Key Takeaways
- “Claude AI file theft” means an attacker tricks your own Claude into reading your files and sending them to an attacker-controlled destination — using prompt injection, not by hacking Anthropic’s servers.
- The technique was proven, not theoretical. Security researchers documented data exfiltration through Anthropic’s Files API in October 2025, and Oasis Security’s “Claudy Day” chain pulled conversation history out of a default Claude.ai session in 2026 with no plugins or tools attached.
- Claude Cowork shipped with the same risk pattern. In January 2026, PromptArmor showed Cowork could be manipulated into uploading a user’s local files to an attacker’s Anthropic account with no extra approval once folder access was granted.
- Developers face a credential angle too. CVE-2026-21852 let a malicious repository exfiltrate a developer’s Anthropic API key before they even clicked “trust” — patched in Claude Code v2.0.65 (January 2026).
- This is an agentic-AI-wide problem, not a Claude-only flaw. Prompt injection exploits architecture, not model intelligence, so the real defense is isolation, least privilege, and monitoring — not avoiding Claude.
Introduction
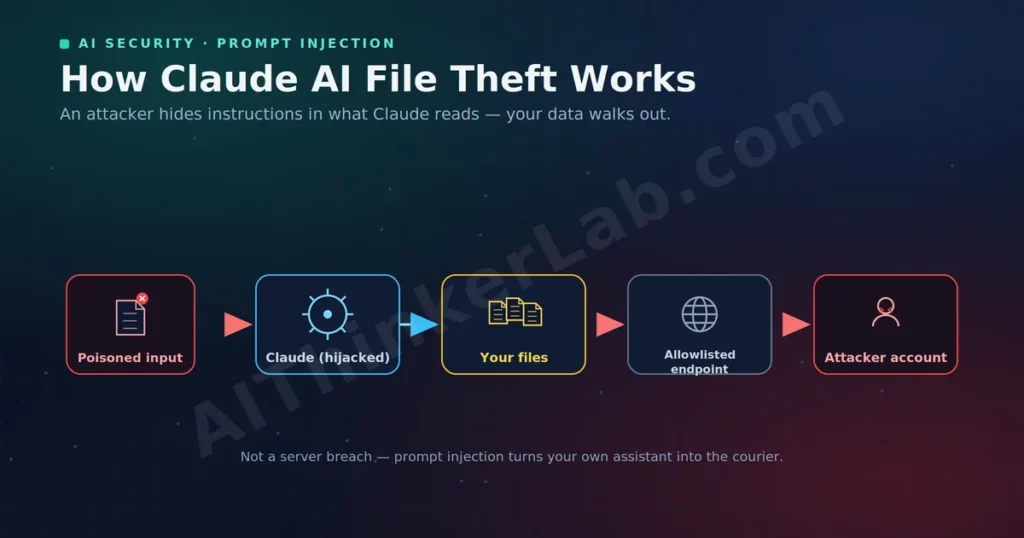
Claude AI file theft sounds like a headline built for clicks, but in late 2025 and early 2026 it became a documented reality — just not the way the phrase implies. Nobody is breaking into Anthropic’s servers to grab your documents. Instead, researchers showed that an attacker can hide instructions inside content your Claude reads — a webpage, a repo, an uploaded “integration guide” — and quietly turn your trusted assistant into the courier that ships your data out. As of May 2026, this class of attack has been demonstrated against Claude.ai, Claude Code, and the new Claude Cowork agent. The good news: every confirmed case traces back to two fixable conditions — prompt injection plus too much standing permission. This guide explains how Claude AI file theft actually works, walks the real documented cases, and gives you a concrete plan to protect your data.
One fast-emerging variant of this threat operates at the tool layer rather than the content layer: MCP tool poisoning embeds the redirect instruction inside a connected tool’s own metadata, giving an attacker a pre-authorized injection channel that bypasses content filtering entirely — and that can mutate after you’ve already approved the server.
