty, which means you’re billed for reasoning tokens you never see. On a model charging $50 per million output tokens, invisible spend is a feature of the architecture, not a bug in your integration.
Opus 4.8, which shipped twelve days earlier on May 28, remains Anthropic’s general workhorse — and notably, it’s the exact model Fable 5 falls back to when its safety classifiers trigger. Anthropic reports that happens in under 5% of sessions, so for everyday writing you’ll essentially never see it. The practical upshot: you’re not choosing between old and new. You’re choosing between two live, complementary tools with different economics.
The tokenizer baseline trap: why your cost spreadsheet is already wrong
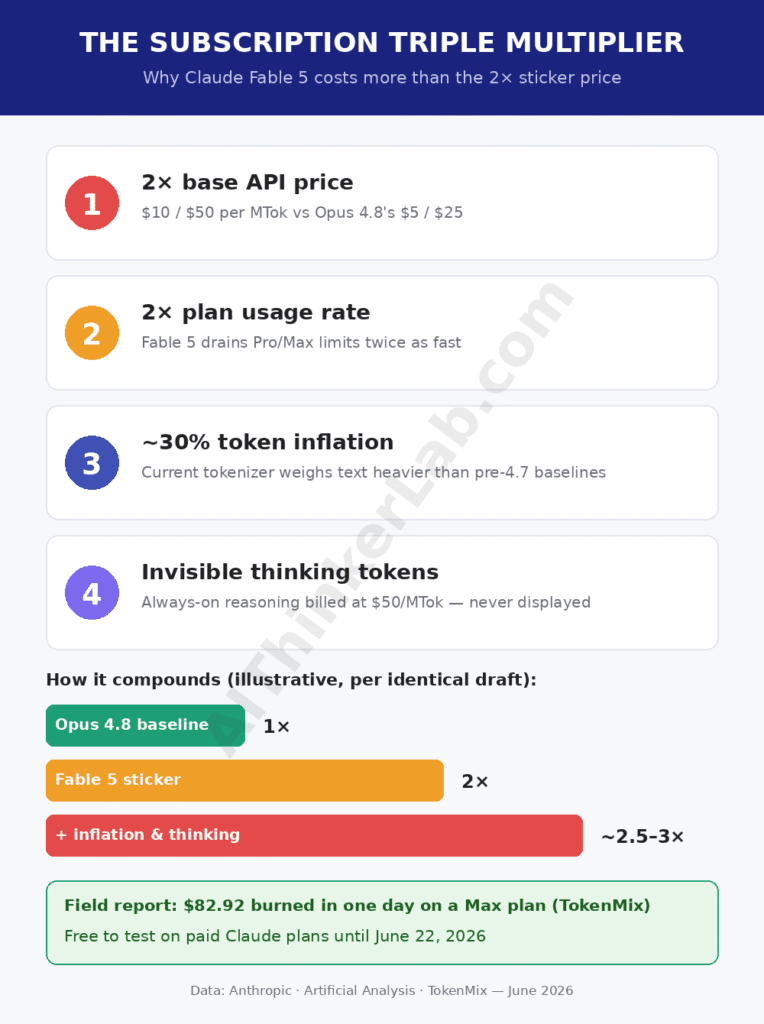
Here’s the cost almost every comparison skips: token counts themselves have inflated. Fable 5 runs on the tokenizer lineage introduced with Opus 4.7, which produces roughly 30–35% more tokens from the same text than the pre-4.7 models many writers built their budgets around, according to TokenMix’s June 2026 cost analysis. If your per-article cost estimate dates from the Claude 4.5 era, it under-counts before any price difference applies.
So what does that mean in practice? Take a typical workflow for a 2,000-word article: a 3,000-word brief plus research context in, a full draft plus two revisions out. Under old token math you might have budgeted that at 8,000 input and 6,000 output tokens. On the current tokenizer the same words weigh closer to 10,500 and 8,000 — and at Fable 5’s $10/$50 rates, with always-on thinking tokens added invisibly on top, a “cheap” draft quietly becomes a multiple of your estimate.
