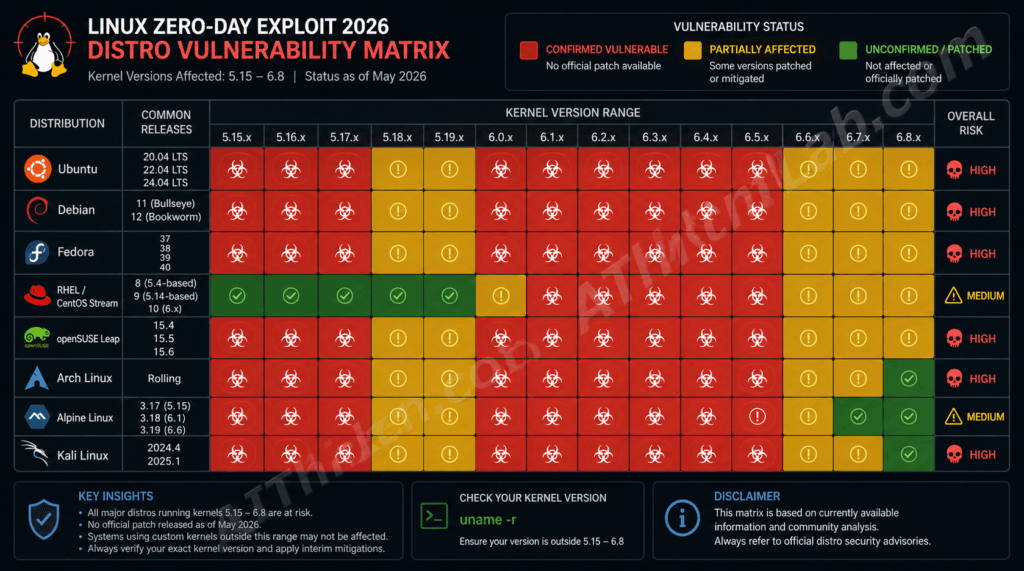
Linux Zero Day Exploit 2026: The 732-Byte Attack Hijacking Systems Before Any Patch Exists
Imagine waking up to find that your computer systems, once thought secure, have been compromised in the most elusive way possible. This is not just a tech enthusiast’s nightmare—it’s the reality of a new breed of cyber threats that have emerged. In 2026, a Linux zero-day exploit, a mere 732 bytes in size, is wreaking havoc across systems worldwide. It’s not just a test of technical prowess; it’s a race against time for security experts. Before any patch exists to mitigate the threat, this tiny yet potent attack vector is stealthily hijacking systems right under the radar.
The implications are staggering. For businesses, the compromise can mean financial loss, reputational damage, and breaches of confidential information. But what makes this exploit particularly insidious is its ability to bypass traditional defenses, leaving IT departments scrambling in a reactive stance. With zero-day exploits like this one, the stakes have never been higher. Understanding the mechanics and impact of such vulnerabilities isn’t just for cybersecurity professionals but crucial for anyone relying on digital ecosystems in today’s interconnected world. Prepare yourself as we delve into every facet of this alarming security saga.