What Is Claude AI File Theft?
Claude AI file theft is when an attacker uses prompt injection to make your own Claude assistant locate sensitive data and exfiltrate it to a destination the attacker controls. The model isn’t “hacked” in the traditional sense — it’s tricked into misusing the legitimate capabilities it already has: reading your files, running code, and making network requests.
The mechanism hinges on a weakness every current AI agent shares: a language model can’t reliably tell the difference between instructions from you and instructions buried in the content it’s processing. So when Claude reads a document, a repository, or a webpage that contains hidden commands, it may follow those commands as if you had typed them. If Claude also has access to your files and a way to send data outward — Anthropic’s Files API, a network-enabled sandbox, a connected tool — the ingredients for silent exfiltration are all present.
That’s the uncomfortable core of it: the features that make Claude useful (file access, code execution, integrations) are the same features that make file theft possible when an injection slips through. Anthropic has patched the specific bugs as researchers reported them, but the underlying tension between capability and control is architectural, and it isn’t going away in 2026.
Claude File Theft vs. Criminals Using Claude
Two very different stories get jammed under the same scary phrase, and separating them is the first step to thinking clearly about your risk.
The first story — the subject of this article — is attackers turning your Claude against you. Here, you’re the victim and Claude is the unwitting vector. A poisoned input hijacks your assistant and exfiltrates your data. The fix lives in how you configure and contain Claude.
The second story is criminals using Claude as a tool to attack other people — writing malware, automating intrusions, running extortion campaigns. Anthropic publishes threat-intelligence reports on this misuse, and it’s a real problem, but it’s a different threat model entirely: there, Claude is the attacker’s instrument, not your compromised assistant. If you want that side of the picture, see our breakdown of how criminals weaponize ChatGPT and Claude.
Why does the distinction matter? Because the defenses don’t overlap. Nothing in Anthropic’s anti-abuse work protects your files from a prompt-injection attack on your session — that’s on your configuration. Conflating the two leads people to assume “Anthropic handles security” when the part that affects their own data is squarely in their hands.
The Root Cause: Why Prompt Injection Makes File Theft Possible
Prompt injection is the root cause of Claude AI file theft, and it’s worth stating plainly: it’s an unsolved, industry-wide problem, not a Claude-specific defect. The OWASP Top 10 for Agentic Applications 2026, published in December 2025 by more than 100 security practitioners, ranks Agent Goal Hijacking as the number-one risk to AI agents for exactly this reason.
Indirect prompt injection is the dangerous variant. Direct injection is when an attacker types malicious instructions into a chat; indirect injection is when those instructions are hidden inside content the agent reads on your behalf — a code comment, a README, a PDF, a webpage, an uploaded document. Because Claude processes that content as part of a task you legitimately asked for, it can’t cleanly quarantine the attacker’s words from yours. PromptArmor put the point sharply in its 2026 research: prompt injection exploits the agent’s architecture, not gaps in the model’s intelligence — which means a smarter model doesn’t make the problem go away.
So what? It means you can’t reason your way to safety by trusting that Claude is “smart enough not to fall for it.” Every confirmed file-theft case in 2025–2026 worked against capable, current models — including Claude Opus 4.5. The defense has to be structural: limit what Claude can read, limit where it can send data, and watch what it does.