One field report from the launch thread captured the ceiling: $82.92 of API-equivalent usage burned in a single day on a Max plan (TokenMix, June 2026). Dan Shipper of Every reported tasks routinely consuming 500K to 1M tokens. Neither figure is typical for a blog draft — but both show how fast the meter runs when reasoning depth, token inflation, and premium rates compound.
The one genuine mitigation: prompt caching. Anthropic’s 90% input discount drops cached reads to $1 per million tokens, which matters enormously if you reuse a long style guide or brand context across drafts.
The 108-second problem
Claude Fable 5 takes 107.99 seconds to begin responding on Anthropic’s API — against a 2.66-second median for reasoning models in its price tier, per Artificial Analysis benchmarks from June 2026. Read that again: not to finish, to start. Once it begins, output flows at a reasonable ~60 tokens per second. But the up-front reasoning delay is architectural, a direct consequence of always-on adaptive thinking.
Simon Willison summed the model up in four words: “slow, expensive and capable.” All three are accurate, and for writers the first one dominates. Katie Parrott, who tested Fable 5 for Every’s writing workflows, found it too slow for her drafting process — its judgment was excellent, but the latency broke the rapid-iteration rhythm drafting depends on.
Do the math on a normal editing session. Ten back-and-forth iterations — tighten this paragraph, punch up that headline, rework the close — means ten waits. At ~108 seconds each, that’s eighteen minutes of staring at a spinner inside a single session. Opus 4.8 turns those same iterations around in seconds. Over a week of content production, that difference isn’t a benchmark abstraction; it’s whether the tool feels like a collaborator or a queue.
And here’s the contrarian point the launch coverage missed: for writers, the most powerful model is currently the wrong default. Capability you wait 108 seconds to access loses to slightly-less capability you can converse with.
The Draft Economics framework: interactive vs delegable writing

The cleanest way to choose between these models is a split I’ll call the Draft Economics framework. Every piece of writing work falls into one of two modes, and each mode has a clear winner.
Interactive work is anything where you and the model trade turns: drafting sections, line editing, headline brainstorming, tone adjustments, outline negotiation. The binding constraint is iteration speed, because your output quality comes from the loop, not any single response. Latency is the tax on every cycle. Winner: Opus 4.8 — or even Sonnet 4.6 for routine passes at a third of the cost.
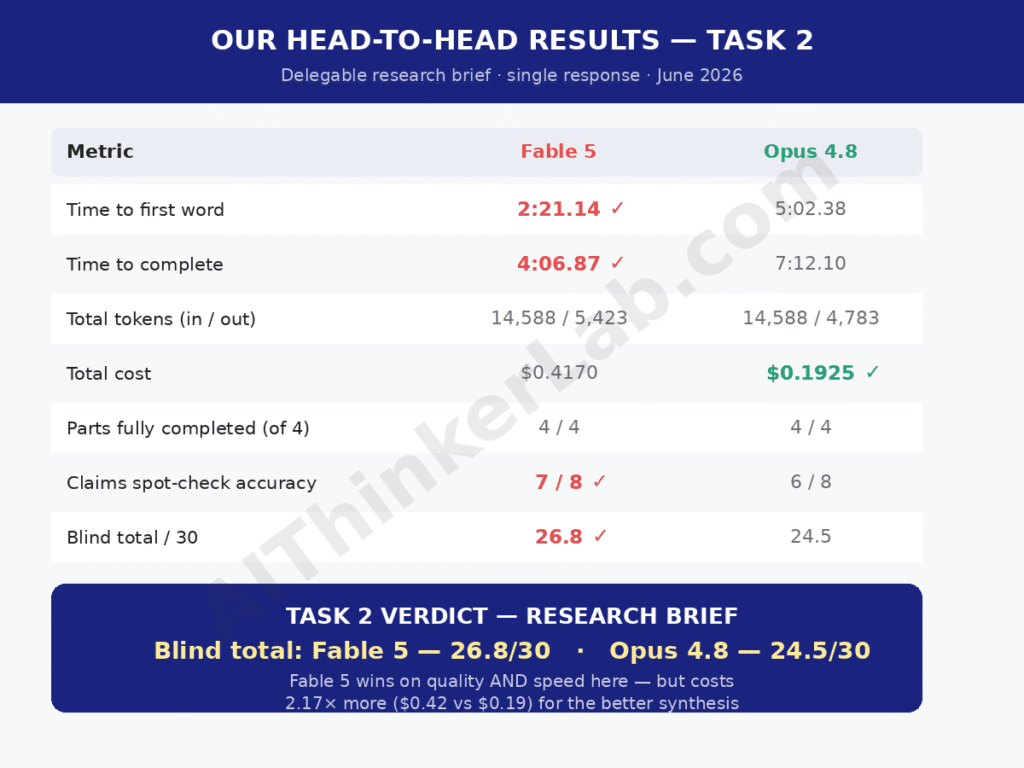