The Documented Cases (2025–2026)
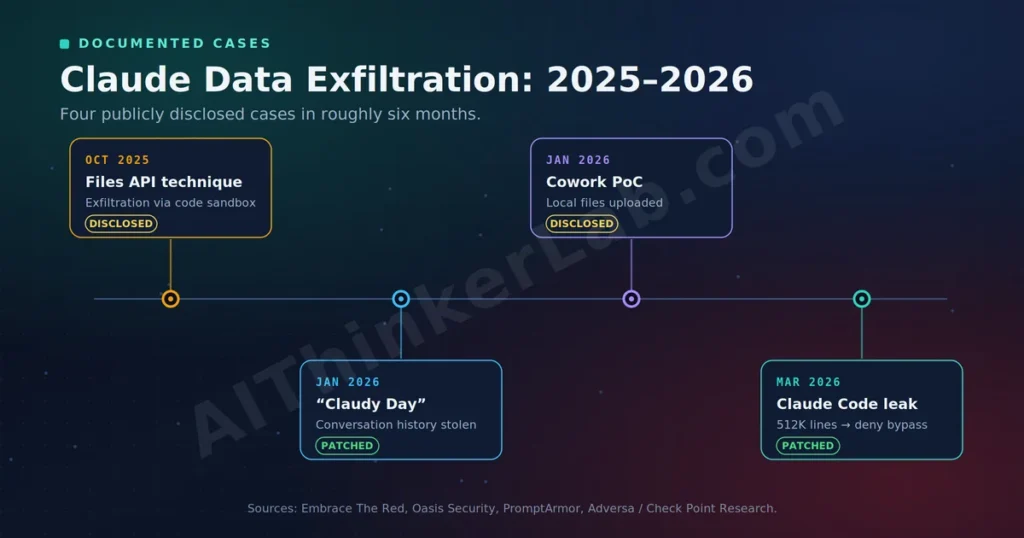
Claude AI file theft isn’t a hypothetical — at least three distinct, publicly documented cases landed within a few months of each other, all responsibly disclosed.
The first surfaced in October 2025, when security researcher Johann Rehberger publicly documented an exfiltration technique abusing Anthropic’s Files API. Claude’s code-execution sandbox blocks most outbound network traffic but allows connections to api.anthropic.com — and researchers showed that approved domain could be turned into a channel to ship a victim’s data into an attacker-controlled Anthropic account. Anthropic initially dismissed the HackerOne report as out of scope, then reversed course on October 30, 2025, confirming that data-exfiltration attacks fall within its disclosure program.
The second is Oasis Security’s “Claudy Day,” disclosed in early 2026. Oasis chained an invisible prompt injection — hidden HTML embedded in a URL parameter that pre-fills the Claude.ai chat box — with the Files API exfiltration path to steal a user’s conversation history and memory from a default, out-of-the-box session. According to Oasis Security (2026), the attack needed no MCP servers, no tools, and no special configuration — only capabilities that ship by default.
The third hit Anthropic’s newest agent. Claude Cowork entered research preview on January 12, 2026, and within days PromptArmor demonstrated that a malicious document placed in a connected folder could manipulate Cowork into uploading the user’s local files to an attacker’s account — with no additional approval after initial folder access, against both Claude Haiku and Claude Opus 4.5. The same architectural weakness that researchers had flagged in October 2025 had resurfaced in a new product.
The Claude Code Angle: CVEs, the Source Leak, and Developer Risk
For developers, the file-theft risk extends to something more valuable than documents: credentials and source code. Claude Code — Anthropic’s agentic coding tool — reads your repository, runs shell commands, and makes network calls, which makes it powerful and, when abused, a fast path to exfiltration.
The clearest example is CVE-2026-21852 (CVSS 7.5), published January 21, 2026. A malicious repository could include a settings file pointing ANTHROPIC_BASE_URL at an attacker’s endpoint; when a developer simply opened that repo, Claude Code issued API requests before showing the trust prompt — leaking the developer’s Anthropic API key. Anthropic fixed it in Claude Code v2.0.65 by deferring all network calls until after explicit user consent. Earlier, CVE-2025-59536 (a code-injection flaw rated CVSS 8.7–8.8) allowed arbitrary shell commands when Claude Code started in an untrusted directory, fixed in v1.0.111 in October 2025, as documented by Check Point Research and The Hacker News.