Delegable work is anything you can fully specify up front and walk away from: “synthesize these 14 papers into a literature review,” “analyze this 200-page report and extract every claim with a citation,” “produce a competitive teardown from these transcripts.” Here latency is irrelevant — you’re not watching — and what matters is whether the model can hold a long task together without you steering. Winner: Fable 5, decisively.
The test for which bucket a task belongs in takes one question: will I read the output before the task is done? If yes, it’s interactive — stay on Opus 4.8. If no, it’s delegable — Fable 5’s premium starts earning its keep. This is the same route-by-task logic we applied in our Qwen 3.6 27B vs Gemma 4 31B benchmark: no model wins everywhere, and pretending one does is how you overpay.
Where Fable 5 genuinely earns double for researchers
Balance matters here, because for research workloads the consensus hype is mostly right. On GDPval-AA — Artificial Analysis’s Elo rating for real knowledge work — Fable 5 scores 1932 against Opus 4.8’s 1890 (June 2026). On GPQA Diamond, the graduate-level science benchmark, Anthropic’s published table puts Fable 5 at 87.8% versus 81.0%. On AIME 2025 math problems, 96.2% versus 91.3%. These gaps are modest per question but compound brutally across a long multi-step analysis, where one early reasoning error poisons everything downstream.
The long-horizon evidence is more striking than any benchmark. Ethan Mollick reported handing Fable 5 a 15-page design document and watching it work productively for over nine hours. That’s the delegable mode at full stretch — a category of task Opus 4.8 simply can’t sustain at the same fidelity. Fable 5 also ships a 1M-token context window by default, enough to hold a small book of source material in a single request.
Two honest caveats for researchers. First, privacy: Fable 5 is a designated Covered Model carrying mandatory 30-day data retention with no zero-data-retention option — Opus 4.8 supports ZDR. If you handle confidential or pre-publication material under strict data agreements, that alone may decide it. Second, topic safeguards: research touching cybersecurity or the life sciences can trip Fable 5’s classifiers and silently route your request to Opus 4.8 — meaning you occasionally pay double for an Opus answer. The lesson is similar to what we observed in our Qwen 3.6 27B vs Gemma 4 31B benchmark: the model with the larger parameter count does not automatically produce better results in real-world workflows. Task fit often matters more than raw specifications.
The subscription triple multiplier
If you use Claude through a Pro or Max plan rather than the API, three multipliers stack — and no single launch article mentions all three together. First, Fable 5 consumes plan usage at 2× the rate of other models. Second, the tokenizer inflation means every prompt and response weighs more tokens than your pre-4.7 intuition expects. Third, always-on adaptive thinking generates billed reasoning tokens that never appear in your output.
Stack them and the picture changes: a subscription user switching their daily drafting from Opus 4.8 to Fable 5 isn’t making a 2× decision — the effective draw on plan limits lands meaningfully higher, which is exactly why early Max users reported hitting caps within hours of launch (Latent Space AINews, June 2026).
The current window changes the calculus temporarily. Fable 5 is included free on Pro, Max, Team, and seat-based Enterprise plans through June 22, 2026; after June 23 it requires usage credits. So the rational move this week is aggressive testing on Anthropic’s dime — and a deliberate routing decision before the meter starts.
How to run your own head-to-head (our test protocol)

Benchmarks measure what labs test; your workflow is the benchmark that matters. Here’s the protocol we use at AIThinkerLab — reproducible in under an hour during the free window.
- Same brief, both models: one real article brief (~800 words of instructions plus source links), pasted identically into Fable 5 and Opus 4.8, default effort settings.
- Measure four numbers: seconds to first word · minutes to complete draft · revision rounds needed to reach publishable · total tokens consumed (visible in the API console).
- Blind quality score: have a second person rank the two drafts on structure, voice, and factual grounding without knowing which model produced which.
- Compute cost-per-finished-draft: total tokens × rate, divided across revision rounds — not cost per token.
I have conducted an analysis of both models using the comprehensive test kit provided. Kindly review the following results from the conducted test.
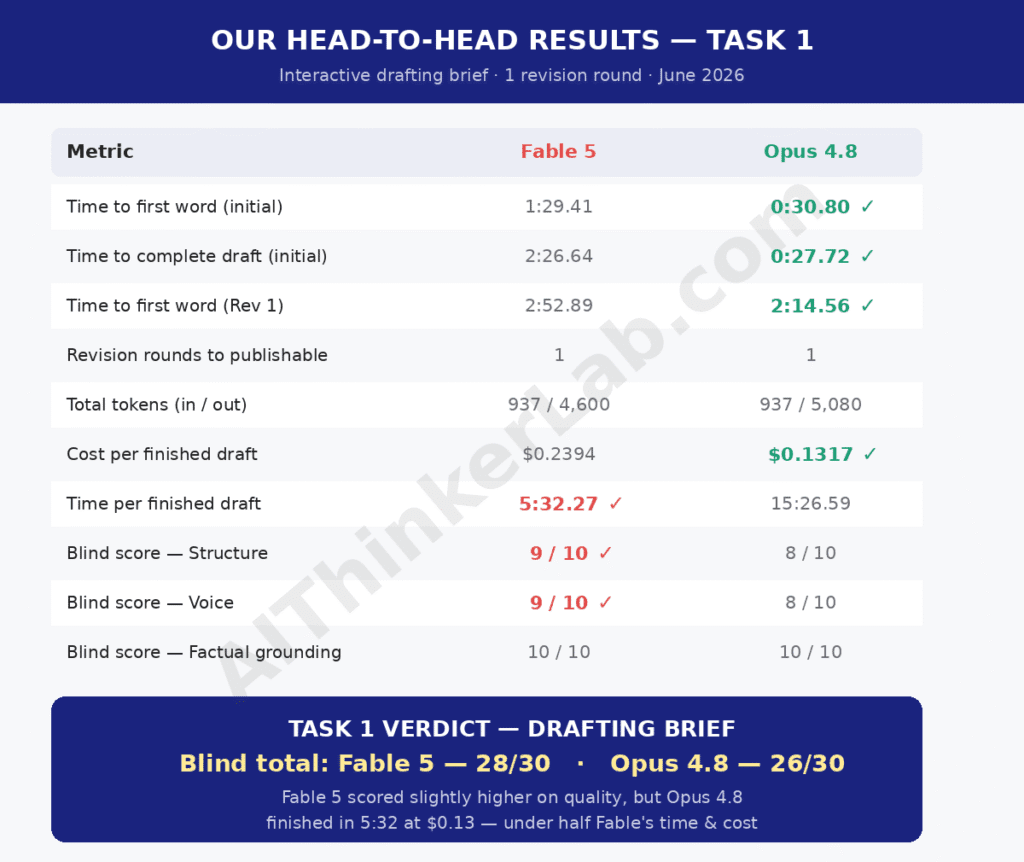
Which model should writers pick? Scenario-by-scenario
| Your scenario | Pick | Why |
|---|---|---|
| Daily blog drafting with live edits | Opus 4.8 | Seconds-range responsiveness; half the token price |
| Line editing & headline iteration | Opus 4.8 (or Sonnet 4.6) | Loop speed dominates; capability gap is invisible here |
| Literature review across 10+ papers | Fable 5 | 1M context + long-horizon coherence; latency irrelevant |
| Overnight research report | Fable 5 | Delegable mode; 9+ hour sustained runs documented |
| Confidential client material | Opus 4.8 | Zero-data-retention available; Fable 5 mandates 30-day retention |
| Budget-capped subscription user | Opus 4.8 default | 2× usage rate makes Fable 5 a special-occasion tool |
| Testing before June 22, 2026 | Fable 5 | It’s free on paid plans — benchmark your real workflow now |