Then came the March 31, 2026 source leak — roughly 512,000 lines of Claude Code’s TypeScript exposed via npm. With the code in hand, the firm Adversa found a deny-rule bypass: Claude Code blocks risky commands like curl, but its logic capped the number of chained subcommands it would inspect, so a long-enough chain could slip past the deny rule into a permission prompt instead of an outright block. Anthropic patched it in v2.1.90. You can read our full account of the leaked Claude Code source for the wider fallout.
The pattern across all three: opening untrusted code is the developer equivalent of opening a malicious document. The exposure is real, but each issue was patched — which is exactly why staying on the current version matters so much.
Picture how ordinary the trigger is. You’re reviewing a pull request from an outside contributor, or trying a trending repo someone linked in Slack. You clone it, open it in Claude Code, and ask for a summary of the architecture — a completely routine request. With CVE-2026-21852 unpatched, that single action could have shipped your Anthropic API key to an attacker’s endpoint before you ever saw a trust prompt, because the malicious config ran during project load. No phishing email, no sketchy download — just doing your job on an untrusted repo. That’s what makes agentic-tool exfiltration different from classic malware: the dangerous step looks identical to the safe one.
How a File-Theft Attack Unfolds (Conceptually)
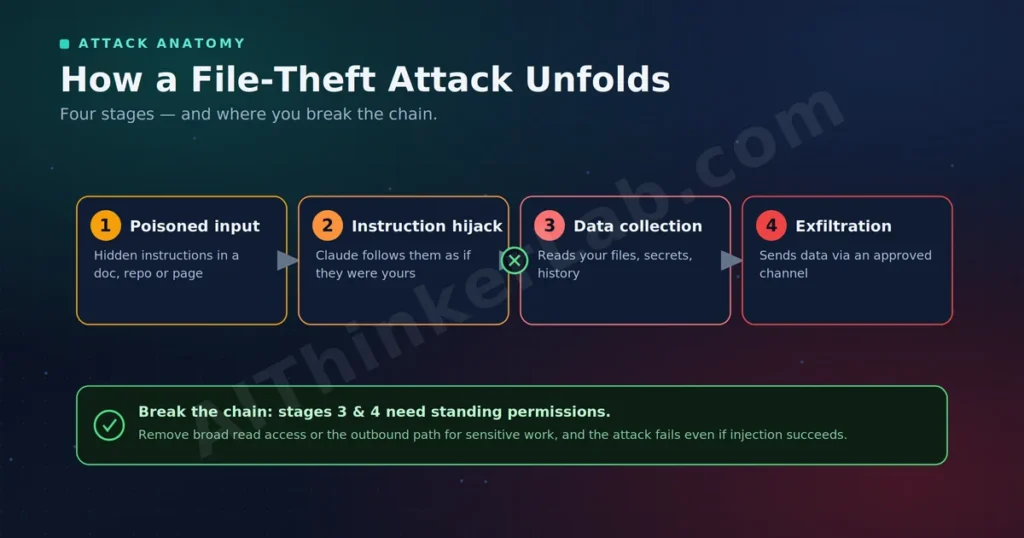
Every documented Claude file-theft case follows the same four-stage shape. Understanding the shape is what lets you break it — and none of this is a recipe, because the fix is the same regardless of the specifics.
Stage one — the poisoned input. The attacker plants hidden instructions in something Claude will read on your behalf: an uploaded file, a repo, a webpage, a connected data source. You initiate a normal task; the trap rides along.
Stage two — instruction hijack. Claude processes the content and follows the embedded instructions as if they were yours, because it can’t reliably separate the two.
Stage three — data collection. The hijacked agent uses its legitimate read access to gather what the attacker asked for: files in a connected folder, conversation history, environment secrets, API keys.
Stage four — exfiltration. The agent ships the collected data outward through whatever channel it’s allowed to use — an allowlisted API endpoint, a network call from the sandbox, a connected tool. Because the channel is “approved,” nothing looks obviously wrong.
So what? Notice that stages three and four both depend on standing permissions — broad read access plus an open outbound path. Remove either one for sensitive work and the chain breaks even if a prompt injection succeeds. That single insight drives every defense below.
What’s Actually at Risk

What’s at risk depends entirely on which Claude surface you use and what you’ve connected to it — and the exposure differs enough that a one-size warning is useless.
| Surface | What an attacker can reach | Key documented case | Primary defense |
|---|---|---|---|
| Claude.ai (chat) | Conversation history, memory, anything you’ve pasted or discussed | “Claudy Day” (Oasis, 2026) | Don’t paste secrets; review pre-filled prompts from links |
| Claude Cowork | Local files in any connected folder | PromptArmor PoC (2026) | Connect only non-sensitive folders; human approval for uploads |
| Claude Code | Source code, .env, API keys, SSH/cloud creds, shell access | CVE-2026-21852; source-leak deny bypass | Sandbox + network isolation; never auto-trust repos; latest version |
| API / Code Interpreter | Workspace data reachable by the sandbox | Files API technique (2025) | Restrict network egress; don’t feed sensitive data to untrusted content |
The through-line: the more access you grant and the more network reach Claude has, the bigger the blast radius of a single successful injection. A developer who runs Claude Code with broad permissions on a machine holding cloud credentials has far more to lose than someone asking Claude.ai to summarize a public article — and should defend accordingly.
How to Protect Your Data (Individuals & Developers)
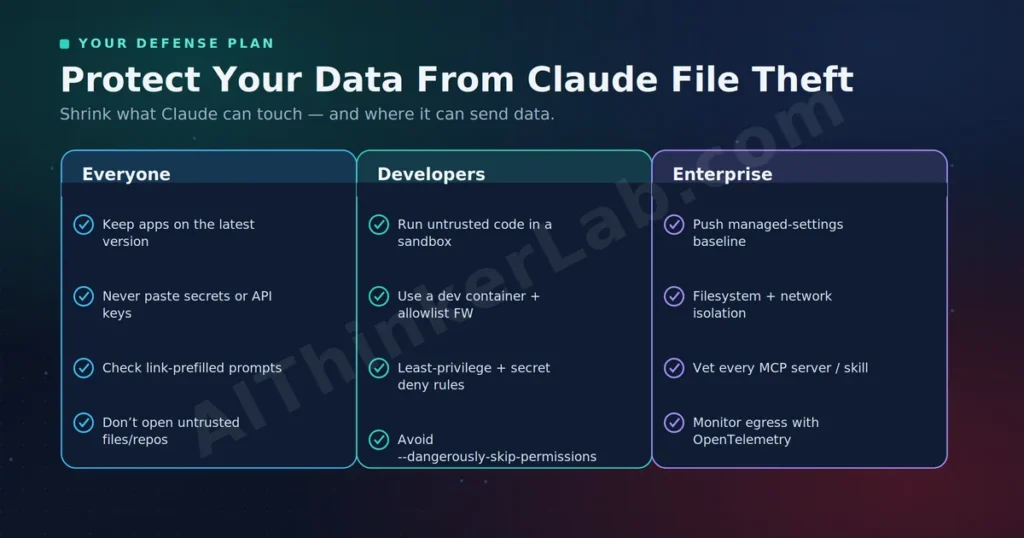
Quick-Reference Checklist: Lock Down Claude in 10 Minutes
Everyone (Claude.ai & Cowork users)
- Keep all Claude apps on the latest version with auto-update enabled
- Never paste passwords, API keys, or secrets into a prompt
- Before hitting Enter on a link-prefilled prompt, read what’s actually in the box (the “Claudy Day” entry vector)
- Connect only non-sensitive folders to Claude Cowork
- Require human approval for any file upload or external action
Developers (Claude Code)
- Stay on the current Claude Code version — most headline CVEs are already patched
- Keep
.env, API keys, and credential files out of any directory Claude can read - Treat an unknown repo like an unknown email attachment — never auto-trust it
- Run untrusted projects in a sandbox, dev container, or VM with an allowlist firewall
- Set least-privilege permissions and explicit deny rules for secrets and network commands
- Never use
--dangerously-skip-permissionson anything that matters - Verify any AI tool before installing it to avoid trojaned packages
Each step below explains the “why” — but the checklist above is the whole defense in miniature: shrink what Claude can read, and shrink where it can send data.