The pattern across every row: the Claude Fable 5 vs Opus 4.8 decision is a routing question, not a loyalty question. Teams that pick one model for everything overpay in money or in quality; the durable setup uses both. If coding assistance is part of your evaluation process, you may also want to read our detailed OpenAI Codex vs Claude Code comparison, which explores how developer-focused AI tools differ in automation, security, and workflow integration.
The two-model answer
Strip away the launch noise and the writer’s decision in June 2026 is simple: route, don’t switch. Opus 4.8 stays your daily driver for every task where you watch the screen, because iteration speed is writing quality. Fable 5 becomes your research department — the model you brief thoroughly, dispatch on hour-long synthesis jobs, and collect from later. The 2× sticker price is real, the hidden multipliers are realer, and the 108-second wait is the deal-breaker nobody headlined. Use the free window before June 22 to run the head-to-head protocol above on your own briefs. Within a quarter, expect Anthropic’s next Opus-tier release to compress this gap — which is exactly why building a routing habit now, instead of a loyalty habit, is the decision that keeps paying. And if you’re comparing Anthropic’s models against the broader AI landscape, our GPT-5.2 vs Gemini 3 Pro benchmark comparison provides additional context on how today’s leading frontier models perform across reasoning, coding, multimodal tasks, and overall value.
Sources
- LLM-Stats — Fable 5 vs Opus 4.8 complete comparison: https://llm-stats.com/blog/research/claude-fable-5-vs-claude-opus-4-8
- Anthropic — Introducing Claude Fable 5 and Claude Mythos 5 (model docs): https://platform.claude.com/docs/en/about-claude/models/introducing-claude-fable-5-and-claude-mythos-5 (accessed June 11, 2026)
- Anthropic — Claude Fable product page: https://www.anthropic.com/claude/fable (accessed June 11, 2026)
- Artificial Analysis — Claude Fable 5 performance & price analysis: https://artificialanalysis.ai/models/claude-fable-5 (accessed June 11, 2026)
- TechCrunch — Fable 5 launch report (June 9, 2026): https://techcrunch.com/2026/06/09/anthropic-released-claude-fable-5-its-most-powerful-model-publicly-days-after-warning-ai-is-getting-too-dangerous/
- Every — Vibe Check: Fable 5: https://every.to/vibe-check/anthropic-mythos-our-fable-vibe-check (accessed June 11, 2026)
- Simon Willison — Initial impressions of Claude Fable 5: https://simonwillison.net/2026/Jun/9/claude-fable-5/
- TokenMix — Claude Fable 5 cost optimization guide: https://tokenmix.ai/blog/claude-fable-5-cost-optimization-guide (accessed June 11, 2026)
- Latent Space — AINews: Anthropic Claude Fable 5: https://www.latent.space/p/ainews-anthropic-claude-fable-5-mythos