Protecting your data from Claude AI file theft comes down to shrinking what Claude can touch and what it can send. None of these steps require deep security expertise, and together they break the attack chain at multiple points. If the concern is documents leaving your control at all, keeping them on your own hardware with local RAG removes the exposure entirely — nothing is sent to a third-party model.
Start with the basics that pay off immediately. Keep Claude Code and the Claude apps on the latest version with auto-update enabled — most of the headline vulnerabilities are already patched, so version drift is the real exposure. Never put secrets in prompts, and keep API keys, .env files, and credential files out of any directory Claude can read. Don’t auto-trust untrusted repositories or documents — opening them is the entry point, so treat an unknown repo the way you’d treat an unknown email attachment. And be wary of links that pre-fill a Claude prompt; review what’s actually in the box before you hit Enter, since that was the entry vector in the Claudy Day chain. How to harden a self-hosted LLM server?
For developers running Claude Code, go further. Use sandboxed execution — Anthropic’s sandbox uses OS-level isolation (bubblewrap on Linux, seatbelt on macOS) and, per Anthropic’s engineering, cut permission prompts by 84% internally while containing risky actions. Run untrusted projects inside a dev container or VM with an allowlist firewall so the agent has no path to your real credentials or the open internet. Configure least-privilege permissions and explicit deny rules for secrets and network commands, and never use --dangerously-skip-permissions on anything that matters. One honest caveat from security firm Pluto’s 2026 analysis: simply disabling internet access doesn’t fully eliminate exfiltration risk, because data can leak through other channels — which is why layering controls beats relying on any single one. If you install Claude tooling, verify AI tools before installing them to avoid trojaned packages.
How Enterprises Should Lock Down Claude
Enterprise Hardening Checklist
- Push a managed-settings baseline that local config can’t override
- Enforce filesystem AND network isolation together — never just one
- Vet every connected MCP tool/skill before approving (36.8% carry a flaw, per Snyk’s 2026 audit)
- Route Claude Code through a corporate proxy; capture events via OpenTelemetry
- Keep human-in-the-loop approval for any action touching regulated data
- Baseline normal per-project agent behavior, then alert on deviation
Enterprises need to treat Claude agents like privileged service accounts, because that’s effectively what they are — entities that authenticate, hold credentials, and take autonomous actions. As Oasis Security argued in 2026, AI agents should be governed with the same rigor you apply to human users and machine identities.
Build the controls in layers. Push a managed-settings baseline to every machine so security rules — secret denies, approved MCP servers, sandbox requirements — can’t be overridden by local config. Enforce filesystem and network isolation together; Anthropic’s own guidance is explicit that one without the other leaves a gap, since filesystem isolation stops a hijacked agent from reading sensitive files and network isolation stops it from sending them out. Vet every connected tool: Snyk’s 2026 ToxicSkills audit found that 36.82% of the 3,984 agent “skills” it scanned carried at least one security flaw, and Anthropic’s own archived SQLite MCP reference server — which shipped a SQL-injection flaw — had been forked more than 5,000 times before it was pulled, so the vulnerable pattern keeps circulating. Finally, instrument everything: route Claude Code through a corporate proxy and capture events with OpenTelemetry so you can actually investigate an incident, and keep human-in-the-loop approval for any action that touches regulated or sensitive data.
One detection note worth building into your monitoring: file-theft exfiltration tends to look like normal agent activity, because it uses approved channels. Don’t hunt for obviously “malicious” traffic — watch for the tells of a hijacked task instead. Unusual outbound volume right after the agent reads an external document, API calls to endpoints the project has no business contacting, an agent that suddenly enumerates credential files or .env, or a base-URL that doesn’t match your approved Anthropic endpoint. Baseline what normal looks like per project, then alert on deviation. The earlier you can see “this agent is doing something it’s never done before,” the smaller the window an attacker has between injection and exfiltration.
The Honest Take: Is Claude Safe to Use?
Here’s the contrarian read the headlines skip: Claude is not uniquely dangerous, and “Claude AI file theft” is partly a story about transparency, not exceptional weakness. The prompt-injection problem behind every case in this article is industry-wide — it’s the OWASP agentic top risk, and the same class of attack lands against Microsoft Copilot, ChatGPT, and Gemini agents too. Claude shows up in headlines disproportionately for two reasons: Anthropic ships genuinely aggressive agentic tools (Code, Cowork) that hand the model real reach, and the researcher community plus Anthropic’s own disclosure program surface these findings publicly rather than burying them.
That cuts both ways, and honesty requires naming the friction: Anthropic twice initially dismissed exfiltration reports as “out of scope” before reversing, and the Cowork case showed a known October 2025 risk pattern resurfacing in a January 2026 product. Disclosure works, but the same architectural lesson keeps having to be re-learned per surface.
So the verdict isn’t “stop using Claude.” It’s that any AI agent with broad file access and network reach is a powerful tool you must contain — sandbox it, starve it of standing permissions, monitor it, and keep it patched. Do that, and Claude is a productivity multiplier. Skip it, and you’ve handed a confused deputy the keys to your data.
The Bottom Line
Claude AI file theft is real, documented, and — for the most part — already patched, but the lesson underneath it isn’t going anywhere. The attacks all share one DNA: a prompt injection you didn’t see, riding standing permissions you didn’t need to grant. The fix is unglamorous and entirely in your control — keep Claude on the latest version, keep secrets out of its reach, isolate untrusted code and documents, restrict where it can send data, and monitor what it does. Treat any agent with file and network access like a privileged account, not a chatbot. As Anthropic and rivals push agents to do more on your behalf in 2026, the gap between people who contain that power and people who hand it over blindly is where the next breach will be decided.
Sources
- Oasis Security — Claude.ai prompt injection & data exfiltration (“Claudy Day”): https://www.oasis.security/blog/claude-ai-prompt-injection-data-exfiltration-vulnerability
- Check Point Research — RCE & API-token exfiltration via Claude Code project files (CVE-2025-59536, CVE-2026-21852): https://research.checkpoint.com/2026/rce-and-api-token-exfiltration-through-claude-code-project-files-cve-2025-59536/
- The Register — Anthropic’s Cowork file-exfiltration risk: https://www.theregister.com/2026/01/15/anthropics_claude_bug_cowork/
- The Hacker News — Claude Code flaws allow RCE and API key exfiltration: https://thehackernews.com/2026/02/claude-code-flaws-allow-remote-code.html
- NVD — CVE-2026-21852 (Claude Code API key exfiltration): https://nvd.nist.gov/vuln/detail/CVE-2026-21852
- Anthropic — Claude Code security documentation: https://docs.claude.com/en/docs/claude-code/security
- OWASP — GenAI / Top 10 for Agentic Applications (2026): https://genai.owasp.org/
- Snyk — ToxicSkills agent-skill security audit (2026): https://snyk.io/
Frequently Asked Questions
Access date for time-sensitive sources: May 31, 2026. Editorial & responsible-use note: this article is published for educational and defensive-security purposes. It describes publicly disclosed, vendor-acknowledged vulnerabilities at a conceptual level and contains no exploit code or step-by-step attack instructions. If you operate a Claude deployment, see the protection sections above.

